 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIMNet: A Parallel, Iterative and Mimicking Network for Scene Text Recognition
Paper and Code
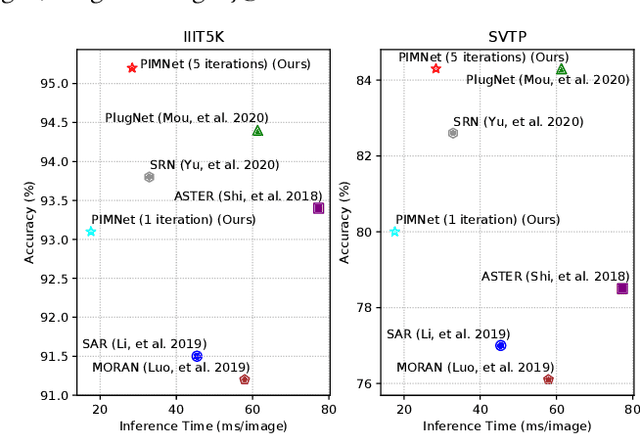
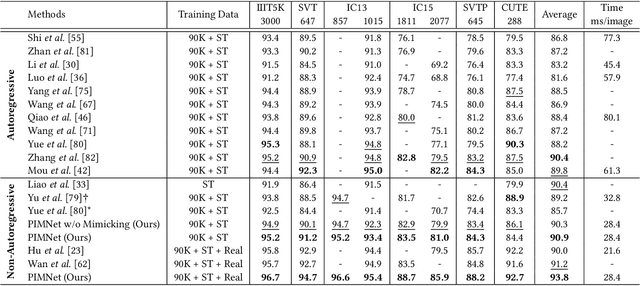
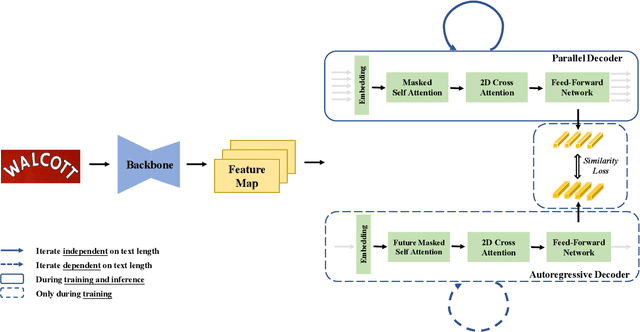

Nowadays, scene text recognition has attracted more and more attention due to its various applications. Most state-of-the-art methods adopt an encoder-decoder framework with attention mechanism, which generates text autoregressively from left to right. Despite the convincing performance, the speed is limited because of the one-by-one decoding strategy. As opposed to autoregressive models, non-autoregressive models predict the results in parallel with a much shorter inference time, but the accuracy falls behind the autoregressive counterpart considerably. In this paper, we propose a Parallel, Iterative and Mimicking Network (PIMNet) to balance accuracy and efficiency. Specifically, PIMNet adopts a parallel attention mechanism to predict the text faster and an iterative generation mechanism to make the predictions more accurate. In each iteration, the context information is fully explored. To improve learning of the hidden layer, we exploit the mimicking learning in the training phase, where an additional autoregressive decoder is adopted and the parallel decoder mimics the autoregressive decoder with fitting outputs of the hidden layer. With the shared backbone between the two decoders, the proposed PIMNet can be trained end-to-end without pre-training. During inference, the branch of the autoregressive decoder is removed for a faster speed. Extensive experiments on public benchmarks demonstrate the effectiveness and efficiency of PIMNet. Our code will be available at https://github.com/Pay20Y/PIMNet.