 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-CFL: Privacy-Adaptive Clustered Federated Learning for Transformer-Based Sales Forecasting on Heterogeneous Retail Data
Mar 21, 2025Federated learning (FL) enables retailers to share model parameters for demand forecasting while maintaining privacy. However, heterogeneous data across diverse regions, driven by factors such as varying consumer behavior, poses challenges to the effectiveness of federated learning. To tackle this challenge, we propose Privacy-Adaptive Clustered Federated Learning (PA-CFL) tailored for demand forecasting on heterogeneous retail data. By leveraging differential privacy and feature importance distribution, PA-CFL groups retailers into distinct ``bubbles'', each forming its own federated learning system to effectively isolate data heterogeneity. Within each bubble, Transformer models are designed to predict local sales for each client. Our experiments demonstrate that PA-CFL significantly surpasses FedAvg and outperforms local learning in demand forecasting performance across all participating clients. Compared to local learning, PA-CFL achieves a 5.4% improvement in R^2, a 69% reduction in RMSE, and a 45% decrease in MAE. Our approach enables effective FL through adaptive adjustments to diverse noise levels and the range of clients participating in each bubble. By grouping participants and proactively filtering out high-risk clients, PA-CFL mitigates potential threats to the FL system. The findings demonstrate PA-CFL's ability to enhance federated learning in time series prediction tasks with heterogeneous data, achieving a balance between forecasting accuracy and privacy preservation in retail applications. Additionally, PA-CFL's capability to detect and neutralize poisoned data from clients enhances the system's robustness and reliability.
A Bubble-Cluster Federated Learning Framework for Privacy-Preserving Demand Forecasting on Heterogeneous Retail Data
Mar 15, 2025Federated learning (FL) enables retailers to share model parameters for demand forecasting while maintaining privacy. However, heterogeneous data across diverse regions, driven by factors such as varying consumer behavior, poses challenges to the effectiveness of federated learning. To tackle this challenge, we propose Bubble-Cluster Federated Learning (BFL), a novel clustering-based federated learning framework tailored for sales prediction. By leveraging differential privacy and feature importance distribution, BFL groups retailers into distinct "bubbles", each forming its own federated learning (FL) system to effectively isolate data heterogeneity. Within each bubble, Transformer models are designed to predict local sales for each client. Our experiments demonstrate that BFL significantly surpasses FedAvg and outperforms local learning in demand forecasting performance across all participating clients. Compared to local learning, BFL can achieve a 5.4\% improvement in R\textsuperscript{2}, a 69\% reduction in RMSE, and a 45\% decrease in MAE. Our study highlights BFL's adaptability in enabling effective federated learning through dynamic adjustments to noise levels and the range of clients participating in each bubble. This approach strategically groups participants into distinct "bubbles" while proactively identifying and filtering out risky clients that could compromise the FL system. The findings demonstrate BFL's ability to enhance collaborative learning in regression tasks on heterogeneous data, achieving a balance between forecasting accuracy and privacy preservation in retail applications. Additionally, BFL's capability to detect and neutralize poisoned data from clients enhances the system's robustness and reliability, ensuring more secure and effective federated learning.
MVTokenFlow: High-quality 4D Content Generation using Multiview Token Flow
Feb 17, 2025In this paper, we present MVTokenFlow for high-quality 4D content creation from monocular videos. Recent advancements in generative models such as video diffusion models and multiview diffusion models enable us to create videos or 3D models. However, extending these generative models for dynamic 4D content creation is still a challenging task that requires the generated content to be consistent spatially and temporally. To address this challenge, MVTokenFlow utilizes the multiview diffusion model to generate multiview images on different timesteps, which attains spatial consistency across different viewpoints and allows us to reconstruct a reasonable coarse 4D field. Then, MVTokenFlow further regenerates all the multiview images using the rendered 2D flows as guidance. The 2D flows effectively associate pixels from different timesteps and improve the temporal consistency by reusing tokens in the regeneration process. Finally, the regenerated images are spatiotemporally consistent and utilized to refine the coarse 4D field to get a high-quality 4D field. Experiments demonstrate the effectiveness of our design and show significantly improved quality than baseline methods.
DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models
Oct 26, 2023A long-standing goal of AI systems is to perform complex multimodal reasoning like humans. Recently, large language models (LLMs) have made remarkable strides in such multi-step reasoning on the language modality solely by leveraging the chain of thought (CoT) to mimic human thinking. However, the transfer of these advancements to multimodal contexts introduces heightened challenges, including but not limited to the impractical need for labor-intensive annotation and the limitations in terms of flexibility, generalizability, and explainability. To evoke CoT reasoning in multimodality, this work first conducts an in-depth analysis of these challenges posed by multimodality and presents two key insights: "keeping critical thinking" and "letting everyone do their jobs" in multimodal CoT reasoning. Furthermore, this study proposes a novel DDCoT prompting that maintains a critical attitude through negative-space prompting and incorporates multimodality into reasoning by first dividing the reasoning responsibility of LLMs into reasoning and recognition and then integrating the visual recognition capability of visual models into the joint reasoning process. The rationales generated by DDCoT not only improve the reasoning abilities of both large and small language models in zero-shot prompting and fine-tuning learning, significantly outperforming state-of-the-art methods but also exhibit impressive generalizability and explainability.
Temporal Collection and Distribution for Referring Video Object Segmentation
Sep 07, 2023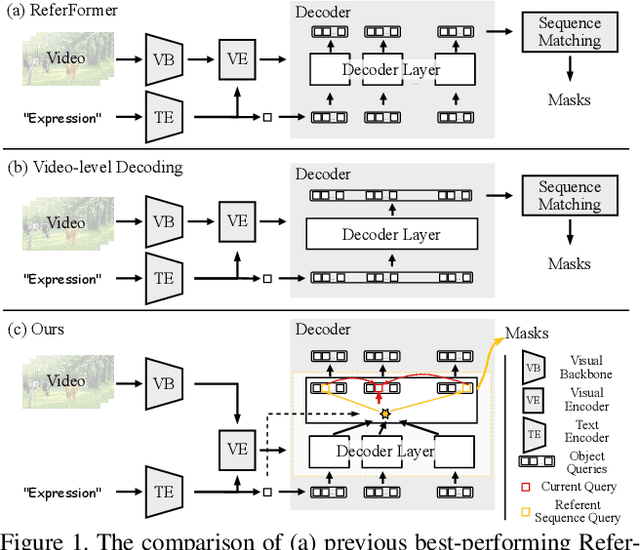



Referring video object segmentation aims to segment a referent throughout a video sequence according to a natural language expression. It requires aligning the natural language expression with the objects' motions and their dynamic associations at the global video level but segmenting objects at the frame level. To achieve this goal, we propose to simultaneously maintain a global referent token and a sequence of object queries, where the former is responsible for capturing video-level referent according to the language expression, while the latter serves to better locate and segment objects with each frame. Furthermore, to explicitly capture object motions and spatial-temporal cross-modal reasoning over objects, we propose a novel temporal collection-distribution mechanism for interacting between the global referent token and object queries. Specifically, the temporal collection mechanism collects global information for the referent token from object queries to the temporal motions to the language expression. In turn, the temporal distribution first distributes the referent token to the referent sequence across all frames and then performs efficient cross-frame reasoning between the referent sequence and object queries in every frame. Experimental results show that our method outperforms state-of-the-art methods on all benchmarks consistently and significantly.
CoTDet: Affordance Knowledge Prompting for Task Driven Object Detection
Sep 03, 2023



Task driven object detection aims to detect object instances suitable for affording a task in an image. Its challenge lies in object categories available for the task being too diverse to be limited to a closed set of object vocabulary for traditional object detection. Simply mapping categories and visual features of common objects to the task cannot address the challenge. In this paper, we propose to explore fundamental affordances rather than object categories, i.e., common attributes that enable different objects to accomplish the same task. Moreover, we propose a novel multi-level chain-of-thought prompting (MLCoT) to extract the affordance knowledge from large language models, which contains multi-level reasoning steps from task to object examples to essential visual attributes with rationales. Furthermore, to fully exploit knowledge to benefit object recognition and localization, we propose a knowledge-conditional detection framework, namely CoTDet. It conditions the detector from the knowledge to generate object queries and regress boxes. Experimental results demonstrate that our CoTDet outperforms state-of-the-art methods consistently and significantly (+15.6 box AP and +14.8 mask AP) and can generate rationales for why objects are detected to afford the task.
Contrastive Grouping with Transformer for Referring Image Segmentation
Sep 02, 2023Referring image segmentation aims to segment the target referent in an image conditioning on a natural language expression. Existing one-stage methods employ per-pixel classification frameworks, which attempt straightforwardly to align vision and language at the pixel level, thus failing to capture critical object-level information. In this paper, we propose a mask classification framework, Contrastive Grouping with Transformer network (CGFormer), which explicitly captures object-level information via token-based querying and grouping strategy. Specifically, CGFormer first introduces learnable query tokens to represent objects and then alternately queries linguistic features and groups visual features into the query tokens for object-aware cross-modal reasoning. In addition, CGFormer achieves cross-level interaction by jointly updating the query tokens and decoding masks in every two consecutive layers. Finally, CGFormer cooperates contrastive learning to the grouping strategy to identify the token and its mask corresponding to the referent. Experimental results demonstrate that CGFormer outperforms state-of-the-art methods in both segmentation and generalization settings consistently and significantly.