 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter conversations predict the daily confirmed COVID-19 cases
Paper and Code
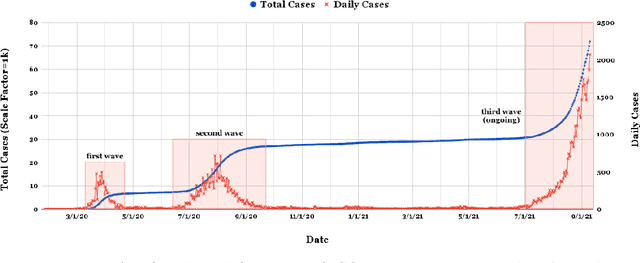
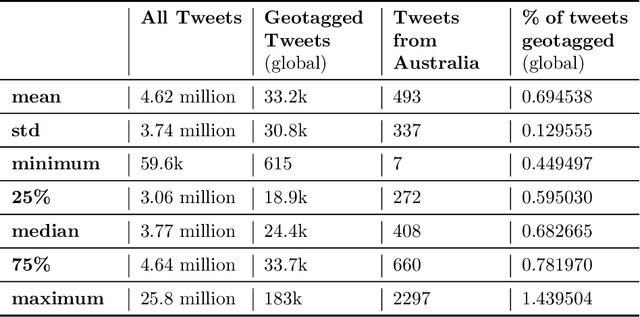
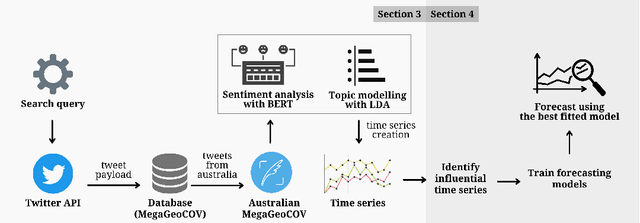
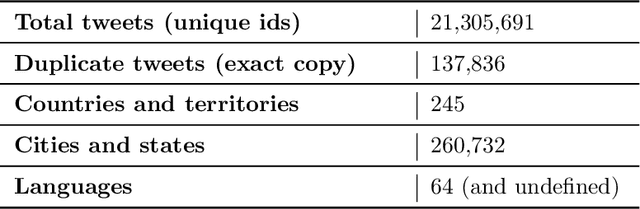
As of writing this paper, COVID-19 (Coronavirus disease 2019) has spread to more than 220 countries and territories. Following the outbreak, the pandemic's seriousness has made people more active on social media, especially on the microblogging platforms such as Twitter and Weibo. The pandemic-specific discourse has remained on-trend on these platforms for months now. Previous studies have confirmed the contributions of such socially generated conversations towards situational awareness of crisis events. The early forecasts of cases are essential to authorities to estimate the requirements of resources needed to cope with the outgrowths of the virus. Therefore, this study attempts to incorporate the public discourse in the design of forecasting models particularly targeted for the steep-hill region of an ongoing wave. We propose a sentiment-involved topic-based methodology for designing multiple time series from publicly available COVID-19 related Twitter conversations. As a use case, we implement the proposed methodology on Australian COVID-19 daily cases and Twitter conversations generated within the country. Experimental results: (i) show the presence of latent social media variables that Granger-cause the daily COVID-19 confirmed cases, and (ii) confirm that those variables offer additional prediction capability to forecasting models. Further, the results show that the inclusion of social media variables for modeling introduces 48.83--51.38% improvements on RMSE over the baseline models. We also release the large-scale COVID-19 specific geotagged global tweets dataset, MegaGeoCOV, to the public anticipating that the geotagged data of this scale would aid in understanding the conversational dynamics of the pandemic through other spatial and temporal contexts.