 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Personality from Text: Challenges and Opportunities
Paper and Code
Oct 22, 2019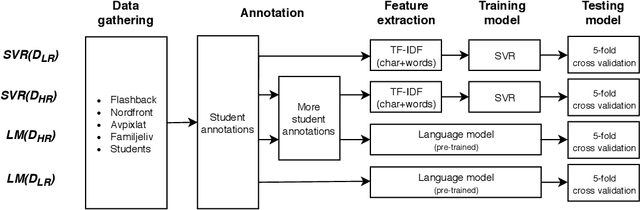


In this study, we examined the possibility to extract personality traits from a text. We created an extensive dataset by having experts annotate personality traits in a large number of texts from multiple online sources. From these annotated texts, we selected a sample and made further annotations ending up in a large low-reliability dataset and a small high-reliability dataset. We then used the two datasets to train and test several machine learning models to extract personality from text, including a language model. Finally, we evaluated our best models in the wild, on datasets from different domains. Our results show that the models based on the small high-reliability dataset performed better (in terms of $\textrm{R}^2$) than models based on large low-reliability dataset. Also, language model based on small high-reliability dataset performed better than the random baseline. Finally, and more importantly, the results showed our best model did not perform better than the random baseline when tested in the wild. Taken together, our results show that determining personality traits from a text remains a challenge and that no firm conclusions can be made on model performance before testing in the wild.