 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Subspace Clustering Methods
May 11, 2025To further utilize the unsupervised features and pairwise information, we propose a general Bilevel Clustering Optimization (BCO) framework to improve the performance of clustering. And then we introduce three special cases on subspace clustering with two different types of masks. At first, we reformulate the original subspace clustering as a Basic Masked Subspace Clustering (BMSC), which reformulate the diagonal constraints to a hard mask. Then, we provide a General Masked Subspace Clustering (GMSC) method to integrate different clustering via a soft mask. Furthermore, based on BCO and GMSC, we induce a learnable soft mask and design a Recursive Masked Subspace Clustering (RMSC) method that can alternately update the affinity matrix and the soft mask. Numerical experiments show that our models obtain significant improvement compared with the baselines on several commonly used datasets, such as MNIST, USPS, ORL, COIL20 and COIL100.
Deep Learning with Data Privacy via Residual Perturbation
Aug 11, 2024Protecting data privacy in deep learning (DL) is of crucial importance. Several celebrated privacy notions have been established and used for privacy-preserving DL. However, many existing mechanisms achieve privacy at the cost of significant utility degradation and computational overhead. In this paper, we propose a stochastic differential equation-based residual perturbation for privacy-preserving DL, which injects Gaussian noise into each residual mapping of ResNets. Theoretically, we prove that residual perturbation guarantees differential privacy (DP) and reduces the generalization gap of DL. Empirically, we show that residual perturbation is computationally efficient and outperforms the state-of-the-art differentially private stochastic gradient descent (DPSGD) in utility maintenance without sacrificing membership privacy.
Fast and Scalable Semi-Supervised Learning for Multi-View Subspace Clustering
Aug 11, 2024
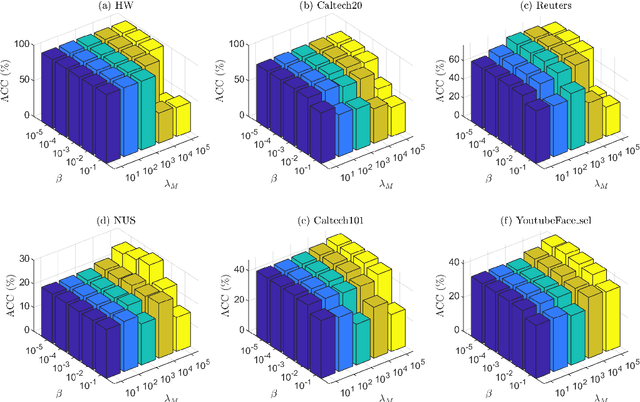
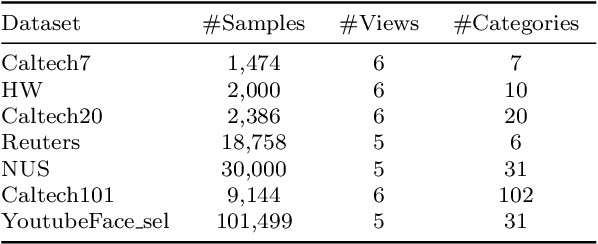
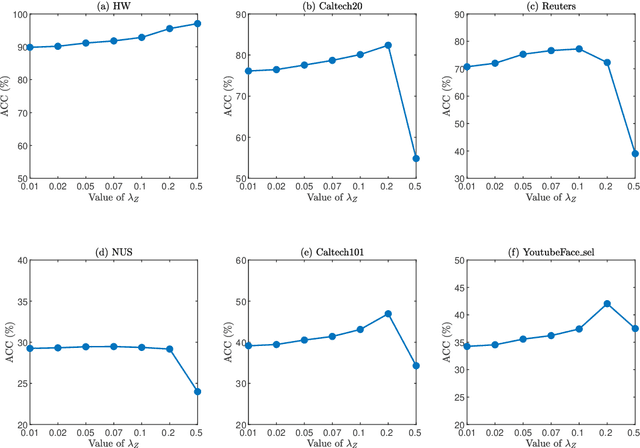
In this paper, we introduce a Fast and Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) method, a novel solution to the high computational complexity commonly found in existing approaches. FSSMSC features linear computational and space complexity relative to the size of the data. The method generates a consensus anchor graph across all views, representing each data point as a sparse linear combination of chosen landmarks. Unlike traditional methods that manage the anchor graph construction and the label propagation process separately, this paper proposes a unified optimization model that facilitates simultaneous learning of both. An effective alternating update algorithm with convergence guarantees is proposed to solve the unified optimization model. Additionally, the method employs the obtained anchor graph and landmarks' low-dimensional representations to deduce low-dimensional representations for raw data. Following this, a straightforward clustering approach is conducted on these low-dimensional representations to achieve the final clustering results. The effectiveness and efficiency of FSSMSC are validated through extensive experiments on multiple benchmark datasets of varying scales.
Semi-Supervised Clustering via Dynamic Graph Structure Learning
Sep 06, 2022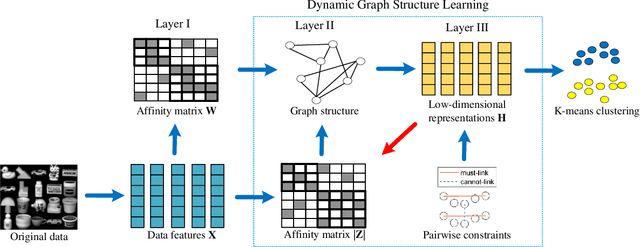

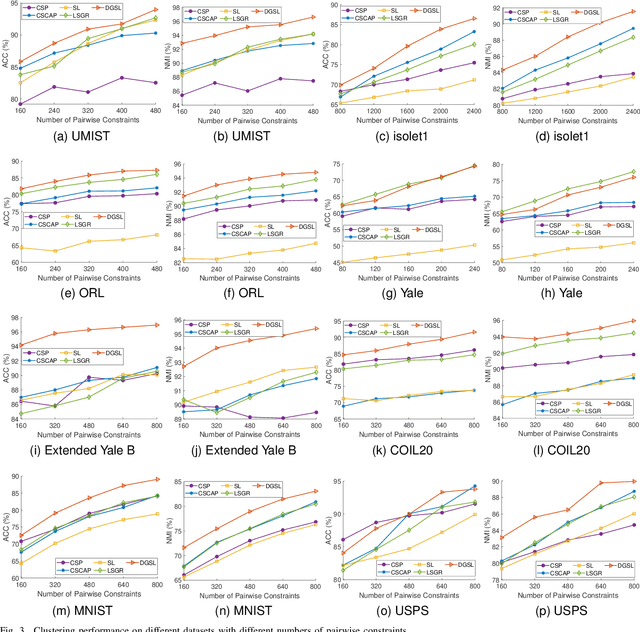
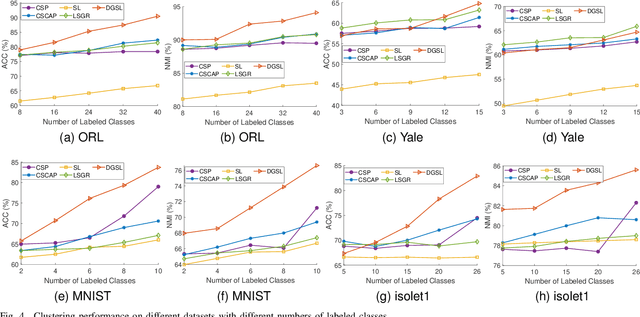
Most existing semi-supervised graph-based clustering methods exploit the supervisory information by either refining the affinity matrix or directly constraining the low-dimensional representations of data points. The affinity matrix represents the graph structure and is vital to the performance of semi-supervised graph-based clustering. However, existing methods adopt a static affinity matrix to learn the low-dimensional representations of data points and do not optimize the affinity matrix during the learning process. In this paper, we propose a novel dynamic graph structure learning method for semi-supervised clustering. In this method, we simultaneously optimize the affinity matrix and the low-dimensional representations of data points by leveraging the given pairwise constraints. Moreover, we propose an alternating minimization approach with proven convergence to solve the proposed nonconvex model. During the iteration process, our method cyclically updates the low-dimensional representations of data points and refines the affinity matrix, leading to a dynamic affinity matrix (graph structure). Specifically, for the update of the affinity matrix, we enforce the data points with remarkably different low-dimensional representations to have an affinity value of 0. Furthermore, we construct the initial affinity matrix by integrating the local distance and global self-representation among data points. Experimental results on eight benchmark datasets under different settings show the advantages of the proposed approach.
Training Deep Neural Networks with Adaptive Momentum Inspired by the Quadratic Optimization
Oct 18, 2021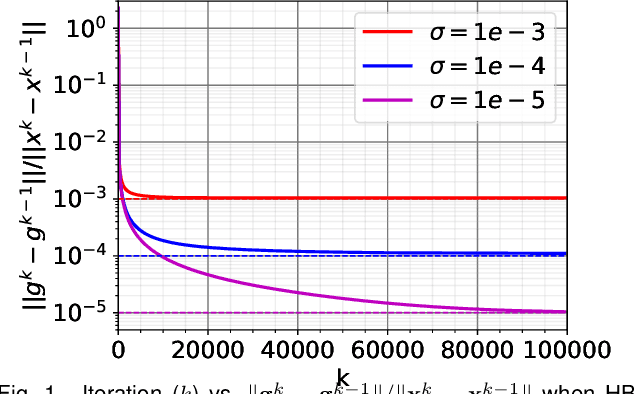


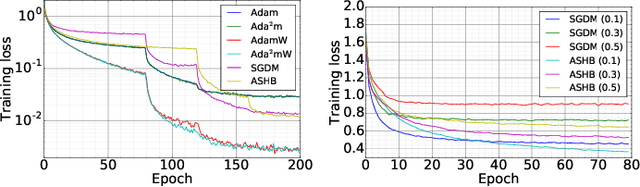
Heavy ball momentum is crucial in accelerating (stochastic) gradient-based optimization algorithms for machine learning. Existing heavy ball momentum is usually weighted by a uniform hyperparameter, which relies on excessive tuning. Moreover, the calibrated fixed hyperparameter may not lead to optimal performance. In this paper, to eliminate the effort for tuning the momentum-related hyperparameter, we propose a new adaptive momentum inspired by the optimal choice of the heavy ball momentum for quadratic optimization. Our proposed adaptive heavy ball momentum can improve stochastic gradient descent (SGD) and Adam. SGD and Adam with the newly designed adaptive momentum are more robust to large learning rates, converge faster, and generalize better than the baselines. We verify the efficiency of SGD and Adam with the new adaptive momentum on extensive machine learning benchmarks, including image classification, language modeling, and machine translation. Finally, we provide convergence guarantees for SGD and Adam with the proposed adaptive momentum.