 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptLLM: Optimal Assignment of Queries to Large Language Models
May 24, 2024Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
An Evaluation of Log Parsing with ChatGPT
Jun 02, 2023Software logs play an essential role in ensuring the reliability and maintainability of large-scale software systems, as they are often the sole source of runtime information. Log parsing, which converts raw log messages into structured data, is an important initial step towards downstream log analytics. In recent studies, ChatGPT, the current cutting-edge large language model (LLM), has been widely applied to a wide range of software engineering tasks. However, its performance in automated log parsing remains unclear. In this paper, we evaluate ChatGPT's ability to undertake log parsing by addressing two research questions. (1) Can ChatGPT effectively parse logs? (2) How does ChatGPT perform with different prompting methods? Our results show that ChatGPT can achieve promising results for log parsing with appropriate prompts, especially with few-shot prompting. Based on our findings, we outline several challenges and opportunities for ChatGPT-based log parsing.
Log-based Anomaly Detection with Deep Learning: How Far Are We?
Feb 15, 2022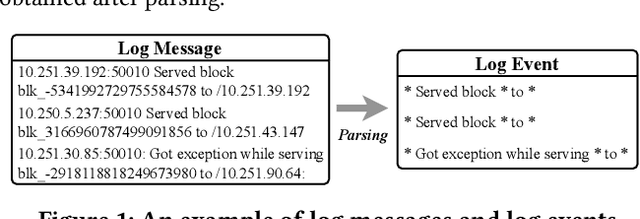
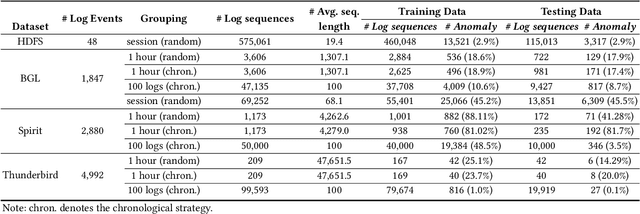
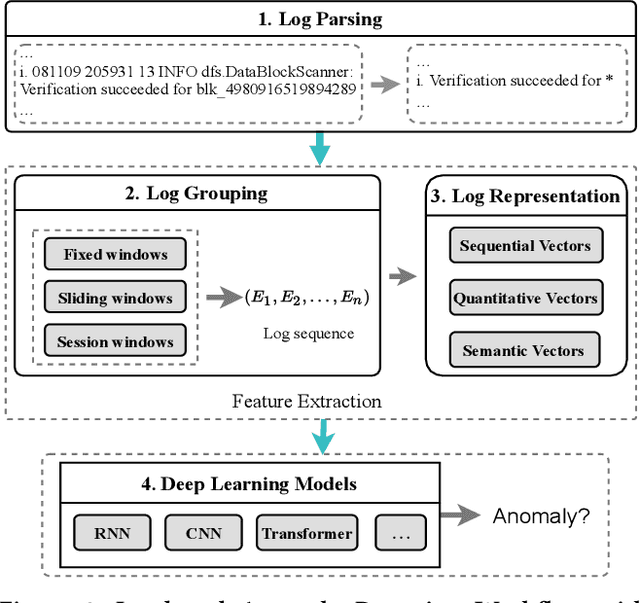

Software-intensive systems produce logs for troubleshooting purposes. Recently, many deep learning models have been proposed to automatically detect system anomalies based on log data. These models typically claim very high detection accuracy. For example, most models report an F-measure greater than 0.9 on the commonly-used HDFS dataset. To achieve a profound understanding of how far we are from solving the problem of log-based anomaly detection, in this paper, we conduct an in-depth analysis of five state-of-the-art deep learning-based models for detecting system anomalies on four public log datasets. Our experiments focus on several aspects of model evaluation, including training data selection, data grouping, class distribution, data noise, and early detection ability. Our results point out that all these aspects have significant impact on the evaluation, and that all the studied models do not always work well. The problem of log-based anomaly detection has not been solved yet. Based on our findings, we also suggest possible future work.
Log-based Anomaly Detection Without Log Parsing
Aug 08, 2021
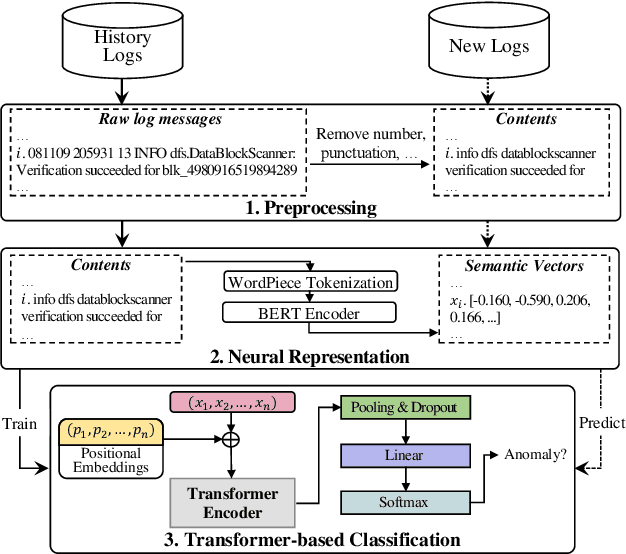
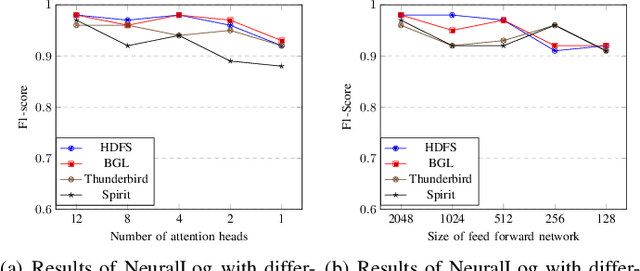

Software systems often record important runtime information in system logs for troubleshooting purposes. There have been many studies that use log data to construct machine learning models for detecting system anomalies. Through our empirical study, we find that existing log-based anomaly detection approaches are significantly affected by log parsing errors that are introduced by 1) OOV (out-of-vocabulary) words, and 2) semantic misunderstandings. The log parsing errors could cause the loss of important information for anomaly detection. To address the limitations of existing methods, we propose NeuralLog, a novel log-based anomaly detection approach that does not require log parsing. NeuralLog extracts the semantic meaning of raw log messages and represents them as semantic vectors. These representation vectors are then used to detect anomalies through a Transformer-based classification model, which can capture the contextual information from log sequences. Our experimental results show that the proposed approach can effectively understand the semantic meaning of log messages and achieve accurate anomaly detection results. Overall, NeuralLog achieves F1-scores greater than 0.95 on four public datasets, outperforming the existing approaches.