 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeES-dLLM: Efficient Inference for Diffusion Large Language Models by Early-Skipping
Mar 10, 2026Diffusion large language models (dLLMs) are emerging as a promising alternative to autoregressive models (ARMs) due to their ability to capture bidirectional context and the potential for parallel generation. Despite the advantages, dLLM inference remains computationally expensive as the full input context is processed at every iteration. In this work, we analyze the generation dynamics of dLLMs and find that intermediate representations, including key, value, and hidden states, change only subtly across successive iterations. Leveraging this insight, we propose \textbf{ES-dLLM}, a training-free inference acceleration framework for dLLM that reduces computation by skipping tokens in early layers based on the estimated importance. Token importance is computed with intermediate tensor variation and confidence scores of previous iterations. Experiments on LLaDA-8B and Dream-7B demonstrate that ES-dLLM achieves throughput of up to 226.57 and 308.51 tokens per second (TPS), respectively, on an NVIDIA H200 GPU, delivering 5.6$\times$ to 16.8$\times$ speedup over the vanilla implementation and up to 1.85$\times$ over the state-of-the-art caching method, while preserving generation quality.
Finding the Task-Optimal Low-Bit Sub-Distribution in Deep Neural Networks
Jan 13, 2022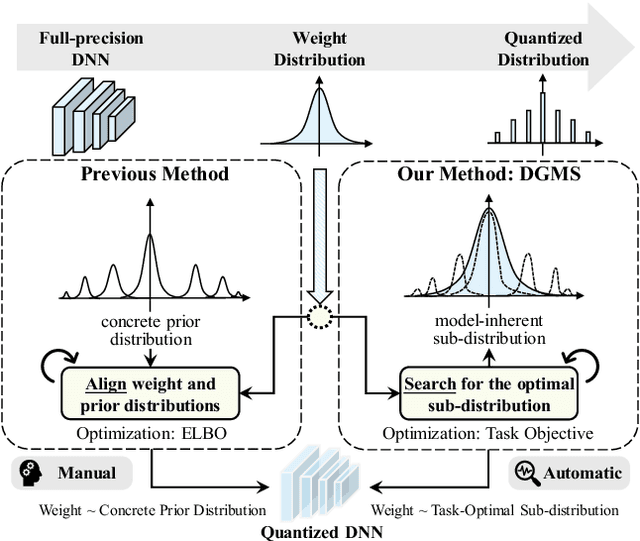
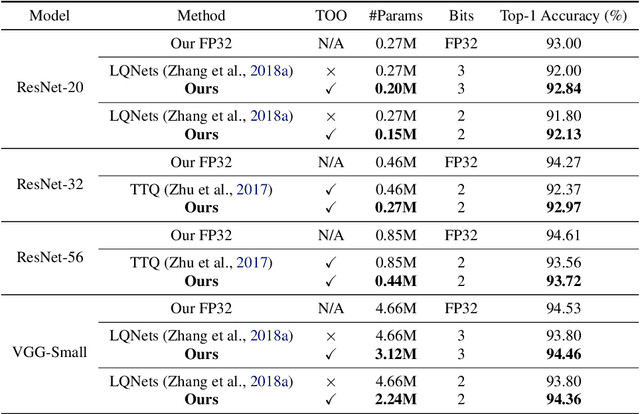
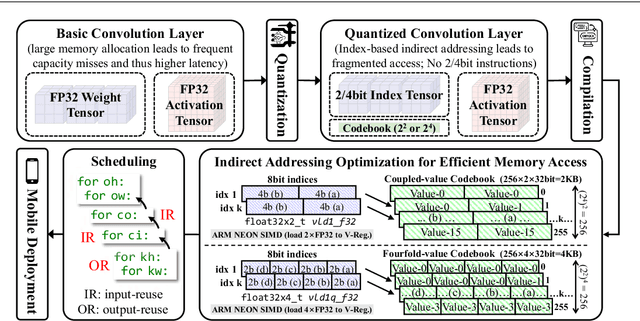
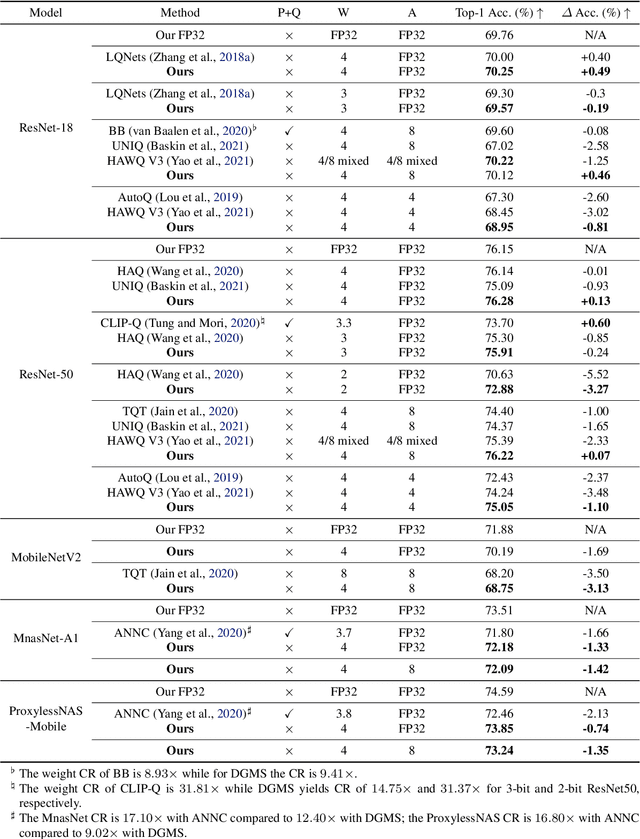
Quantized neural networks typically require smaller memory footprints and lower computation complexity, which is crucial for efficient deployment. However, quantization inevitably leads to a distribution divergence from the original network, which generally degrades the performance. To tackle this issue, massive efforts have been made, but most existing approaches lack statistical considerations and depend on several manual configurations. In this paper, we present an adaptive-mapping quantization method to learn an optimal latent sub-distribution that is inherent within models and smoothly approximated with a concrete Gaussian Mixture (GM). In particular, the network weights are projected in compliance with the GM-approximated sub-distribution. This sub-distribution evolves along with the weight update in a co-tuning schema guided by the direct task-objective optimization. Sufficient experiments on image classification and object detection over various modern architectures demonstrate the effectiveness, generalization property, and transferability of the proposed method. Besides, an efficient deployment flow for the mobile CPU is developed, achieving up to 7.46$\times$ inference acceleration on an octa-core ARM CPU. Codes have been publicly released on Github (https://github.com/RunpeiDong/DGMS).
PCNN: Pattern-based Fine-Grained Regular Pruning towards Optimizing CNN Accelerators
Feb 11, 2020
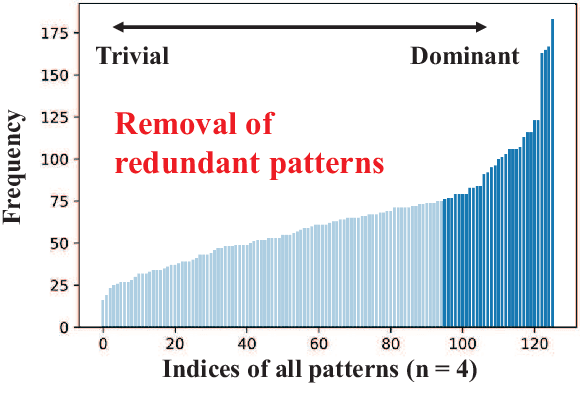
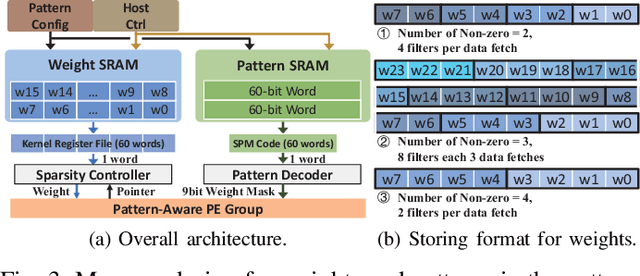
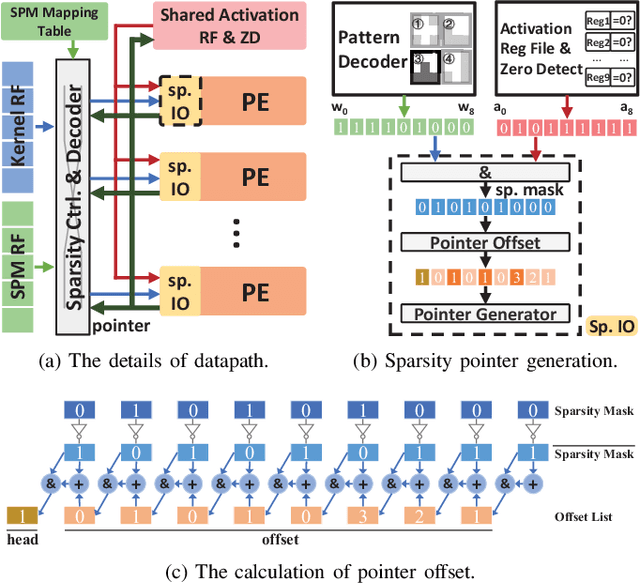
Weight pruning is a powerful technique to realize model compression. We propose PCNN, a fine-grained regular 1D pruning method. A novel index format called Sparsity Pattern Mask (SPM) is presented to encode the sparsity in PCNN. Leveraging SPM with limited pruning patterns and non-zero sequences with equal length, PCNN can be efficiently employed in hardware. Evaluated on VGG-16 and ResNet-18, our PCNN achieves the compression rate up to 8.4X with only 0.2% accuracy loss. We also implement a pattern-aware architecture in 55nm process, achieving up to 9.0X speedup and 28.39 TOPS/W efficiency with only 3.1% on-chip memory overhead of indices.
SCAN: A Scalable Neural Networks Framework Towards Compact and Efficient Models
May 27, 2019
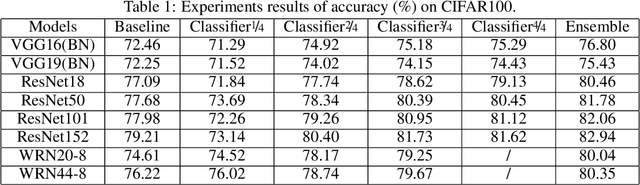
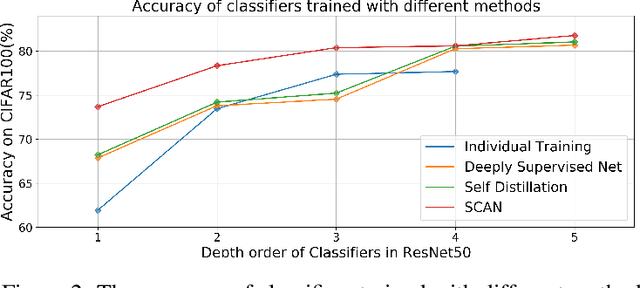
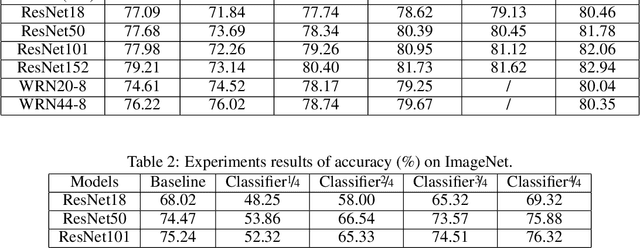
Remarkable achievements have been attained by deep neural networks in various applications. However, the increasing depth and width of such models also lead to explosive growth in both storage and computation, which has restricted the deployment of deep neural networks on resource-limited edge devices. To address this problem, we propose the so-called SCAN framework for networks training and inference, which is orthogonal and complementary to existing acceleration and compression methods. The proposed SCAN firstly divides neural networks into multiple sections according to their depth and constructs shallow classifiers upon the intermediate features of different sections. Moreover, attention modules and knowledge distillation are utilized to enhance the accuracy of shallow classifiers. Based on this architecture, we further propose a threshold controlled scalable inference mechanism to approach human-like sample-specific inference. Experimental results show that SCAN can be easily equipped on various neural networks without any adjustment on hyper-parameters or neural networks architectures, yielding significant performance gain on CIFAR100 and ImageNet. Codes will be released on github soon.