 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional skip-frame prediction for video anomaly detection with intra-domain disparity-driven attention
Jul 23, 2024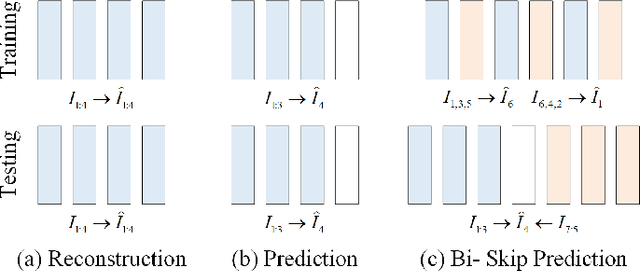
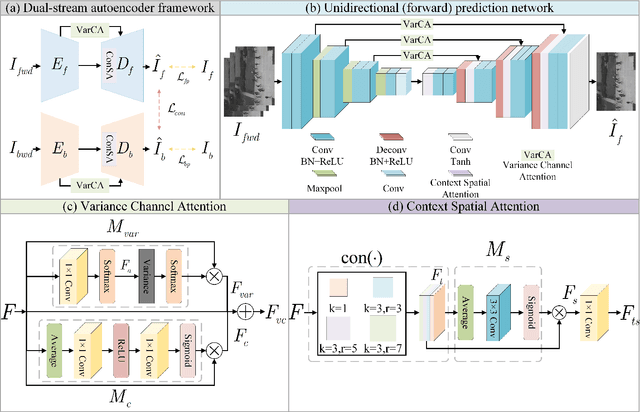

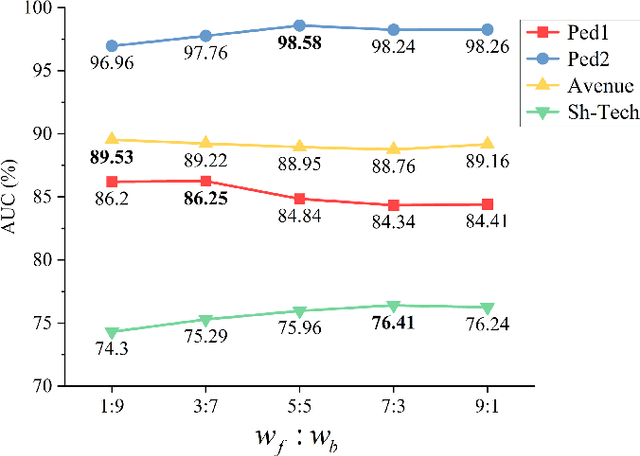
With the widespread deployment of video surveillance devices and the demand for intelligent system development, video anomaly detection (VAD) has become an important part of constructing intelligent surveillance systems. Expanding the discriminative boundary between normal and abnormal events to enhance performance is the common goal and challenge of VAD. To address this problem, we propose a Bidirectional Skip-frame Prediction (BiSP) network based on a dual-stream autoencoder, from the perspective of learning the intra-domain disparity between different features. The BiSP skips frames in the training phase to achieve the forward and backward frame prediction respectively, and in the testing phase, it utilizes bidirectional consecutive frames to co-predict the same intermediate frames, thus expanding the degree of disparity between normal and abnormal events. The BiSP designs the variance channel attention and context spatial attention from the perspectives of movement patterns and object scales, respectively, thus ensuring the maximization of the disparity between normal and abnormal in the feature extraction and delivery with different dimensions. Extensive experiments from four benchmark datasets demonstrate the effectiveness of the proposed BiSP, which substantially outperforms state-of-the-art competing methods.
Sparse Generation: Making Pseudo Labels Sparse for weakly supervision with points
Mar 28, 2024



In recent years, research on point weakly supervised object detection (PWSOD) methods in the field of computer vision has attracted people's attention. However, existing pseudo labels generation methods perform poorly in a small amount of supervised annotation data and dense object detection tasks. We consider the generation of weakly supervised pseudo labels as the result of model's sparse output, and propose a method called Sparse Generation to make pseudo labels sparse. It constructs dense tensors through the relationship between data and detector model, optimizes three of its parameters, and obtains a sparse tensor via coordinated calculation, thereby indirectly obtaining higher quality pseudo labels, and solving the model's density problem in the situation of only a small amount of supervised annotation data can be used. On two broadly used open-source datasets (RSOD, SIMD) and a self-built dataset (Bullet-Hole), the experimental results showed that the proposed method has a significant advantage in terms of overall performance metrics, comparing to that state-of-the-art method.