 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Adapt Pre-trained Vision-and-Language Models to a Text-only Input?
Paper and Code


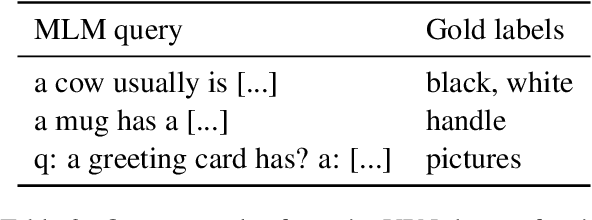
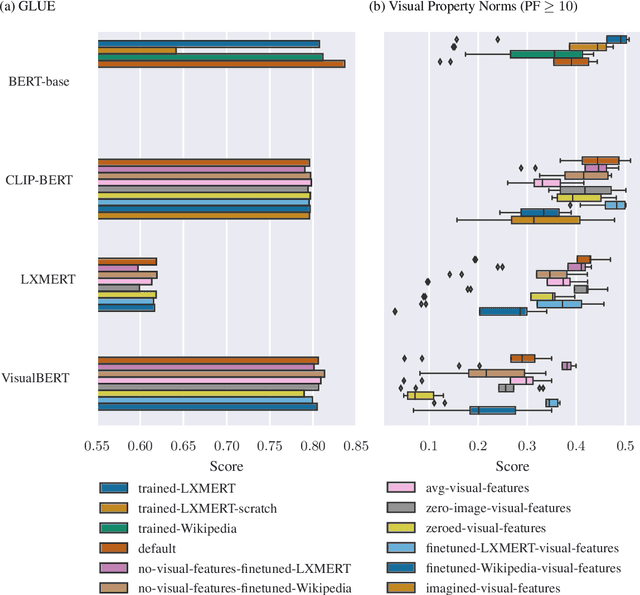
Current language models have been criticised for learning language from text alone without connection between words and their meaning. Consequently, multimodal training has been proposed as a way for creating models with better language understanding by providing the lacking connection. We focus on pre-trained multimodal vision-and-language (VL) models for which there already are some results on their language understanding capabilities. An unresolved issue with evaluating the linguistic skills of these models, however, is that there is no established method for adapting them to text-only input without out-of-distribution uncertainty. To find the best approach, we investigate and compare seven possible methods for adapting three different pre-trained VL models to text-only input. Our evaluations on both GLUE and Visual Property Norms (VPN) show that care should be put into adapting VL models to zero-shot text-only tasks, while the models are less sensitive to how we adapt them to non-zero-shot tasks. We also find that the adaptation methods perform differently for different models and that unimodal model counterparts perform on par with the VL models regardless of adaptation, indicating that current VL models do not necessarily gain better language understanding from their multimodal training.