 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefAny3D: 3D Asset-Referenced Diffusion Models for Image Generation
Jan 29, 2026In this paper, we propose a 3D asset-referenced diffusion model for image generation, exploring how to integrate 3D assets into image diffusion models. Existing reference-based image generation methods leverage large-scale pretrained diffusion models and demonstrate strong capability in generating diverse images conditioned on a single reference image. However, these methods are limited to single-image references and cannot leverage 3D assets, constraining their practical versatility. To address this gap, we present a cross-domain diffusion model with dual-branch perception that leverages multi-view RGB images and point maps of 3D assets to jointly model their colors and canonical-space coordinates, achieving precise consistency between generated images and the 3D references. Our spatially aligned dual-branch generation architecture and domain-decoupled generation mechanism ensure the simultaneous generation of two spatially aligned but content-disentangled outputs, RGB images and point maps, linking 2D image attributes with 3D asset attributes. Experiments show that our approach effectively uses 3D assets as references to produce images consistent with the given assets, opening new possibilities for combining diffusion models with 3D content creation.
Adaptive Part Learning for Fine-Grained Generalized Category Discovery: A Plug-and-Play Enhancement
Jul 09, 2025Generalized Category Discovery (GCD) aims to recognize unlabeled images from known and novel classes by distinguishing novel classes from known ones, while also transferring knowledge from another set of labeled images with known classes. Existing GCD methods rely on self-supervised vision transformers such as DINO for representation learning. However, focusing solely on the global representation of the DINO CLS token introduces an inherent trade-off between discriminability and generalization. In this paper, we introduce an adaptive part discovery and learning method, called APL, which generates consistent object parts and their correspondences across different similar images using a set of shared learnable part queries and DINO part priors, without requiring any additional annotations. More importantly, we propose a novel all-min contrastive loss to learn discriminative yet generalizable part representation, which adaptively highlights discriminative object parts to distinguish similar categories for enhanced discriminability while simultaneously sharing other parts to facilitate knowledge transfer for improved generalization. Our APL can easily be incorporated into different GCD frameworks by replacing their CLS token feature with our part representations, showing significant enhancements on fine-grained datasets.
MVTokenFlow: High-quality 4D Content Generation using Multiview Token Flow
Feb 17, 2025In this paper, we present MVTokenFlow for high-quality 4D content creation from monocular videos. Recent advancements in generative models such as video diffusion models and multiview diffusion models enable us to create videos or 3D models. However, extending these generative models for dynamic 4D content creation is still a challenging task that requires the generated content to be consistent spatially and temporally. To address this challenge, MVTokenFlow utilizes the multiview diffusion model to generate multiview images on different timesteps, which attains spatial consistency across different viewpoints and allows us to reconstruct a reasonable coarse 4D field. Then, MVTokenFlow further regenerates all the multiview images using the rendered 2D flows as guidance. The 2D flows effectively associate pixels from different timesteps and improve the temporal consistency by reusing tokens in the regeneration process. Finally, the regenerated images are spatiotemporally consistent and utilized to refine the coarse 4D field to get a high-quality 4D field. Experiments demonstrate the effectiveness of our design and show significantly improved quality than baseline methods.
Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator
Sep 25, 2023
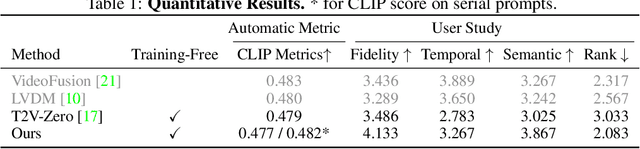
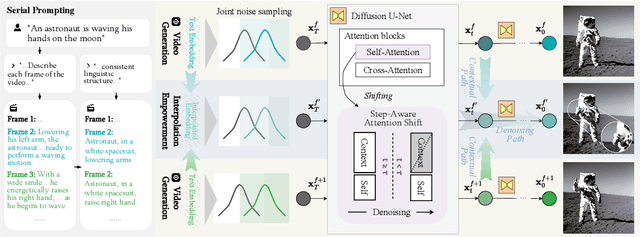

Text-to-video is a rapidly growing research area that aims to generate a semantic, identical, and temporal coherence sequence of frames that accurately align with the input text prompt. This study focuses on zero-shot text-to-video generation considering the data- and cost-efficient. To generate a semantic-coherent video, exhibiting a rich portrayal of temporal semantics such as the whole process of flower blooming rather than a set of "moving images", we propose a novel Free-Bloom pipeline that harnesses large language models (LLMs) as the director to generate a semantic-coherence prompt sequence, while pre-trained latent diffusion models (LDMs) as the animator to generate the high fidelity frames. Furthermore, to ensure temporal and identical coherence while maintaining semantic coherence, we propose a series of annotative modifications to adapting LDMs in the reverse process, including joint noise sampling, step-aware attention shift, and dual-path interpolation. Without any video data and training requirements, Free-Bloom generates vivid and high-quality videos, awe-inspiring in generating complex scenes with semantic meaningful frame sequences. In addition, Free-Bloom is naturally compatible with LDMs-based extensions.