 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCReMa: Crisis Response through Computational Identification and Matching of Cross-Lingual Requests and Offers Shared on Social Media
Paper and Code
May 20, 2024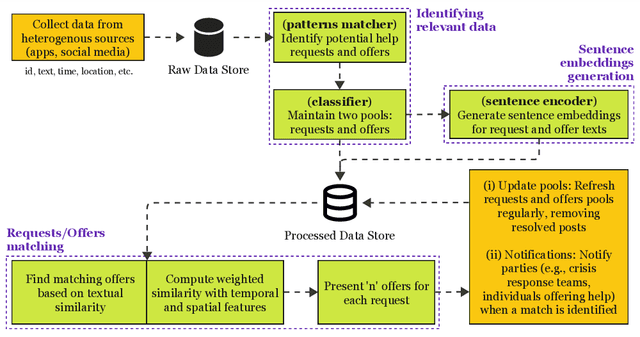
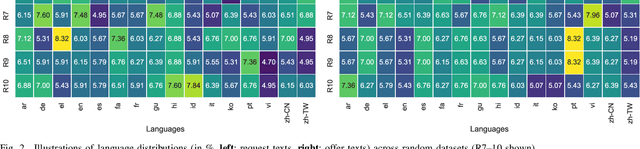
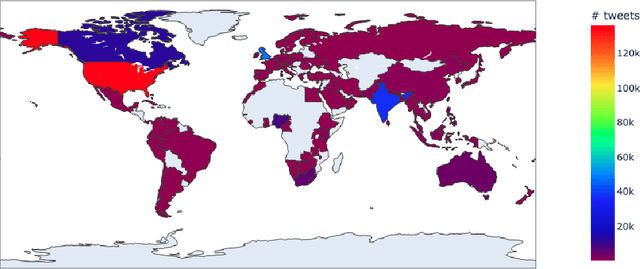
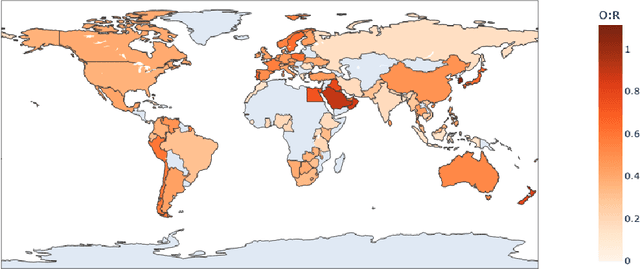
During times of crisis, social media platforms play a vital role in facilitating communication and coordinating resources. Amidst chaos and uncertainty, communities often rely on these platforms to share urgent pleas for help, extend support, and organize relief efforts. However, the sheer volume of conversations during such periods, which can escalate to unprecedented levels, necessitates the automated identification and matching of requests and offers to streamline relief operations. This study addresses the challenge of efficiently identifying and matching assistance requests and offers on social media platforms during emergencies. We propose CReMa (Crisis Response Matcher), a systematic approach that integrates textual, temporal, and spatial features for multi-lingual request-offer matching. By leveraging CrisisTransformers, a set of pre-trained models specific to crises, and a cross-lingual embedding space, our methodology enhances the identification and matching tasks while outperforming strong baselines such as RoBERTa, MPNet, and BERTweet, in classification tasks, and Universal Sentence Encoder, Sentence Transformers in crisis embeddings generation tasks. We introduce a novel multi-lingual dataset that simulates scenarios of help-seeking and offering assistance on social media across the 16 most commonly used languages in Australia. We conduct comprehensive cross-lingual experiments across these 16 languages, also while examining trade-offs between multiple vector search strategies and accuracy. Additionally, we analyze a million-scale geotagged global dataset to comprehend patterns in relation to seeking help and offering assistance on social media. Overall, these contributions advance the field of crisis informatics and provide benchmarks for future research in the area.