 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation
Dec 05, 2024



This paper introduces the counter-intuitive generalization results of overfitting pre-trained large language models (LLMs) on very small datasets. In the setting of open-ended text generation, it is well-documented that LLMs tend to generate repetitive and dull sequences, a phenomenon that is especially apparent when generating using greedy decoding. This issue persists even with state-of-the-art LLMs containing billions of parameters, trained via next-token prediction on large datasets. We find that by further fine-tuning these models to achieve a near-zero training loss on a small set of samples -- a process we refer to as hyperfitting -- the long-sequence generative capabilities are greatly enhanced. Greedy decoding with these Hyperfitted models even outperform Top-P sampling over long-sequences, both in terms of diversity and human preferences. This phenomenon extends to LLMs of various sizes, different domains, and even autoregressive image generation. We further find this phenomena to be distinctly different from that of Grokking and double descent. Surprisingly, our experiments indicate that hyperfitted models rarely fall into repeating sequences they were trained on, and even explicitly blocking these sequences results in high-quality output. All hyperfitted models produce extremely low-entropy predictions, often allocating nearly all probability to a single token.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.
Should we Stop Training More Monolingual Models, and Simply Use Machine Translation Instead?
Apr 21, 2021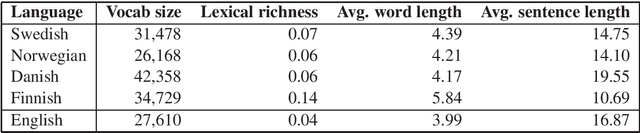


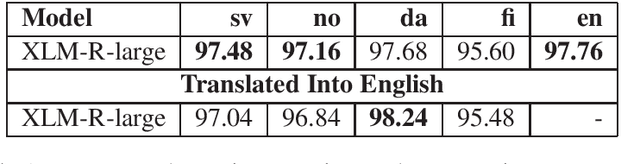
Most work in NLP makes the assumption that it is desirable to develop solutions in the native language in question. There is consequently a strong trend towards building native language models even for low-resource languages. This paper questions this development, and explores the idea of simply translating the data into English, thereby enabling the use of pretrained, and large-scale, English language models. We demonstrate empirically that a large English language model coupled with modern machine translation outperforms native language models in most Scandinavian languages. The exception to this is Finnish, which we assume is due to inferior translation quality. Our results suggest that machine translation is a mature technology, which raises a serious counter-argument for training native language models for low-resource languages. This paper therefore strives to make a provocative but important point. As English language models are improving at an unprecedented pace, which in turn improves machine translation, it is from an empirical and environmental stand-point more effective to translate data from low-resource languages into English, than to build language models for such languages.
The Singleton Fallacy: Why Current Critiques of Language Models Miss the Point
Feb 08, 2021This paper discusses the current critique against neural network-based Natural Language Understanding (NLU) solutions known as language models. We argue that much of the current debate rests on an argumentation error that we will refer to as the singleton fallacy: the assumption that language, meaning, and understanding are single and uniform phenomena that are unobtainable by (current) language models. By contrast, we will argue that there are many different types of language use, meaning and understanding, and that (current) language models are build with the explicit purpose of acquiring and representing one type of structural understanding of language. We will argue that such structural understanding may cover several different modalities, and as such can handle several different types of meaning. Our position is that we currently see no theoretical reason why such structural knowledge would be insufficient to count as "real" understanding.