 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Detect Intrinsic Hallucinations in Paraphrasing and Machine Translation?
Apr 29, 2025A frequently observed problem with LLMs is their tendency to generate output that is nonsensical, illogical, or factually incorrect, often referred to broadly as hallucination. Building on the recently proposed HalluciGen task for hallucination detection and generation, we evaluate a suite of open-access LLMs on their ability to detect intrinsic hallucinations in two conditional generation tasks: translation and paraphrasing. We study how model performance varies across tasks and language and we investigate the impact of model size, instruction tuning, and prompt choice. We find that performance varies across models but is consistent across prompts. Finally, we find that NLI models perform comparably well, suggesting that LLM-based detectors are not the only viable option for this specific task.
A Study of Continual Learning Under Language Shift
Nov 02, 2023



The recent increase in data and model scale for language model pre-training has led to huge training costs. In scenarios where new data become available over time, updating a model instead of fully retraining it would therefore provide significant gains. In this paper, we study the benefits and downsides of updating a language model when new data comes from new languages - the case of continual learning under language shift. Starting from a monolingual English language model, we incrementally add data from Norwegian and Icelandic to investigate how forward and backward transfer effects depend on the pre-training order and characteristics of languages, for different model sizes and learning rate schedulers. Our results show that, while forward transfer is largely positive and independent of language order, backward transfer can be either positive or negative depending on the order and characteristics of new languages. To explain these patterns we explore several language similarity metrics and find that syntactic similarity appears to have the best correlation with our results.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.
Cross-lingual Transfer of Monolingual Models
Sep 15, 2021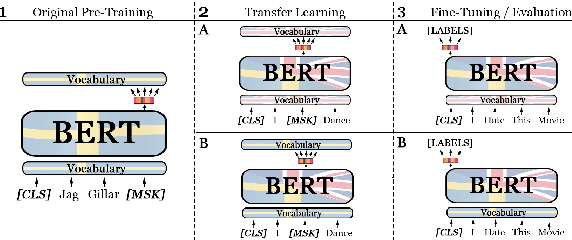
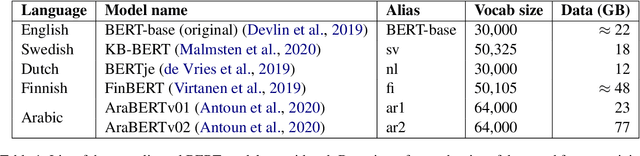
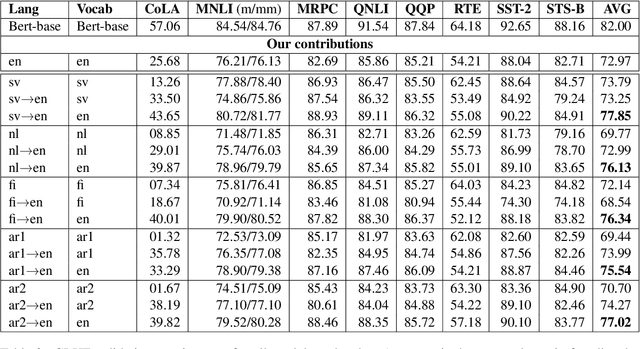
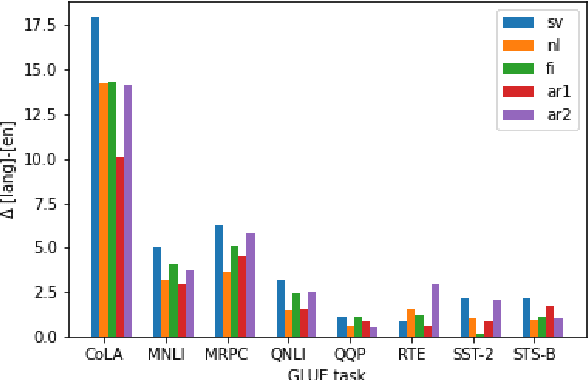
Recent studies in zero-shot cross-lingual learning using multilingual models have falsified the previous hypothesis that shared vocabulary and joint pre-training are the keys to cross-lingual generalization. Inspired by this advancement, we introduce a cross-lingual transfer method for monolingual models based on domain adaptation. We study the effects of such transfer from four different languages to English. Our experimental results on GLUE show that the transferred models outperform the native English model independently of the source language. After probing the English linguistic knowledge encoded in the representations before and after transfer, we find that semantic information is retained from the source language, while syntactic information is learned during transfer. Additionally, the results of evaluating the transferred models in source language tasks reveal that their performance in the source domain deteriorates after transfer.