Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotated Job Ads with Named Entity Recognition
Oct 18, 2023
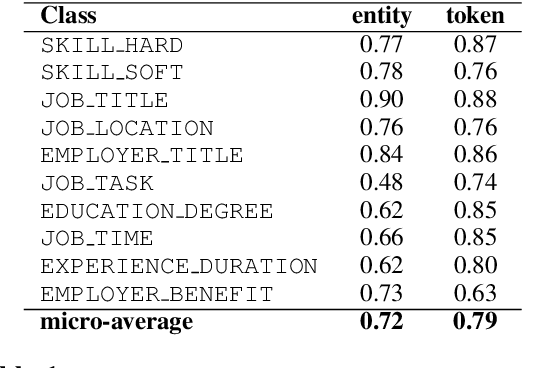
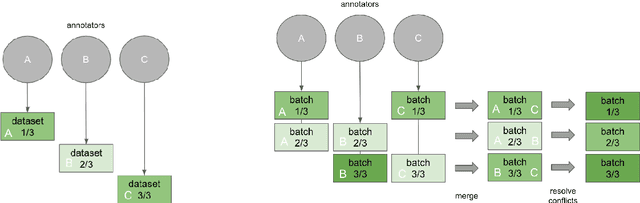

We have trained a named entity recognition (NER) model that screens Swedish job ads for different kinds of useful information (e.g. skills required from a job seeker). It was obtained by fine-tuning KB-BERT. The biggest challenge we faced was the creation of a labelled dataset, which required manual annotation. This paper gives an overview of the methods we employed to make the annotation process more efficient and to ensure high quality data. We also report on the performance of the resulting model.
* SLTC 2022
Via