 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangformers: Unified NLP Pipelines for Language Models
Apr 12, 2025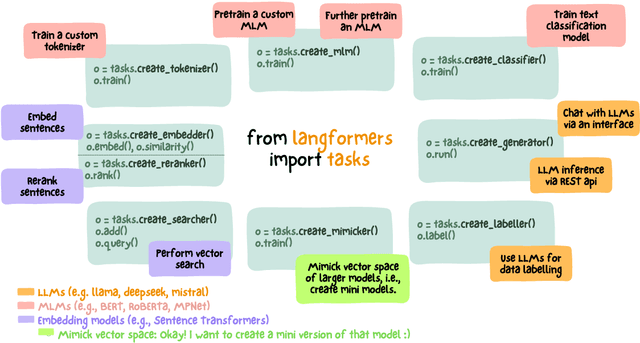
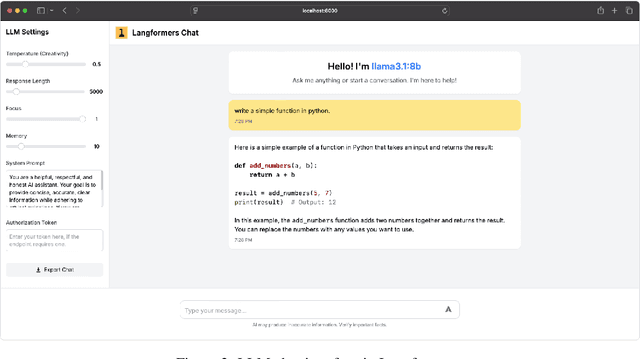
Transformer-based language models have revolutionized the field of natural language processing (NLP). However, using these models often involves navigating multiple frameworks and tools, as well as writing repetitive boilerplate code. This complexity can discourage non-programmers and beginners, and even slow down prototyping for experienced developers. To address these challenges, we introduce Langformers, an open-source Python library designed to streamline NLP pipelines through a unified, factory-based interface for large language model (LLM) and masked language model (MLM) tasks. Langformers integrates conversational AI, MLM pretraining, text classification, sentence embedding/reranking, data labelling, semantic search, and knowledge distillation into a cohesive API, supporting popular platforms such as Hugging Face and Ollama. Key innovations include: (1) task-specific factories that abstract training, inference, and deployment complexities; (2) built-in memory and streaming for conversational agents; and (3) lightweight, modular design that prioritizes ease of use. Documentation: https://langformers.com
"Actionable Help" in Crises: A Novel Dataset and Resource-Efficient Models for Identifying Request and Offer Social Media Posts
Feb 24, 2025During crises, social media serves as a crucial coordination tool, but the vast influx of posts--from "actionable" requests and offers to generic content like emotional support, behavioural guidance, or outdated information--complicates effective classification. Although generative LLMs (Large Language Models) can address this issue with few-shot classification, their high computational demands limit real-time crisis response. While fine-tuning encoder-only models (e.g., BERT) is a popular choice, these models still exhibit higher inference times in resource-constrained environments. Moreover, although distilled variants (e.g., DistilBERT) exist, they are not tailored for the crisis domain. To address these challenges, we make two key contributions. First, we present CrisisHelpOffer, a novel dataset of 101k tweets collaboratively labelled by generative LLMs and validated by humans, specifically designed to distinguish actionable content from noise. Second, we introduce the first crisis-specific mini models optimized for deployment in resource-constrained settings. Across 13 crisis classification tasks, our mini models surpass BERT (also outperform or match the performance of RoBERTa, MPNet, and BERTweet), offering higher accuracy with significantly smaller sizes and faster speeds. The Medium model is 47% smaller with 3.8% higher accuracy at 3.5x speed, the Small model is 68% smaller with a 1.8% accuracy gain at 7.7x speed, and the Tiny model, 83% smaller, matches BERT's accuracy at 18.6x speed. All models outperform existing distilled variants, setting new benchmarks. Finally, as a case study, we analyze social media posts from a global crisis to explore help-seeking and assistance-offering behaviours in selected developing and developed countries.
CReMa: Crisis Response through Computational Identification and Matching of Cross-Lingual Requests and Offers Shared on Social Media
May 20, 2024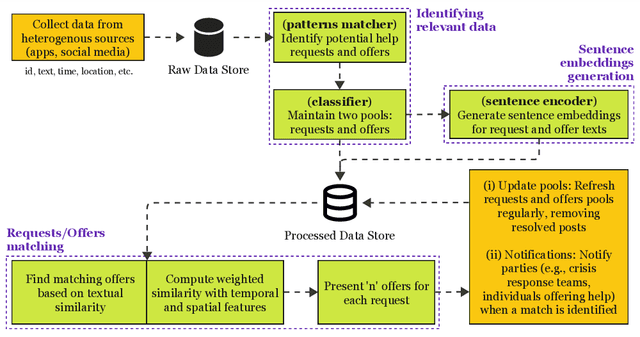
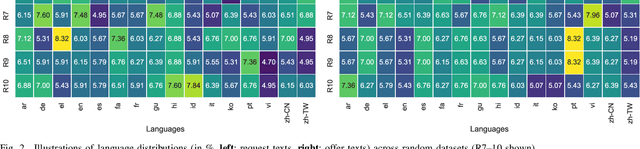
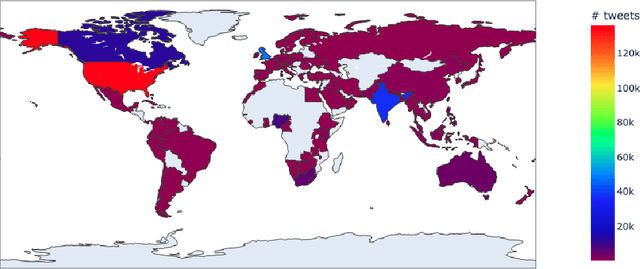
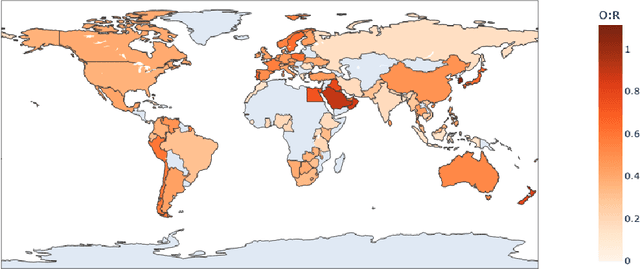
During times of crisis, social media platforms play a vital role in facilitating communication and coordinating resources. Amidst chaos and uncertainty, communities often rely on these platforms to share urgent pleas for help, extend support, and organize relief efforts. However, the sheer volume of conversations during such periods, which can escalate to unprecedented levels, necessitates the automated identification and matching of requests and offers to streamline relief operations. This study addresses the challenge of efficiently identifying and matching assistance requests and offers on social media platforms during emergencies. We propose CReMa (Crisis Response Matcher), a systematic approach that integrates textual, temporal, and spatial features for multi-lingual request-offer matching. By leveraging CrisisTransformers, a set of pre-trained models specific to crises, and a cross-lingual embedding space, our methodology enhances the identification and matching tasks while outperforming strong baselines such as RoBERTa, MPNet, and BERTweet, in classification tasks, and Universal Sentence Encoder, Sentence Transformers in crisis embeddings generation tasks. We introduce a novel multi-lingual dataset that simulates scenarios of help-seeking and offering assistance on social media across the 16 most commonly used languages in Australia. We conduct comprehensive cross-lingual experiments across these 16 languages, also while examining trade-offs between multiple vector search strategies and accuracy. Additionally, we analyze a million-scale geotagged global dataset to comprehend patterns in relation to seeking help and offering assistance on social media. Overall, these contributions advance the field of crisis informatics and provide benchmarks for future research in the area.
Semantically Enriched Cross-Lingual Sentence Embeddings for Crisis-related Social Media Texts
Mar 25, 2024
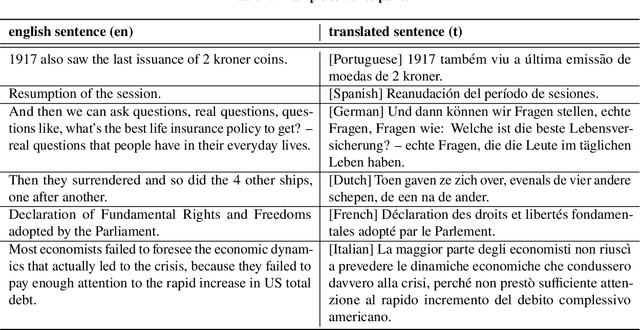
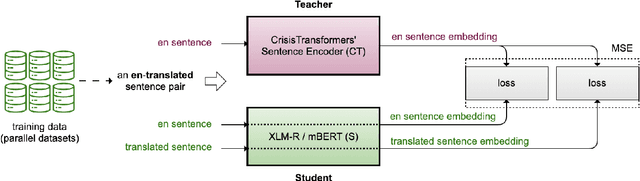
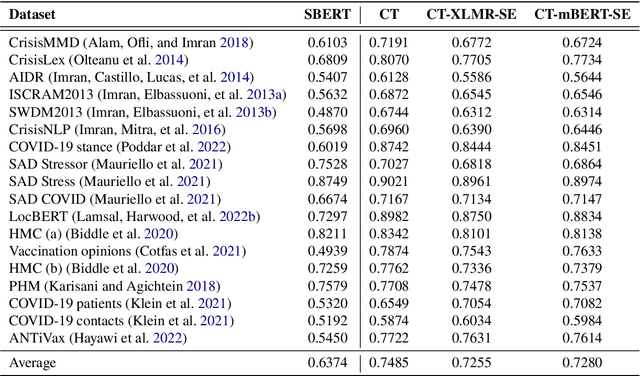
Tasks such as semantic search and clustering on crisis-related social media texts enhance our comprehension of crisis discourse, aiding decision-making and targeted interventions. Pre-trained language models have advanced performance in crisis informatics, but their contextual embeddings lack semantic meaningfulness. Although the CrisisTransformers family includes a sentence encoder to address the semanticity issue, it remains monolingual, processing only English texts. Furthermore, employing separate models for different languages leads to embeddings in distinct vector spaces, introducing challenges when comparing semantic similarities between multi-lingual texts. Therefore, we propose multi-lingual sentence encoders (CT-XLMR-SE and CT-mBERT-SE) that embed crisis-related social media texts for over 50 languages, such that texts with similar meanings are in close proximity within the same vector space, irrespective of language diversity. Results in sentence encoding and sentence matching tasks are promising, suggesting these models could serve as robust baselines when embedding multi-lingual crisis-related social media texts. The models are publicly available at: https://huggingface.co/crisistransformers.
CrisisTransformers: Pre-trained language models and sentence encoders for crisis-related social media texts
Oct 01, 2023



Social media platforms play an essential role in crisis communication, but analyzing crisis-related social media texts is challenging due to their informal nature. Transformer-based pre-trained models like BERT and RoBERTa have shown success in various NLP tasks, but they are not tailored for crisis-related texts. Furthermore, general-purpose sentence encoders are used to generate sentence embeddings, regardless of the textual complexities in crisis-related texts. Advances in applications like text classification, semantic search, and clustering contribute to effective processing of crisis-related texts, which is essential for emergency responders to gain a comprehensive view of a crisis event, whether historical or real-time. To address these gaps in crisis informatics literature, this study introduces CrisisTransformers, an ensemble of pre-trained language models and sentence encoders trained on an extensive corpus of over 15 billion word tokens from tweets associated with more than 30 crisis events, including disease outbreaks, natural disasters, conflicts, and other critical incidents. We evaluate existing models and CrisisTransformers on 18 crisis-specific public datasets. Our pre-trained models outperform strong baselines across all datasets in classification tasks, and our best-performing sentence encoder improves the state-of-the-art by 17.43% in sentence encoding tasks. Additionally, we investigate the impact of model initialization on convergence and evaluate the significance of domain-specific models in generating semantically meaningful sentence embeddings. All models are publicly released (https://huggingface.co/crisistransformers), with the anticipation that they will serve as a robust baseline for tasks involving the analysis of crisis-related social media texts.
Where did you tweet from? Inferring the origin locations of tweets based on contextual information
Nov 18, 2022Public conversations on Twitter comprise many pertinent topics including disasters, protests, politics, propaganda, sports, climate change, epidemics/pandemic outbreaks, etc., that can have both regional and global aspects. Spatial discourse analysis rely on geographical data. However, today less than 1% of tweets are geotagged; in both cases--point location or bounding place information. A major issue with tweets is that Twitter users can be at location A and exchange conversations specific to location B, which we call the Location A/B problem. The problem is considered solved if location entities can be classified as either origin locations (Location As) or non-origin locations (Location Bs). In this work, we propose a simple yet effective framework--the True Origin Model--to address the problem that uses machine-level natural language understanding to identify tweets that conceivably contain their origin location information. The model achieves promising accuracy at country (80%), state (67%), city (58%), county (56%) and district (64%) levels with support from a Location Extraction Model as basic as the CoNLL-2003-based RoBERTa. We employ a tweet contexualizer (locBERT) which is one of the core components of the proposed model, to investigate multiple tweets' distributions for understanding Twitter users' tweeting behavior in terms of mentioning origin and non-origin locations. We also highlight a major concern with the currently regarded gold standard test set (ground truth) methodology, introduce a new data set, and identify further research avenues for advancing the area.
Socially Enhanced Situation Awareness from Microblogs using Artificial Intelligence: A Survey
Sep 13, 2022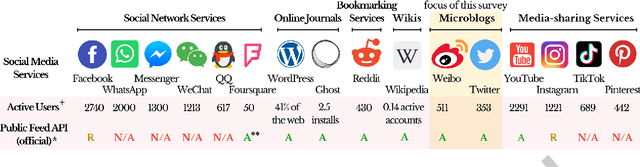
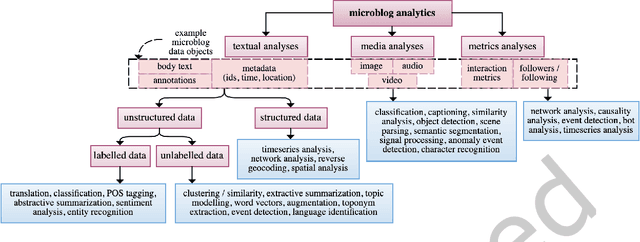
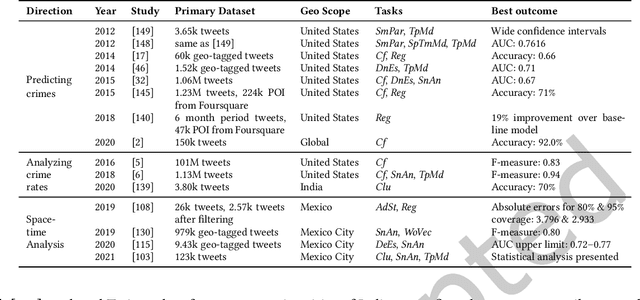
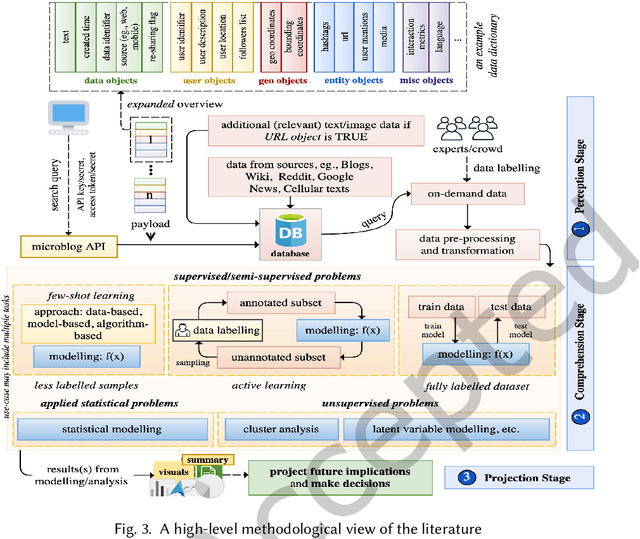
The rise of social media platforms provides an unbounded, infinitely rich source of aggregate knowledge of the world around us, both historic and real-time, from a human perspective. The greatest challenge we face is how to process and understand this raw and unstructured data, go beyond individual observations and see the "big picture"--the domain of Situation Awareness. We provide an extensive survey of Artificial Intelligence research, focusing on microblog social media data with applications to Situation Awareness, that gives the seminal work and state-of-the-art approaches across six thematic areas: Crime, Disasters, Finance, Physical Environment, Politics, and Health and Population. We provide a novel, unified methodological perspective, identify key results and challenges, and present ongoing research directions.
Twitter conversations predict the daily confirmed COVID-19 cases
Jun 21, 2022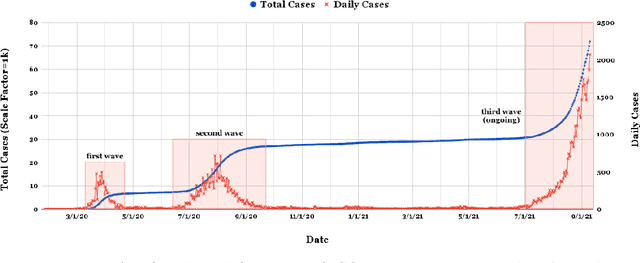
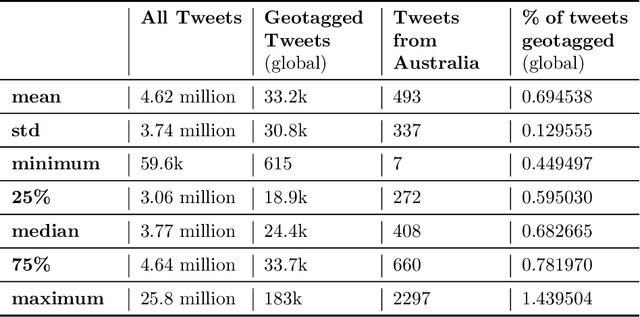
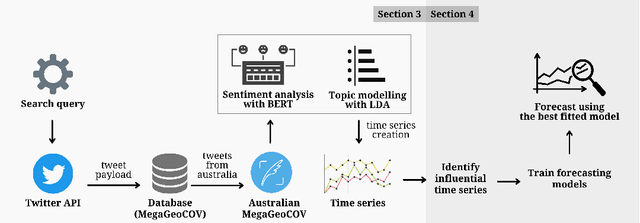
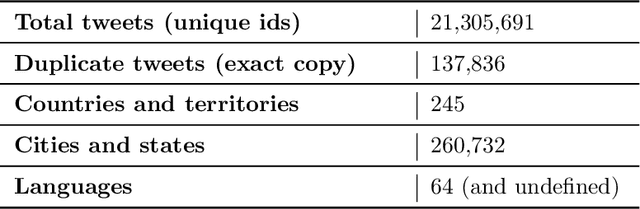
As of writing this paper, COVID-19 (Coronavirus disease 2019) has spread to more than 220 countries and territories. Following the outbreak, the pandemic's seriousness has made people more active on social media, especially on the microblogging platforms such as Twitter and Weibo. The pandemic-specific discourse has remained on-trend on these platforms for months now. Previous studies have confirmed the contributions of such socially generated conversations towards situational awareness of crisis events. The early forecasts of cases are essential to authorities to estimate the requirements of resources needed to cope with the outgrowths of the virus. Therefore, this study attempts to incorporate the public discourse in the design of forecasting models particularly targeted for the steep-hill region of an ongoing wave. We propose a sentiment-involved topic-based methodology for designing multiple time series from publicly available COVID-19 related Twitter conversations. As a use case, we implement the proposed methodology on Australian COVID-19 daily cases and Twitter conversations generated within the country. Experimental results: (i) show the presence of latent social media variables that Granger-cause the daily COVID-19 confirmed cases, and (ii) confirm that those variables offer additional prediction capability to forecasting models. Further, the results show that the inclusion of social media variables for modeling introduces 48.83--51.38% improvements on RMSE over the baseline models. We also release the large-scale COVID-19 specific geotagged global tweets dataset, MegaGeoCOV, to the public anticipating that the geotagged data of this scale would aid in understanding the conversational dynamics of the pandemic through other spatial and temporal contexts.