 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIP: Visual-guided Prompt Evolution for Efficient Dense Vision-Language Inference
May 13, 2026Pursuing training-free open-vocabulary semantic segmentation in an efficient and generalizable manner remains challenging due to the deep-seated spatial bias in CLIP. To overcome the limitations of existing solutions, this work moves beyond the CLIP-based paradigm and harnesses the recent spatially-aware dino$.$txt framework to facilitate more efficient and high-quality dense prediction. While dino$.$txt exhibits robust spatial awareness, we find that the semantic ambiguity of text queries gives rise to severe mismatch within its dense cross-modal interactions. To address this, we introduce Visual-guided Prompt evolution (VIP) to rectify the semantic expressiveness of text queries in dino$.$txt, unleashing its potential for fine-grained object perception. Towards this end, VIP integrates alias expansion with a visual-guided distillation mechanism to mine valuable semantic cues, which are robustly aggregated in a saliency-aware manner to yield a high-fidelity prediction. Extensive evaluations demonstrate that VIP: 1. surpasses the top-leading methods by 1.4%-8.4% average mIoU, 2. generalizes well to diverse challenging domains, and 3. requires marginal inference time and memory overhead.
Efficient3D: A Unified Framework for Adaptive and Debiased Token Reduction in 3D MLLMs
Apr 03, 2026Recent advances in Multimodal Large Language Models (MLLMs) have expanded reasoning capabilities into 3D domains, enabling fine-grained spatial understanding. However, the substantial size of 3D MLLMs and the high dimensionality of input features introduce considerable inference overhead, which limits practical deployment on resource constrained platforms. To overcome this limitation, this paper presents Efficient3D, a unified framework for visual token pruning that accelerates 3D MLLMs while maintaining competitive accuracy. The proposed framework introduces a Debiased Visual Token Importance Estimator (DVTIE) module, which considers the influence of shallow initial layers during attention aggregation, thereby producing more reliable importance predictions for visual tokens. In addition, an Adaptive Token Rebalancing (ATR) strategy is developed to dynamically adjust pruning strength based on scene complexity, preserving semantic completeness and maintaining balanced attention across layers. Together, they enable context-aware token reduction that maintains essential semantics with lower computation. Comprehensive experiments conducted on five representative 3D vision and language benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D, demonstrate that Efficient3D achieves superior performance compared with unpruned baselines, with a +2.57% CIDEr improvement on the Scan2Cap dataset. Therefore, Efficient3D provides a scalable and effective solution for efficient inference in 3D MLLMs. The code is released at: https://github.com/sol924/Efficient3D
TALENT: Target-aware Efficient Tuning for Referring Image Segmentation
Apr 01, 2026Referring image segmentation aims to segment specific targets based on a natural text expression. Recently, parameter-efficient tuning (PET) has emerged as a promising paradigm. However, existing PET-based methods often suffer from the fact that visual features can't emphasize the text-referred target instance but activate co-category yet unrelated objects. We analyze and quantify this problem, terming it the `non-target activation' (NTA) issue. To address this, we propose a novel framework, TALENT, which utilizes target-aware efficient tuning for PET-based RIS. Specifically, we first propose a Rectified Cost Aggregator (RCA) to efficiently aggregate text-referred features. Then, to calibrate `NTA' into accurate target activation, we adopt a Target-aware Learning Mechanism (TLM), including contextual pairwise consistency learning and target-centric contrastive learning. The former uses the sentence-level text feature to achieve a holistic understanding of the referent and constructs a text-referred affinity map to optimize the semantic association of visual features. The latter further enhances target localization to discover the distinct instance while suppressing associations with other unrelated ones. The two objectives work in concert and address `NTA' effectively. Extensive evaluations show that TALENT outperforms existing methods across various metrics (e.g., 2.5\% mIoU gains on G-Ref val set). Our codes will be released at: https://github.com/Kimsure/TALENT.
TF-SSD: A Strong Pipeline via Synergic Mask Filter for Training-free Co-salient Object Detection
Apr 01, 2026Co-salient Object Detection (CoSOD) aims to segment salient objects that consistently appear across a group of related images. Despite the notable progress achieved by recent training-based approaches, they still remain constrained by the closed-set datasets and exhibit limited generalization. However, few studies explore the potential of Vision Foundation Models (VFMs) to address CoSOD, which demonstrate a strong generalized ability and robust saliency understanding. In this paper, we investigate and leverage VFMs for CoSOD, and further propose a novel training-free method, TF-SSD, through the synergy between SAM and DINO. Specifically, we first utilize SAM to generate comprehensive raw proposals, which serve as a candidate mask pool. Then, we introduce a quality mask generator to filter out redundant masks, thereby acquiring a refined mask set. Since this generator is built upon SAM, it inherently lacks semantic understanding of saliency. To this end, we adopt an intra-image saliency filter that employs DINO's attention maps to identify visually salient masks within individual images. Moreover, to extend saliency understanding across group images, we propose an inter-image prototype selector, which computes similarity scores among cross-image prototypes to select masks with the highest score. These selected masks serve as final predictions for CoSOD. Extensive experiments show that our TF-SSD outperforms existing methods (e.g., 13.7\% gains over the recent training-free method). Codes are available at https://github.com/hzz-yy/TF-SSD.
A Training-free Synthetic Data Selection Method for Semantic Segmentation
Jan 25, 2025



Training semantic segmenter with synthetic data has been attracting great attention due to its easy accessibility and huge quantities. Most previous methods focused on producing large-scale synthetic image-annotation samples and then training the segmenter with all of them. However, such a solution remains a main challenge in that the poor-quality samples are unavoidable, and using them to train the model will damage the training process. In this paper, we propose a training-free Synthetic Data Selection (SDS) strategy with CLIP to select high-quality samples for building a reliable synthetic dataset. Specifically, given massive synthetic image-annotation pairs, we first design a Perturbation-based CLIP Similarity (PCS) to measure the reliability of synthetic image, thus removing samples with low-quality images. Then we propose a class-balance Annotation Similarity Filter (ASF) by comparing the synthetic annotation with the response of CLIP to remove the samples related to low-quality annotations. The experimental results show that using our method significantly reduces the data size by half, while the trained segmenter achieves higher performance. The code is released at https://github.com/tanghao2000/SDS.
Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation
Jun 17, 2024Weakly supervised semantic segmentation has witnessed great achievements with image-level labels. Several recent approaches use the CLIP model to generate pseudo labels for training an individual segmentation model, while there is no attempt to apply the CLIP model as the backbone to directly segment objects with image-level labels. In this paper, we propose WeCLIP, a CLIP-based single-stage pipeline, for weakly supervised semantic segmentation. Specifically, the frozen CLIP model is applied as the backbone for semantic feature extraction, and a new decoder is designed to interpret extracted semantic features for final prediction. Meanwhile, we utilize the above frozen backbone to generate pseudo labels for training the decoder. Such labels cannot be optimized during training. We then propose a refinement module (RFM) to rectify them dynamically. Our architecture enforces the proposed decoder and RFM to benefit from each other to boost the final performance. Extensive experiments show that our approach significantly outperforms other approaches with less training cost. Additionally, our WeCLIP also obtains promising results for fully supervised settings. The code is available at https://github.com/zbf1991/WeCLIP.
* CVPR 2024 Highlight
Continual Segmentation with Disentangled Objectness Learning and Class Recognition
Mar 14, 2024Most continual segmentation methods tackle the problem as a per-pixel classification task. However, such a paradigm is very challenging, and we find query-based segmenters with built-in objectness have inherent advantages compared with per-pixel ones, as objectness has strong transfer ability and forgetting resistance. Based on these findings, we propose CoMasTRe by disentangling continual segmentation into two stages: forgetting-resistant continual objectness learning and well-researched continual classification. CoMasTRe uses a two-stage segmenter learning class-agnostic mask proposals at the first stage and leaving recognition to the second stage. During continual learning, a simple but effective distillation is adopted to strengthen objectness. To further mitigate the forgetting of old classes, we design a multi-label class distillation strategy suited for segmentation. We assess the effectiveness of CoMasTRe on PASCAL VOC and ADE20K. Extensive experiments show that our method outperforms per-pixel and query-based methods on both datasets. Code will be available at https://github.com/jordangong/CoMasTRe.
Democracy Does Matter: Comprehensive Feature Mining for Co-Salient Object Detection
Mar 11, 2022



Co-salient object detection, with the target of detecting co-existed salient objects among a group of images, is gaining popularity. Recent works use the attention mechanism or extra information to aggregate common co-salient features, leading to incomplete even incorrect responses for target objects. In this paper, we aim to mine comprehensive co-salient features with democracy and reduce background interference without introducing any extra information. To achieve this, we design a democratic prototype generation module to generate democratic response maps, covering sufficient co-salient regions and thereby involving more shared attributes of co-salient objects. Then a comprehensive prototype based on the response maps can be generated as a guide for final prediction. To suppress the noisy background information in the prototype, we propose a self-contrastive learning module, where both positive and negative pairs are formed without relying on additional classification information. Besides, we also design a democratic feature enhancement module to further strengthen the co-salient features by readjusting attention values. Extensive experiments show that our model obtains better performance than previous state-of-the-art methods, especially on challenging real-world cases (e.g., for CoCA, we obtain a gain of 2.0% for MAE, 5.4% for maximum F-measure, 2.3% for maximum E-measure, and 3.7% for S-measure) under the same settings. Code will be released soon.
Fast Pixel-Matching for Video Object Segmentation
Jul 09, 2021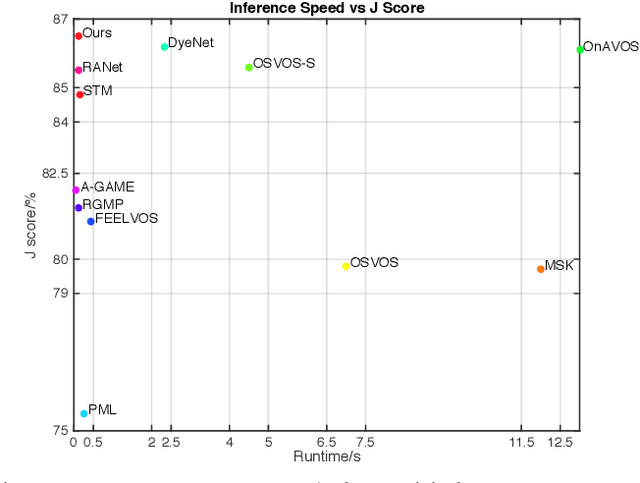
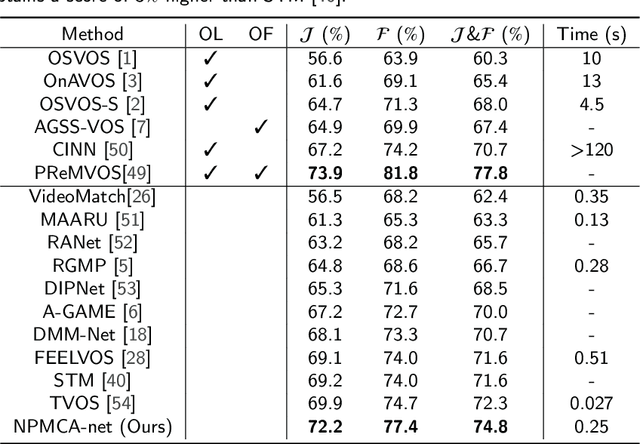
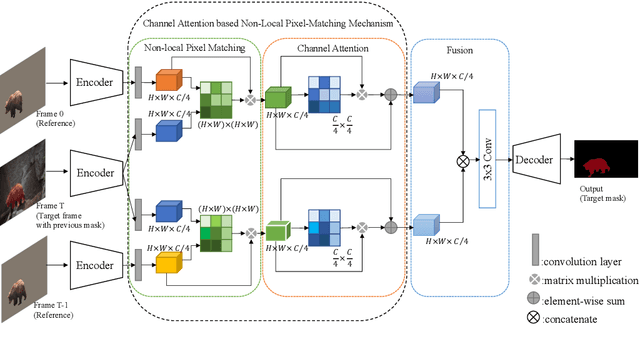
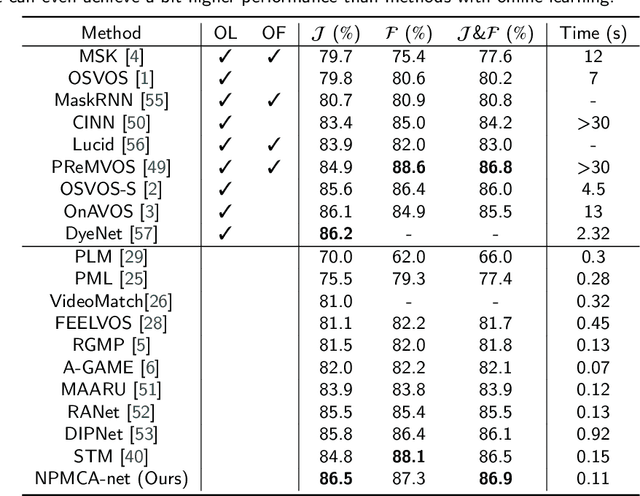
Video object segmentation, aiming to segment the foreground objects given the annotation of the first frame, has been attracting increasing attentions. Many state-of-the-art approaches have achieved great performance by relying on online model updating or mask-propagation techniques. However, most online models require high computational cost due to model fine-tuning during inference. Most mask-propagation based models are faster but with relatively low performance due to failure to adapt to object appearance variation. In this paper, we are aiming to design a new model to make a good balance between speed and performance. We propose a model, called NPMCA-net, which directly localizes foreground objects based on mask-propagation and non-local technique by matching pixels in reference and target frames. Since we bring in information of both first and previous frames, our network is robust to large object appearance variation, and can better adapt to occlusions. Extensive experiments show that our approach can achieve a new state-of-the-art performance with a fast speed at the same time (86.5% IoU on DAVIS-2016 and 72.2% IoU on DAVIS-2017, with speed of 0.11s per frame) under the same level comparison. Source code is available at https://github.com/siyueyu/NPMCA-net.
Structure-Consistent Weakly Supervised Salient Object Detection with Local Saliency Coherence
Dec 09, 2020



Sparse labels have been attracting much attention in recent years. However, the performance gap between weakly supervised and fully supervised salient object detection methods is huge, and most previous weakly supervised works adopt complex training methods with many bells and whistles. In this work, we propose a one-round end-to-end training approach for weakly supervised salient object detection via scribble annotations without pre/post-processing operations or extra supervision data. Since scribble labels fail to offer detailed salient regions, we propose a local coherence loss to propagate the labels to unlabeled regions based on image features and pixel distance, so as to predict integral salient regions with complete object structures. We design a saliency structure consistency loss as self-consistent mechanism to ensure consistent saliency maps are predicted with different scales of the same image as input, which could be viewed as a regularization technique to enhance the model generalization ability. Additionally, we design an aggregation module (AGGM) to better integrate high-level features, low-level features and global context information for the decoder to aggregate various information. Extensive experiments show that our method achieves a new state-of-the-art performance on six benchmarks (e.g. for the ECSSD dataset: F_\beta = 0.8995, E_\xi = 0.9079 and MAE = 0.0489$), with an average gain of 4.60\% for F-measure, 2.05\% for E-measure and 1.88\% for MAE over the previous best method on this task. Source code is available at http://github.com/siyueyu/SCWSSOD.