 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Feature Regularized Loss for Weakly Supervised Semantic Segmentation
Paper and Code
Aug 03, 2021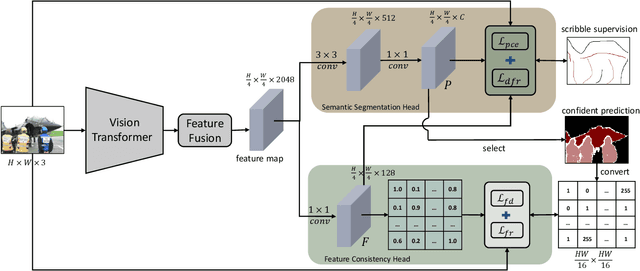
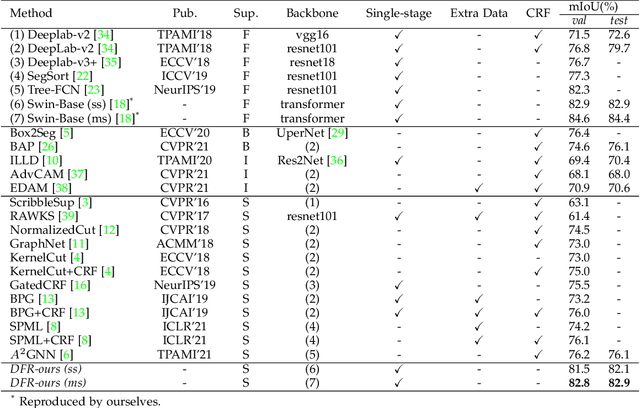
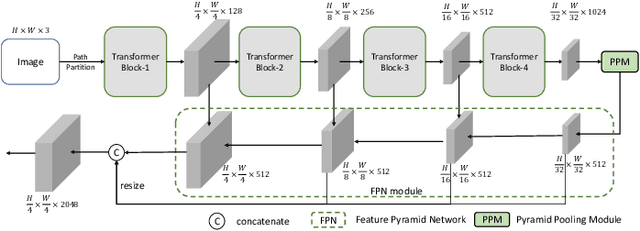

We focus on tackling weakly supervised semantic segmentation with scribble-level annotation. The regularized loss has been proven to be an effective solution for this task. However, most existing regularized losses only leverage static shallow features (color, spatial information) to compute the regularized kernel, which limits its final performance since such static shallow features fail to describe pair-wise pixel relationship in complicated cases. In this paper, we propose a new regularized loss which utilizes both shallow and deep features that are dynamically updated in order to aggregate sufficient information to represent the relationship of different pixels. Moreover, in order to provide accurate deep features, we adopt vision transformer as the backbone and design a feature consistency head to train the pair-wise feature relationship. Unlike most approaches that adopt multi-stage training strategy with many bells and whistles, our approach can be directly trained in an end-to-end manner, in which the feature consistency head and our regularized loss can benefit from each other. Extensive experiments show that our approach achieves new state-of-the-art performances, outperforming other approaches by a significant margin with more than 6\% mIoU increase.