 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiaSWE: An Expert Annotated Dataset for Misogyny Detection in Swedish
Feb 11, 2025In this study, we introduce the process for creating BiaSWE, an expert-annotated dataset tailored for misogyny detection in the Swedish language. To address the cultural and linguistic specificity of misogyny in Swedish, we collaborated with experts from the social sciences and humanities. Our interdisciplinary team developed a rigorous annotation process, incorporating both domain knowledge and language expertise, to capture the nuances of misogyny in a Swedish context. This methodology ensures that the dataset is not only culturally relevant but also aligned with broader efforts in bias detection for low-resource languages. The dataset, along with the annotation guidelines, is publicly available for further research.
SWEb: A Large Web Dataset for the Scandinavian Languages
Oct 06, 2024



This paper presents the hitherto largest pretraining dataset for the Scandinavian languages: the Scandinavian WEb (SWEb), comprising over one trillion tokens. The paper details the collection and processing pipeline, and introduces a novel model-based text extractor that significantly reduces complexity in comparison with rule-based approaches. We also introduce a new cloze-style benchmark for evaluating language models in Swedish, and use this test to compare models trained on the SWEb data to models trained on FineWeb, with competitive results. All data, models and code are shared openly.
Text Annotation Handbook: A Practical Guide for Machine Learning Projects
Oct 18, 2023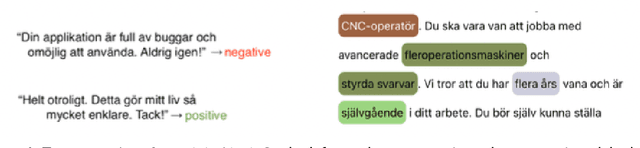
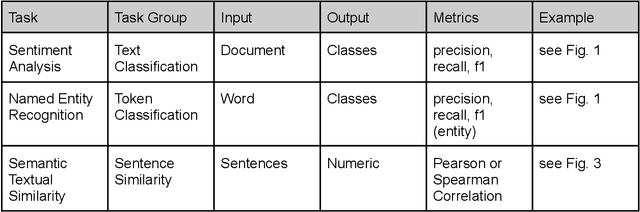
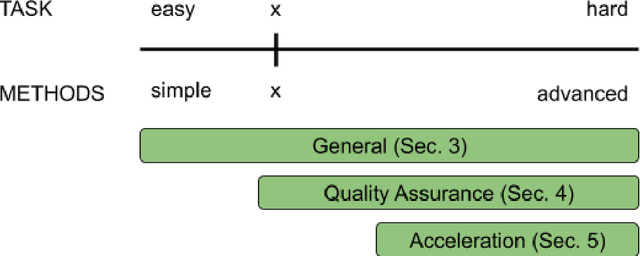

This handbook is a hands-on guide on how to approach text annotation tasks. It provides a gentle introduction to the topic, an overview of theoretical concepts as well as practical advice. The topics covered are mostly technical, but business, ethical and regulatory issues are also touched upon. The focus lies on readability and conciseness rather than completeness and scientific rigor. Experience with annotation and knowledge of machine learning are useful but not required. The document may serve as a primer or reference book for a wide range of professions such as team leaders, project managers, IT architects, software developers and machine learning engineers.