 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog-based Anomaly Detection with Deep Learning: How Far Are We?
Paper and Code
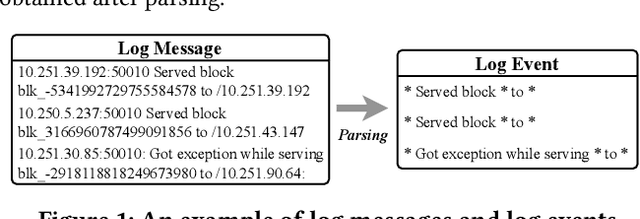
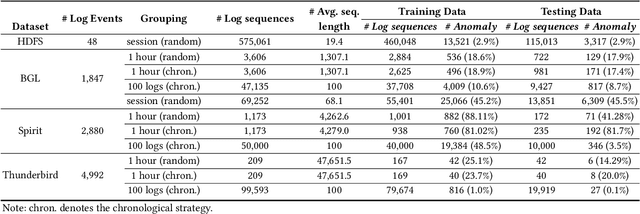
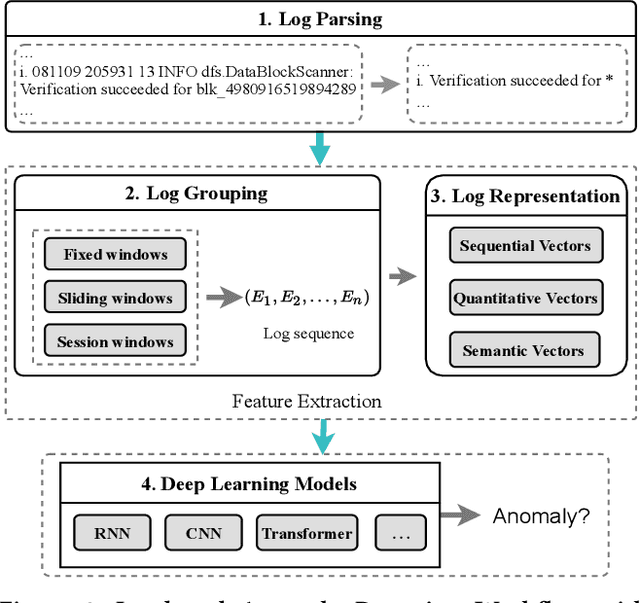

Software-intensive systems produce logs for troubleshooting purposes. Recently, many deep learning models have been proposed to automatically detect system anomalies based on log data. These models typically claim very high detection accuracy. For example, most models report an F-measure greater than 0.9 on the commonly-used HDFS dataset. To achieve a profound understanding of how far we are from solving the problem of log-based anomaly detection, in this paper, we conduct an in-depth analysis of five state-of-the-art deep learning-based models for detecting system anomalies on four public log datasets. Our experiments focus on several aspects of model evaluation, including training data selection, data grouping, class distribution, data noise, and early detection ability. Our results point out that all these aspects have significant impact on the evaluation, and that all the studied models do not always work well. The problem of log-based anomaly detection has not been solved yet. Based on our findings, we also suggest possible future work.