 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA better method to enforce monotonic constraints in regression and classification trees
Paper and Code
Nov 02, 2020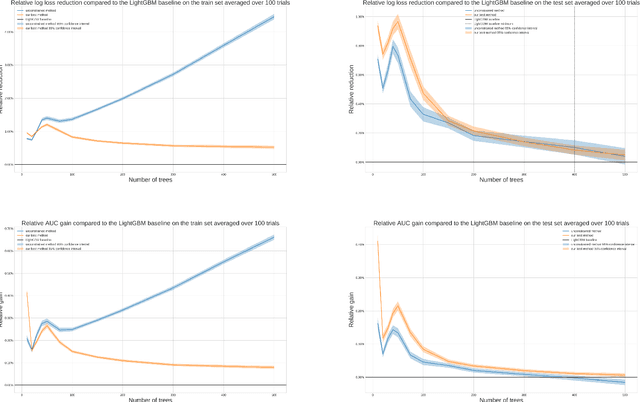
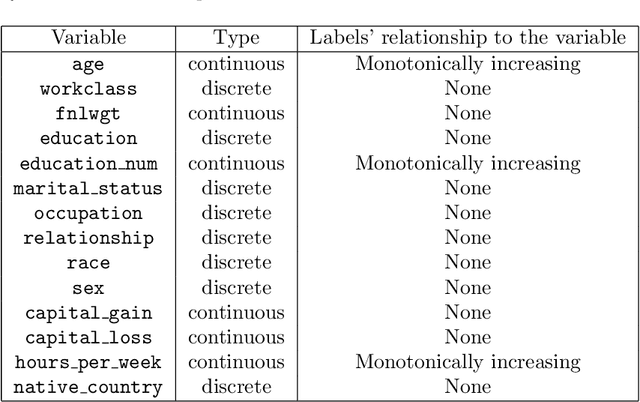

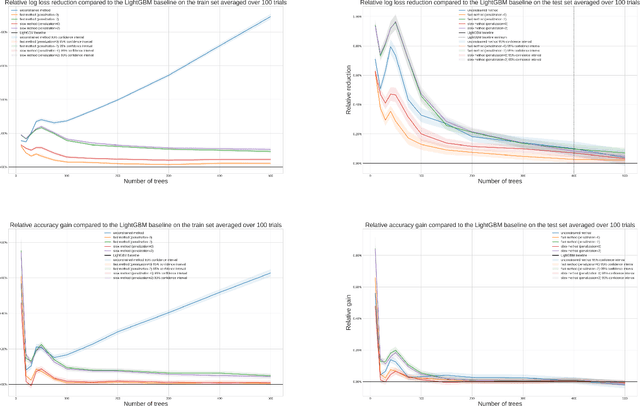
In this report we present two new ways of enforcing monotone constraints in regression and classification trees. One yields better results than the current LightGBM, and has a similar computation time. The other one yields even better results, but is much slower than the current LightGBM. We also propose a heuristic that takes into account that greedily splitting a tree by choosing a monotone split with respect to its immediate gain is far from optimal. Then, we compare the results with the current implementation of the constraints in the LightGBM library, using the well known Adult public dataset. Throughout the report, we mostly focus on the implementation of our methods that we made for the LightGBM library, even though they are general and could be implemented in any regression or classification tree. The best method we propose (a smarter way to split the tree coupled to a penalization of monotone splits) consistently beats the current implementation of LightGBM. With small or average trees, the loss reduction can be as high as 1% in the early stages of training and decreases to around 0.1% at the loss peak for the Adult dataset. The results would be even better with larger trees. In our experiments, we didn't do a lot of tuning of the regularization parameters, and we wouldn't be surprised to see that increasing the performance of our methods on test sets.