 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Progressive Visual-Logic-Aligned Framework for Ride-Hailing Adjudication
Mar 18, 2026The efficient adjudication of responsibility disputes is pivotal for maintaining marketplace fairness. However, the exponential surge in ride-hailing volume renders manual review intractable, while conventional automated methods lack the reasoning transparency required for quasi-judicial decisions. Although Multimodal LLMs offer a promising paradigm, they fundamentally struggle to bridge the gap between general visual semantics and rigorous evidentiary protocols, often leading to perceptual hallucinations and logical looseness. To address these systemic misalignments, we introduce RideJudge, a Progressive Visual-Logic-Aligned Framework. Instead of relying on generic pre-training, we bridge the semantic gap via SynTraj, a synthesis engine that grounds abstract liability concepts into concrete trajectory patterns. To resolve the conflict between massive regulation volume and limited context windows, we propose an Adaptive Context Optimization strategy that distills expert knowledge, coupled with a Chain-of-Adjudication mechanism to enforce active evidentiary inquiry. Furthermore, addressing the inadequacy of sparse binary feedback for complex liability assessment, we implement a novel Ordinal-Sensitive Reinforcement Learning mechanism that calibrates decision boundaries against hierarchical severity. Extensive experiments show that our RideJudge-8B achieves 88.41\% accuracy, surpassing 32B-scale baselines and establishing a new standard for interpretable adjudication.
Exploring the Interplay Between Video Generation and World Models in Autonomous Driving: A Survey
Nov 05, 2024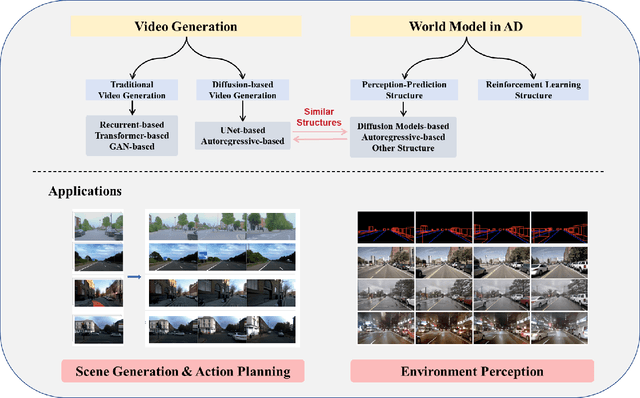
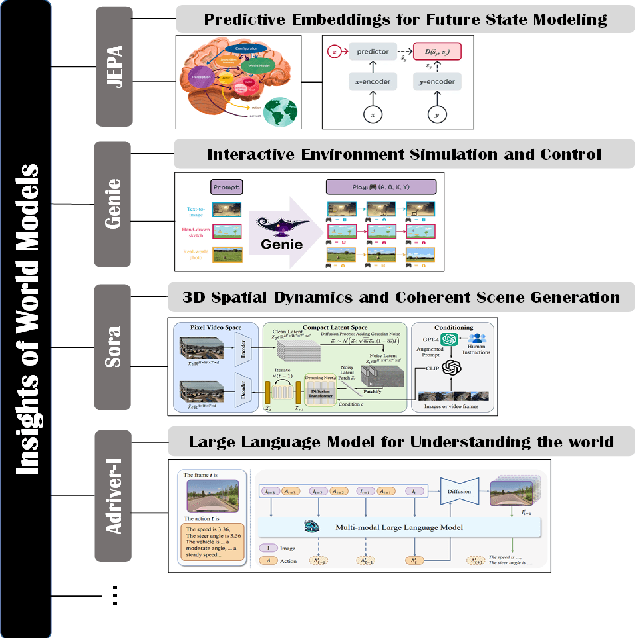
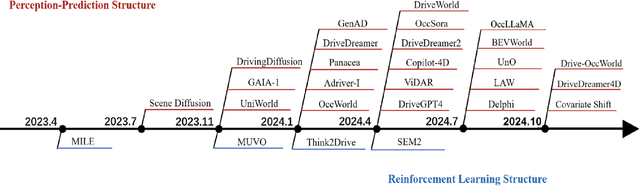
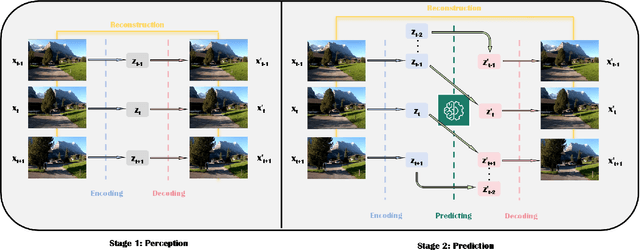
World models and video generation are pivotal technologies in the domain of autonomous driving, each playing a critical role in enhancing the robustness and reliability of autonomous systems. World models, which simulate the dynamics of real-world environments, and video generation models, which produce realistic video sequences, are increasingly being integrated to improve situational awareness and decision-making capabilities in autonomous vehicles. This paper investigates the relationship between these two technologies, focusing on how their structural parallels, particularly in diffusion-based models, contribute to more accurate and coherent simulations of driving scenarios. We examine leading works such as JEPA, Genie, and Sora, which exemplify different approaches to world model design, thereby highlighting the lack of a universally accepted definition of world models. These diverse interpretations underscore the field's evolving understanding of how world models can be optimized for various autonomous driving tasks. Furthermore, this paper discusses the key evaluation metrics employed in this domain, such as Chamfer distance for 3D scene reconstruction and Fr\'echet Inception Distance (FID) for assessing the quality of generated video content. By analyzing the interplay between video generation and world models, this survey identifies critical challenges and future research directions, emphasizing the potential of these technologies to jointly advance the performance of autonomous driving systems. The findings presented in this paper aim to provide a comprehensive understanding of how the integration of video generation and world models can drive innovation in the development of safer and more reliable autonomous vehicles.
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
Multi-Agent Reinforcement Learning for Order-dispatching via Order-Vehicle Distribution Matching
Oct 07, 2019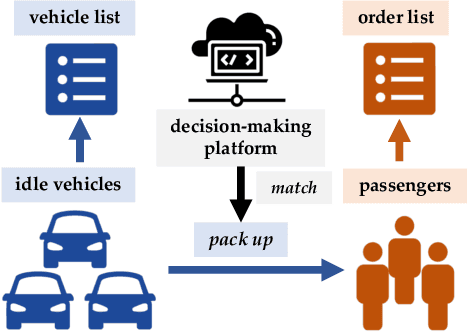


Improving the efficiency of dispatching orders to vehicles is a research hotspot in online ride-hailing systems. Most of the existing solutions for order-dispatching are centralized controlling, which require to consider all possible matches between available orders and vehicles. For large-scale ride-sharing platforms, there are thousands of vehicles and orders to be matched at every second which is of very high computational cost. In this paper, we propose a decentralized execution order-dispatching method based on multi-agent reinforcement learning to address the large-scale order-dispatching problem. Different from the previous cooperative multi-agent reinforcement learning algorithms, in our method, all agents work independently with the guidance from an evaluation of the joint policy since there is no need for communication or explicit cooperation between agents. Furthermore, we use KL-divergence optimization at each time step to speed up the learning process and to balance the vehicles (supply) and orders (demand). Experiments on both the explanatory environment and real-world simulator show that the proposed method outperforms the baselines in terms of accumulated driver income (ADI) and Order Response Rate (ORR) in various traffic environments. Besides, with the support of the online platform of Didi Chuxing, we designed a hybrid system to deploy our model.
D$^2$-City: A Large-Scale Dashcam Video Dataset of Diverse Traffic Scenarios
Apr 03, 2019
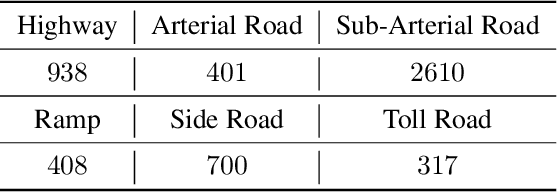
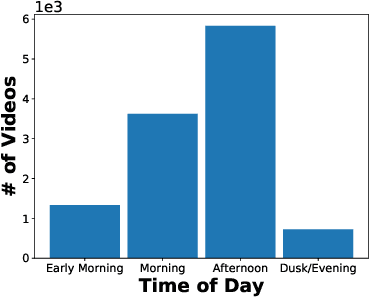
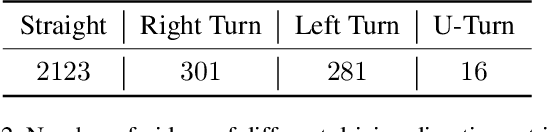
Driving datasets accelerate the development of intelligent driving and related computer vision technologies, while substantial and detailed annotations serve as fuels and powers to boost the efficacy of such datasets to improve learning-based models. We propose D$^2$-City, a large-scale comprehensive collection of dashcam videos collected by vehicles on DiDi's platform. D$^2$-City contains more than 10000 video clips which deeply reflect the diversity and complexity of real-world traffic scenarios in China. We also provide bounding boxes and tracking annotations of 12 classes of objects in all frames of 1000 videos and detection annotations on keyframes for the remainder of the videos. Compared with existing datasets, D$^2$-City features data in varying weather, road, and traffic conditions and a huge amount of elaborate detection and tracking annotations. By bringing a diverse set of challenging cases to the community, we expect the D$^2$-City dataset will advance the perception and related areas of intelligent driving.