 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unlikely Duel: Evaluating Creative Writing in LLMs through a Unique Scenario
Jun 22, 2024
This is a summary of the paper "A Confederacy of Models: a Comprehensive Evaluation of LLMs on Creative Writing", which was published in Findings of EMNLP 2023. We evaluate a range of recent state-of-the-art, instruction-tuned large language models (LLMs) on an English creative writing task, and compare them to human writers. For this purpose, we use a specifically-tailored prompt (based on an epic combat between Ignatius J. Reilly, main character of John Kennedy Toole's "A Confederacy of Dunces", and a pterodactyl) to minimize the risk of training data leakage and force the models to be creative rather than reusing existing stories. The same prompt is presented to LLMs and human writers, and evaluation is performed by humans using a detailed rubric including various aspects like fluency, style, originality or humor. Results show that some state-of-the-art commercial LLMs match or slightly outperform our human writers in most of the evaluated dimensions. Open-source LLMs lag behind. Humans keep a close lead in originality, and only the top three LLMs can handle humor at human-like levels.
* Published in the XIX Conference of the Spanish Association for Artificial Intelligence (CAEPIA), 2024. Summary of our paper "A Confederacy of Models: a Comprehensive Evaluation of LLMs on Creative Writing", published in Findings of EMNLP
A Confederacy of Models: a Comprehensive Evaluation of LLMs on Creative Writing
Oct 12, 2023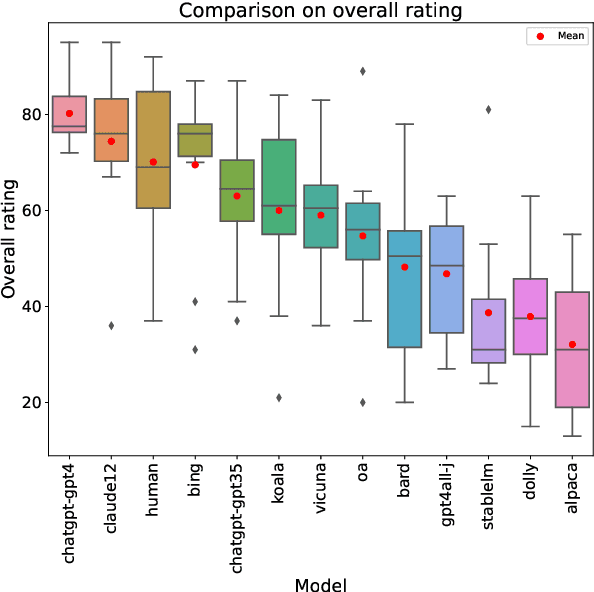

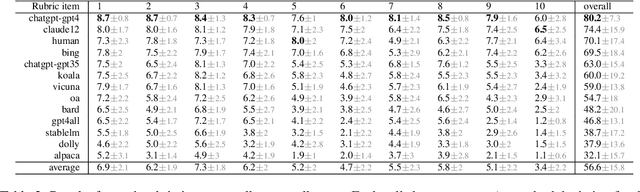
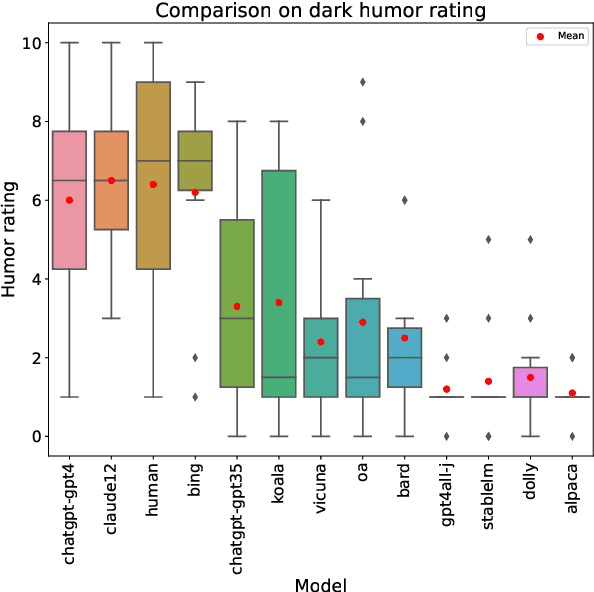
We evaluate a range of recent LLMs on English creative writing, a challenging and complex task that requires imagination, coherence, and style. We use a difficult, open-ended scenario chosen to avoid training data reuse: an epic narration of a single combat between Ignatius J. Reilly, the protagonist of the Pulitzer Prize-winning novel A Confederacy of Dunces (1980), and a pterodactyl, a prehistoric flying reptile. We ask several LLMs and humans to write such a story and conduct a human evalution involving various criteria such as fluency, coherence, originality, humor, and style. Our results show that some state-of-the-art commercial LLMs match or slightly outperform our writers in most dimensions; whereas open-source LLMs lag behind. Humans retain an edge in creativity, while humor shows a binary divide between LLMs that can handle it comparably to humans and those that fail at it. We discuss the implications and limitations of our study and suggest directions for future research.
Real-World Performance of Autonomously Reporting Normal Chest Radiographs in NHS Trusts Using a Deep-Learning Algorithm on the GP Pathway
Jun 28, 2023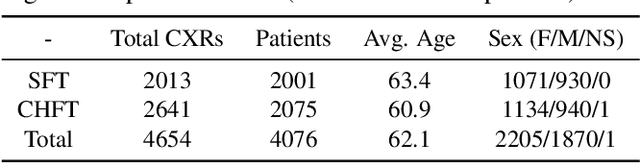
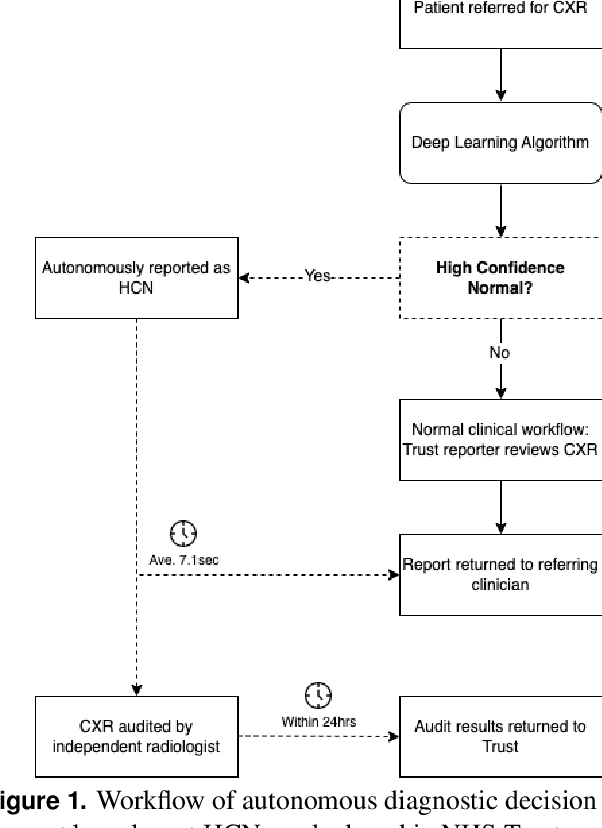
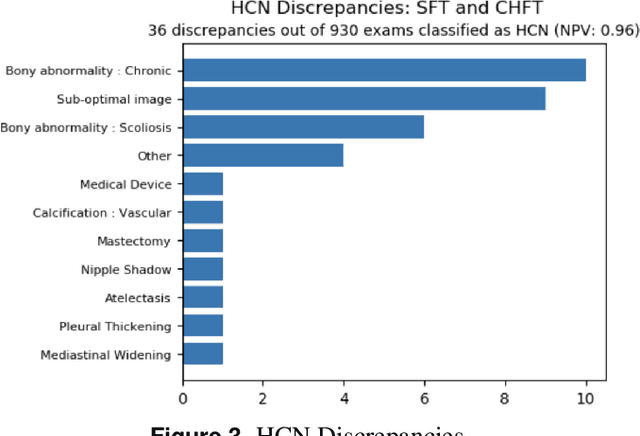
AIM To analyse the performance of a deep-learning (DL) algorithm currently deployed as diagnostic decision support software in two NHS Trusts used to identify normal chest x-rays in active clinical pathways. MATERIALS AND METHODS A DL algorithm has been deployed in Somerset NHS Foundation Trust (SFT) since December 2022, and at Calderdale & Huddersfield NHS Foundation Trust (CHFT) since March 2023. The algorithm was developed and trained prior to deployment, and is used to assign abnormality scores to each GP-requested chest x-ray (CXR). The algorithm classifies a subset of examinations with the lowest abnormality scores as High Confidence Normal (HCN), and displays this result to the Trust. This two-site study includes 4,654 CXR continuous examinations processed by the algorithm over a six-week period. RESULTS When classifying 20.0% of assessed examinations (930) as HCN, the model classified exams with a negative predictive value (NPV) of 0.96. There were 0.77% of examinations (36) classified incorrectly as HCN, with none of the abnormalities considered clinically significant by auditing radiologists. The DL software maintained fast levels of service to clinicians, with results returned to Trusts in a mean time of 7.1 seconds. CONCLUSION The DL algorithm performs with a low rate of error and is highly effective as an automated diagnostic decision support tool, used to autonomously report a subset of CXRs as normal with high confidence. Removing 20% of all CXRs reduces workload for reporters and allows radiology departments to focus resources elsewhere.
Enhancing Early Lung Cancer Detection on Chest Radiographs with AI-assistance: A Multi-Reader Study
Aug 31, 2022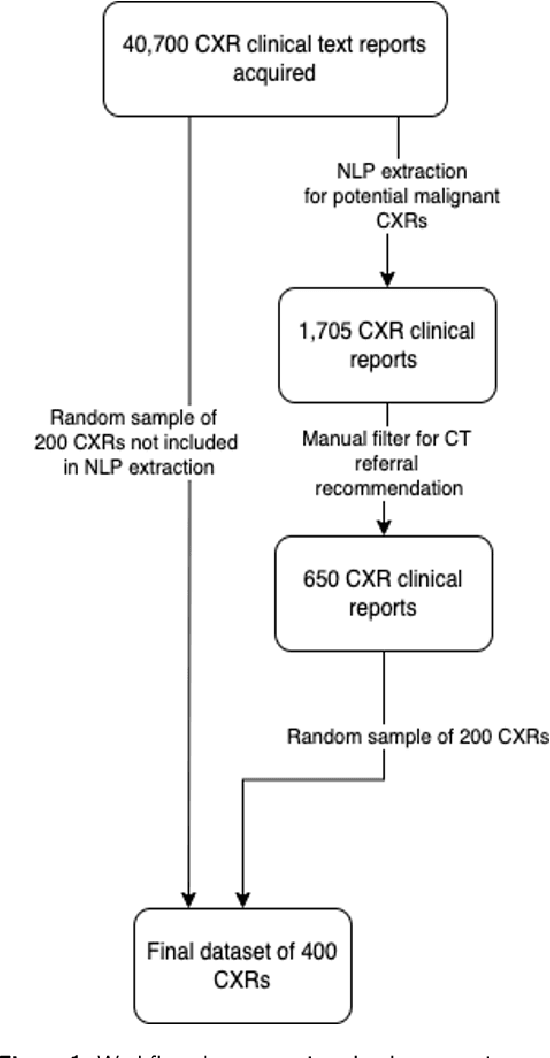

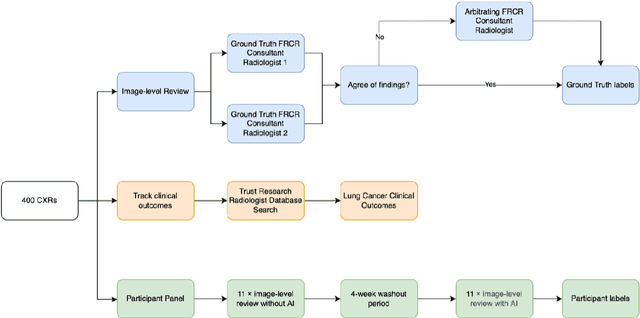
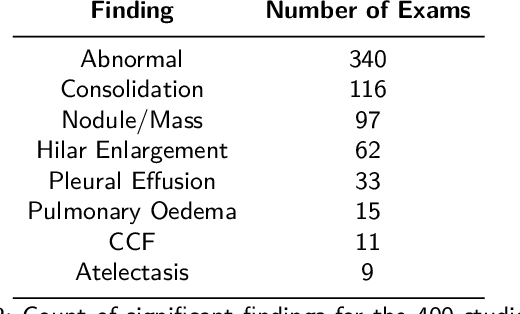
Objectives: The present study evaluated the impact of a commercially available explainable AI algorithm in augmenting the ability of clinicians to identify lung cancer on chest X-rays (CXR). Design: This retrospective study evaluated the performance of 11 clinicians for detecting lung cancer from chest radiographs, with and without assistance from a commercially available AI algorithm (red dot, Behold.ai) that predicts suspected lung cancer from CXRs. Clinician performance was evaluated against clinically confirmed diagnoses. Setting: The study analysed anonymised patient data from an NHS hospital; the dataset consisted of 400 chest radiographs from adult patients (18 years and above) who had a CXR performed in 2020, with corresponding clinical text reports. Participants: A panel of readers consisting of 11 clinicians (consultant radiologists, radiologist trainees and reporting radiographers) participated in this study. Main outcome measures: Overall accuracy, sensitivity, specificity and precision for detecting lung cancer on CXRs by clinicians, with and without AI input. Agreement rates between clinicians and performance standard deviation were also evaluated, with and without AI input. Results: The use of the AI algorithm by clinicians led to an improved overall performance for lung tumour detection, achieving an overall increase of 17.4% of lung cancers being identified on CXRs which would have otherwise been missed, an overall increase in detection of smaller tumours, a 24% and 13% increased detection of stage 1 and stage 2 lung cancers respectively, and standardisation of clinician performance. Conclusions: This study showed great promise in the clinical utility of AI algorithms in improving early lung cancer diagnosis and promoting health equity through overall improvement in reader performances, without impacting downstream imaging resources.