 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of Acetabular Version from Anteroposterior Pelvic Radiograph Employing Deep Learning
Nov 14, 2021
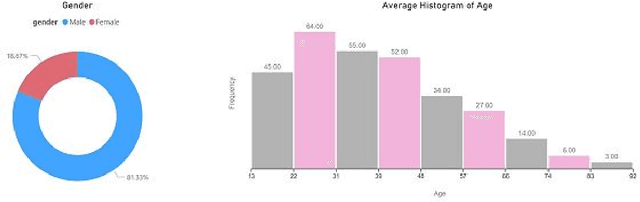

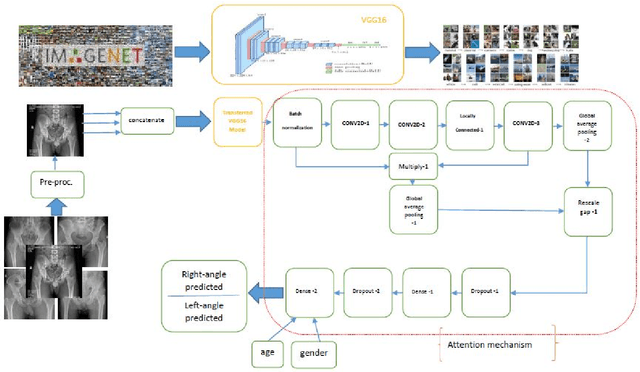
Background and Objective: The Acetabular version, an essential factor in total hip arthroplasty, is measured by CT scan as the gold standard. The dose of radiation and expensiveness of CT make anterior-posterior pelvic radiograph an appropriate alternative procedure. In this study, we applied a deep learning approach on anteroposterior pelvic X-rays to measure anatomical version, eliminating the necessity of using Computed tomography scan. Methods: The right and left acetabular version angles of the hips of 300 patients are computed using their CT images. The proposed deep learning model, Attention on Pretrained-VGG16 for Bone Age, is applied to the AP images of the included population. The age and gender of these people are added as two other inputs to the last fully connected layer of attention mechanism. As the output, the angles of both hips are predicted. Results: The angles of hips computed on CT increase as people get older with the mean values of 16.54 and 16.11 (right and left angles) for men and 20.61 and 19.55 for women in our dataset. The predicted errors in the estimation of right and left angles using the proposed method of deep learning are in the accurate region of error (<=3 degrees) which shows the ability of the proposed method in measuring anatomical version based on AP images. Conclusion: The suggested algorithm, applying pre-trained vgg16 on the AP images of the pelvis of patients followed by an attention model considering age and gender of patients, can assess version accurately using only AP radiographs while obviating the need for CT scan. The applied technique of estimation of anatomical acetabular version based on AP pelvic images using DL approaches, to the best of authors' knowledge, has not been published yet.
Multi-Scale Convolutional Neural Network for Automated AMD Classification using Retinal OCT Images
Oct 06, 2021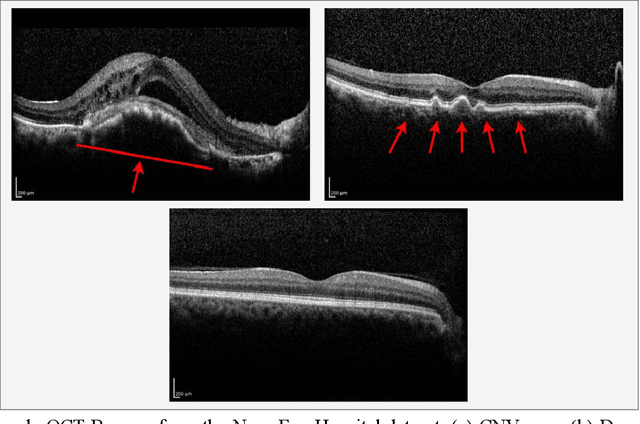

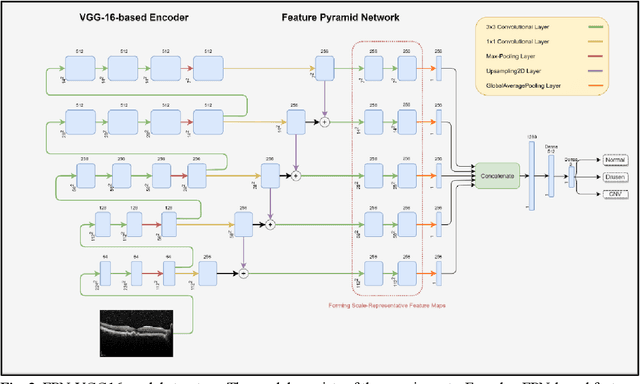
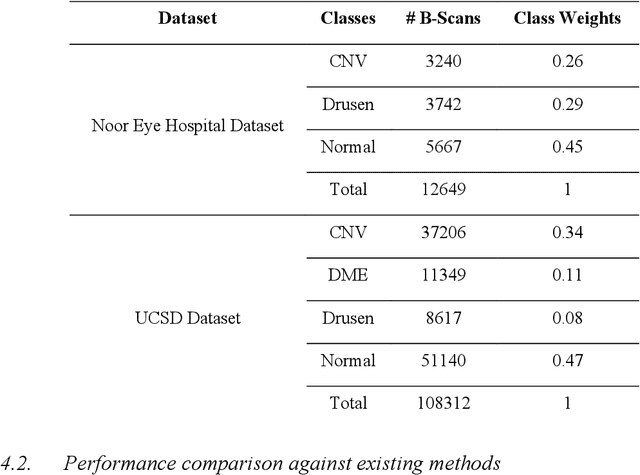
Age-related macular degeneration (AMD) is the most common cause of blindness in developed countries, especially in people over 60 years of age. The workload of specialists and the healthcare system in this field has increased in recent years mainly dues to three reasons: 1) increased use of retinal optical coherence tomography (OCT) imaging technique, 2) prevalence of population aging worldwide, and 3) chronic nature of AMD. Recent developments in deep learning have provided a unique opportunity for the development of fully automated diagnosis frameworks. Considering the presence of AMD-related retinal pathologies in varying sizes in OCT images, our objective was to propose a multi-scale convolutional neural network (CNN) capable of distinguishing pathologies using receptive fields with various sizes. The multi-scale CNN was designed based on the feature pyramid network (FPN) structure and was used to diagnose normal and two common clinical characteristics of dry and wet AMD, namely drusen and choroidal neovascularization (CNV). The proposed method was evaluated on a national dataset gathered at Noor Eye Hospital (NEH), consisting of 12649 retinal OCT images from 441 patients, and a UCSD public dataset, consisting of 108312 OCT images. The results show that the multi-scale FPN-based structure was able to improve the base model's overall accuracy by 0.4% to 3.3% for different backbone models. In addition, gradual learning improved the performance in two phases from 87.2%+-2.5% to 93.4%+-1.4% by pre-training the base model on ImageNet weights in the first phase and fine-tuning the resulting model on a dataset of OCT images in the second phase. The promising quantitative and qualitative results of the proposed architecture prove the suitability of the proposed method to be used as a screening tool in healthcare centers assisting ophthalmologists in making better diagnostic decisions.
Automatic Ship Classification Utilizing Bag of Deep Features
Feb 23, 2021
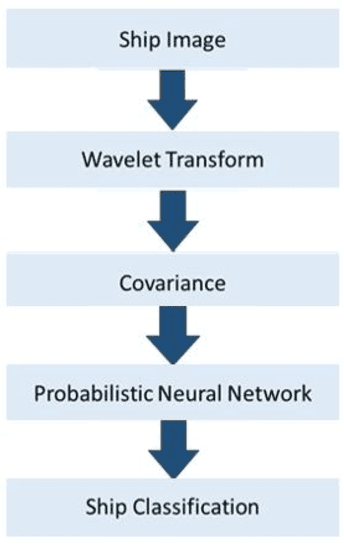
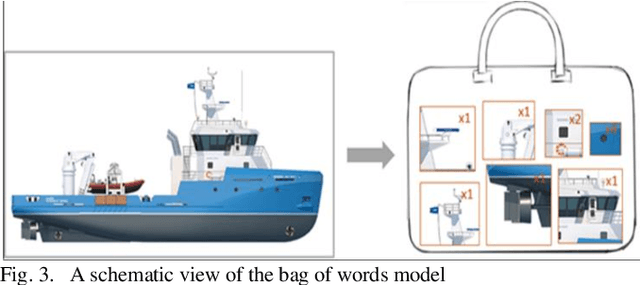
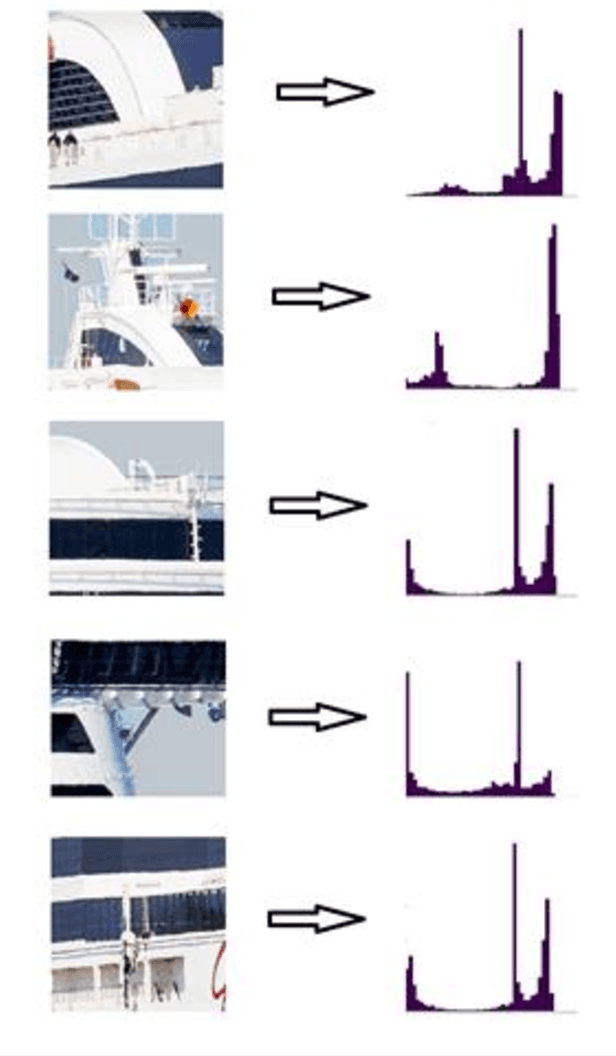
Detection and classification of ships based on their silhouette profiles in natural imagery is an important undertaking in computer science. This problem can be viewed from a variety of perspectives, including security, traffic control, and even militarism. Therefore, in each of the aforementioned applications, specific processing is required. In this paper, by applying the "bag of words" (BoW), a new method is presented that its words are the features that are obtained using pre-trained models of deep convolutional networks. , Three VGG models are utilized which provide superior accuracy in identifying objects. The regions of the image that are selected as the initial proposals are derived from a greedy algorithm on the key points generated by the Scale Invariant Feature Transform (SIFT) method. Using the deep features in the BOW method provides a good improvement in the recognition and classification of ships. Eventually, we obtained an accuracy of 91.8% in the classification of the ships which shows the improvement of about 5% compared to previous methods.
Classification of Breast Cancer Lesions in Ultrasound Images by using Attention Layer and loss Ensembles in Deep Convolutional Neural Networks
Feb 23, 2021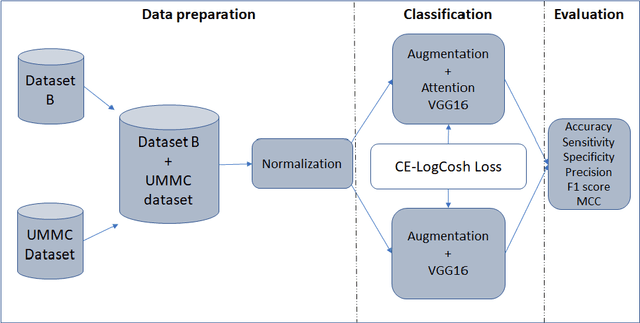
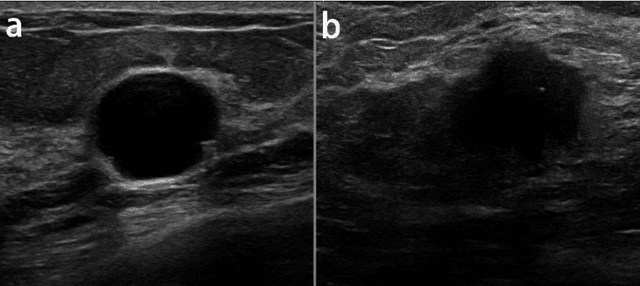


Reliable classification of benign and malignant lesions in breast ultrasound images can provide an effective and relatively low cost method for early diagnosis of breast cancer. The accuracy of the diagnosis is however highly dependent on the quality of the ultrasound systems and the experience of the users (radiologists). The leverage in deep convolutional neural network approaches provided solutions in efficient analysis of breast ultrasound images. In this study, we proposed a new framework for classification of breast cancer lesions by use of an attention module in modified VGG16 architecture. We also proposed new ensembled loss function which is the combination of binary cross-entropy and logarithm of the hyperbolic cosine loss to improve the model discrepancy between classified lesions and its labels. Networks trained from pretrained ImageNet weights, and subsequently fine-tuned with ultrasound datasets. The proposed model in this study outperformed other modified VGG16 architectures with the accuracy of 93% and also the results are competitive with other state of the art frameworks for classification of breast cancer lesions. In this study, we employed transfer learning approaches with the pre-trained VGG16 architecture. Different CNN models for classification task were trained to predict benign or malignant lesions in breast ultrasound images. Our Experimental results show that the choice of loss function is highly important in classification task and by adding an attention block we could empower the performance our model.
Accurate Stress Assessment based on functional Near Infrared Spectroscopy using Deep Learning Approach
Feb 14, 2020
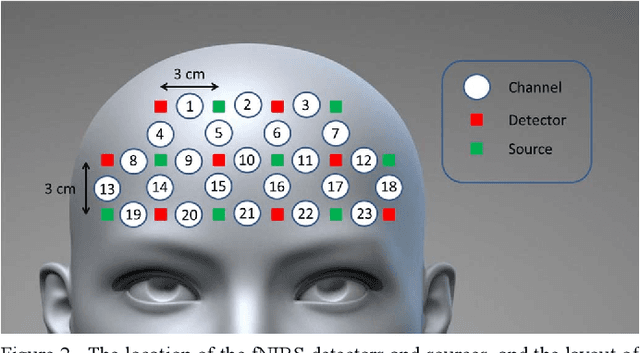
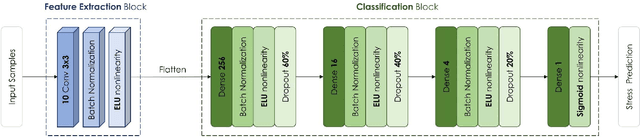
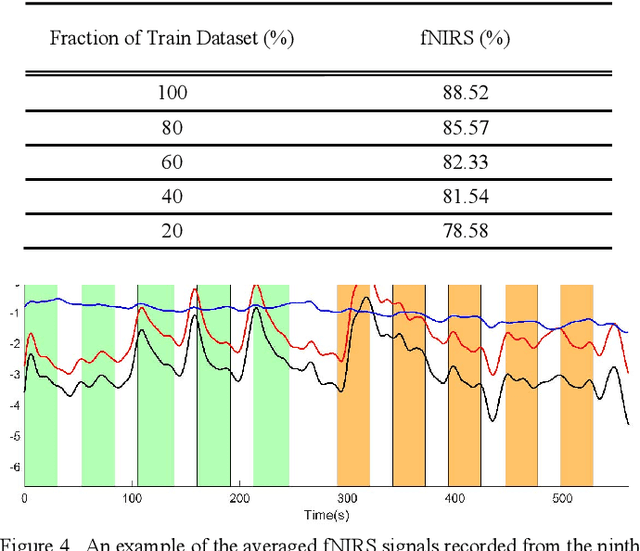
Stress is known as one of the major factors threatening human health. A large number of studies have been performed in order to either assess or relieve stress by analyzing the brain and heart-related signals. In this study, signals produced by functional Near-Infrared Spectroscopy (fNIRS) of the brain recorded from 10 healthy volunteers are employed to assess the stress induced by the Montreal Imaging Stress Task by means of a deep learning system. The proposed deep learning system consists of two main parts: First, the one-dimensional convolutional neural network is employed to build informative feature maps. Then, a stack of deep fully connected layers is used to predict the stress existence probability. Experiment results showed that the trained fNIRS model performs stress classification by achieving 88.52 -+ 0.77% accuracy. Employment of the proposed deep learning system trained on the fNIRS measurements leads to higher stress classification accuracy than the existing methods proposed in fNIRS studies in which the same experimental procedure has been employed. The proposed method suggests better stability with lower variation in prediction. Furthermore, its low computational cost opens up the possibility to be applied in real-time stress assessment.
Region-based Convolution Neural Network Approach for Accurate Segmentation of Pelvic Radiograph
Oct 29, 2019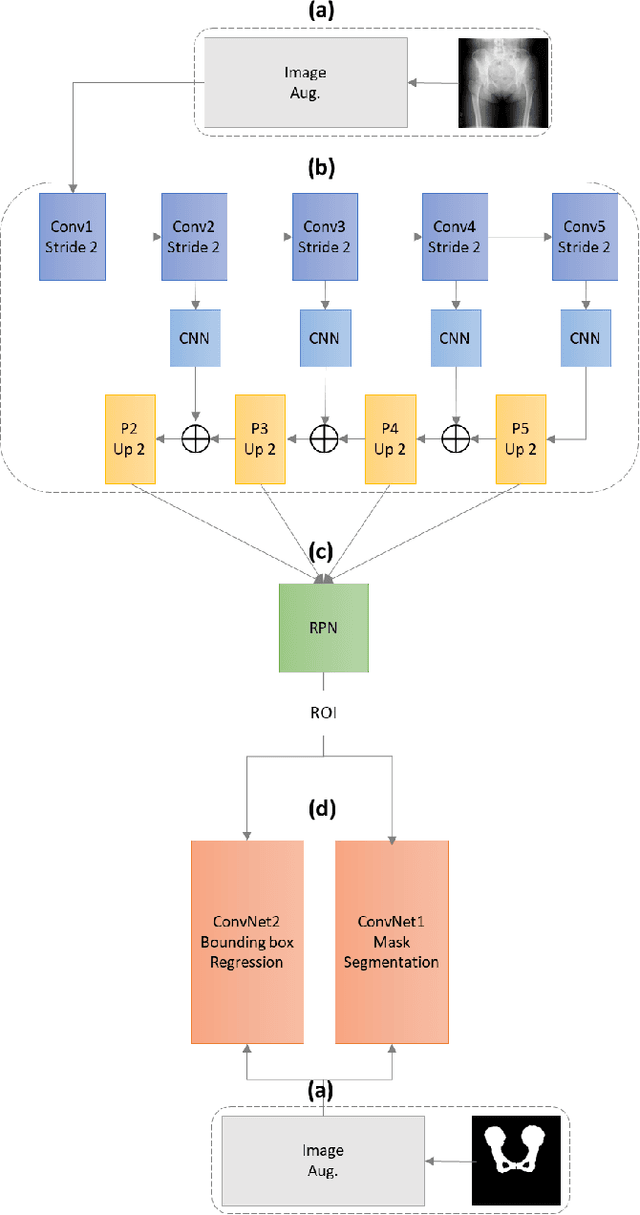
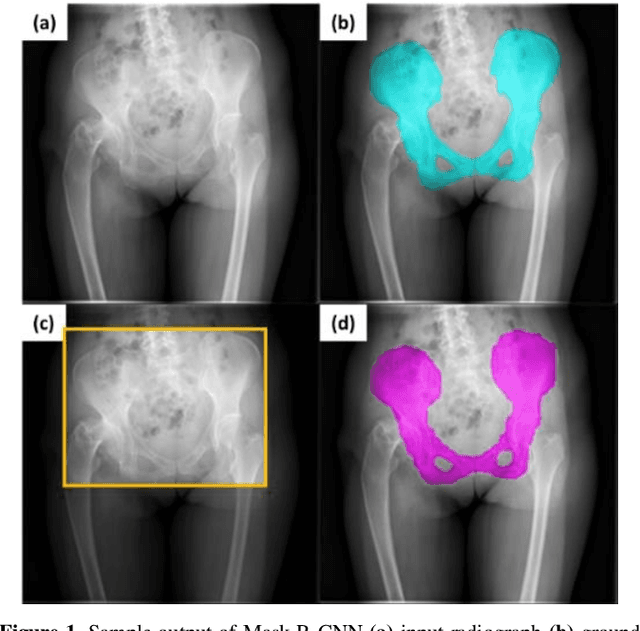
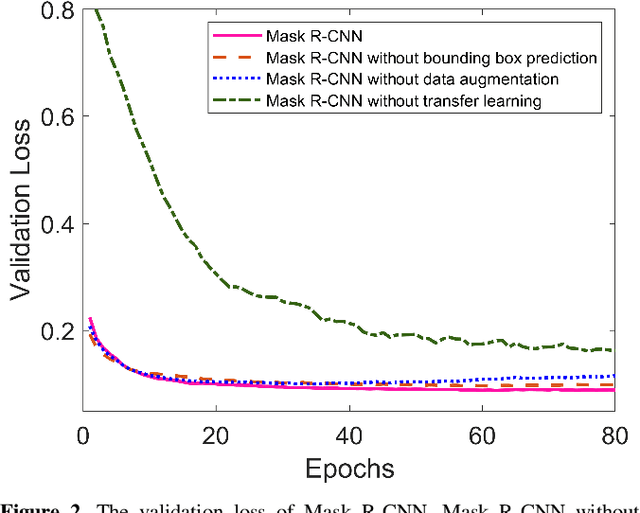
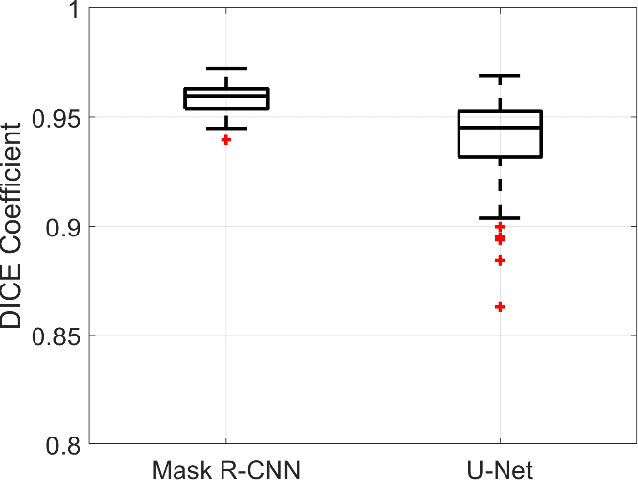
With the increasing usage of radiograph images as a most common medical imaging system for diagnosis, treatment planning, and clinical studies, it is increasingly becoming a vital factor to use machine learning-based systems to provide reliable information for surgical pre-planning. Segmentation of pelvic bone in radiograph images is a critical preprocessing step for some applications such as automatic pose estimation and disease detection. However, the encoder-decoder style network known as U-Net has demonstrated limited results due to the challenging complexity of the pelvic shapes, especially in severe patients. In this paper, we propose a novel multi-task segmentation method based on Mask R-CNN architecture. For training, the network weights were initialized by large non-medical dataset and fine-tuned with radiograph images. Furthermore, in the training process, augmented data was generated to improve network performance. Our experiments show that Mask R-CNN utilizing multi-task learning, transfer learning, and data augmentation techniques achieve 0.96 DICE coefficient, which significantly outperforms the U-Net. Notably, for a fair comparison, the same transfer learning and data augmentation techniques have been used for U-net training.
Estimation of Pelvic Sagittal Inclination from Anteroposterior Radiograph Using Convolutional Neural Networks: Proof-of-Concept Study
Oct 26, 2019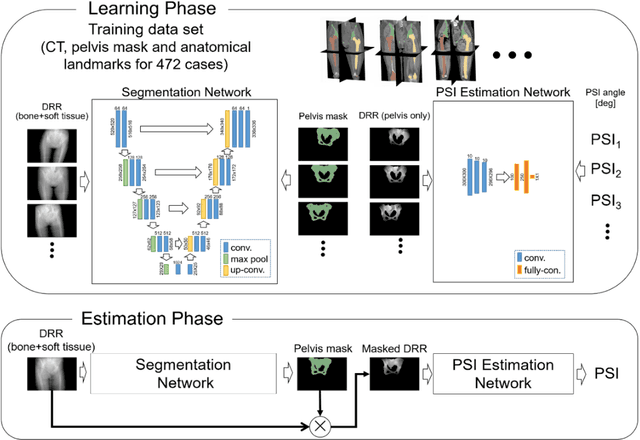
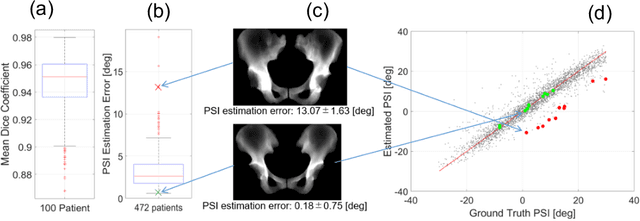
Alignment of the bones in standing position provides useful information in surgical planning. In total hip arthroplasty (THA), pelvic sagittal inclination (PSI) angle in the standing position is an important factor in planning of cup alignment and has been estimated mainly from radiographs. Previous methods for PSI estimation used a patient-specific CT to create digitally reconstructed radiographs (DRRs) and compare them with the radiograph to estimate relative position between the pelvis and the x-ray detector. In this study, we developed a method that estimates PSI angle from a single anteroposterior radiograph using two convolutional neural networks (CNNs) without requiring the patient-specific CT, which reduces radiation exposure of the patient and opens up the possibility of application in a larger number of hospitals where CT is not acquired in a routine protocol.