 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixFlow: Mixed Source Distributions Improve Rectified Flows
Apr 10, 2026Diffusion models and their variations, such as rectified flows, generate diverse and high-quality images, but they are still hindered by slow iterative sampling caused by the highly curved generative paths they learn. An important cause of high curvature, as shown by previous work, is independence between the source distribution (standard Gaussian) and the data distribution. In this work, we tackle this limitation by two complementary contributions. First, we attempt to break away from the standard Gaussian assumption by introducing $κ\texttt{-FC}$, a general formulation that conditions the source distribution on an arbitrary signal $κ$ that aligns it better with the data distribution. Then, we present MixFlow, a simple but effective training strategy that reduces the generative path curvatures and considerably improves sampling efficiency. MixFlow trains a flow model on linear mixtures of a fixed unconditional distribution and a $κ\texttt{-FC}$-based distribution. This simple mixture improves the alignment between the source and data, provides better generation quality with less required sampling steps, and accelerates the training convergence considerably. On average, our training procedure improves the generation quality by 12\% in FID compared to standard rectified flow and 7\% compared to previous baselines under a fixed sampling budget. Code available at: $\href{https://github.com/NazirNayal8/MixFlow}{https://github.com/NazirNayal8/MixFlow}$
SemanticNVS: Improving Semantic Scene Understanding in Generative Novel View Synthesis
Feb 23, 2026We present SemanticNVS, a camera-conditioned multi-view diffusion model for novel view synthesis (NVS), which improves generation quality and consistency by integrating pre-trained semantic feature extractors. Existing NVS methods perform well for views near the input view, however, they tend to generate semantically implausible and distorted images under long-range camera motion, revealing severe degradation. We speculate that this degradation is due to current models failing to fully understand their conditioning or intermediate generated scene content. Here, we propose to integrate pre-trained semantic feature extractors to incorporate stronger scene semantics as conditioning to achieve high-quality generation even at distant viewpoints. We investigate two different strategies, (1) warped semantic features and (2) an alternating scheme of understanding and generation at each denoising step. Experimental results on multiple datasets demonstrate the clear qualitative and quantitative (4.69%-15.26% in FID) improvement over state-of-the-art alternatives.
Spatial Reasoning with Denoising Models
Feb 28, 2025We introduce Spatial Reasoning Models (SRMs), a framework to perform reasoning over sets of continuous variables via denoising generative models. SRMs infer continuous representations on a set of unobserved variables, given observations on observed variables. Current generative models on spatial domains, such as diffusion and flow matching models, often collapse to hallucination in case of complex distributions. To measure this, we introduce a set of benchmark tasks that test the quality of complex reasoning in generative models and can quantify hallucination. The SRM framework allows to report key findings about importance of sequentialization in generation, the associated order, as well as the sampling strategies during training. It demonstrates, for the first time, that order of generation can successfully be predicted by the denoising network itself. Using these findings, we can increase the accuracy of specific reasoning tasks from <1% to >50%.
MEt3R: Measuring Multi-View Consistency in Generated Images
Jan 10, 2025We introduce MEt3R, a metric for multi-view consistency in generated images. Large-scale generative models for multi-view image generation are rapidly advancing the field of 3D inference from sparse observations. However, due to the nature of generative modeling, traditional reconstruction metrics are not suitable to measure the quality of generated outputs and metrics that are independent of the sampling procedure are desperately needed. In this work, we specifically address the aspect of consistency between generated multi-view images, which can be evaluated independently of the specific scene. Our approach uses DUSt3R to obtain dense 3D reconstructions from image pairs in a feed-forward manner, which are used to warp image contents from one view into the other. Then, feature maps of these images are compared to obtain a similarity score that is invariant to view-dependent effects. Using MEt3R, we evaluate the consistency of a large set of previous methods for novel view and video generation, including our open, multi-view latent diffusion model.
Spurfies: Sparse Surface Reconstruction using Local Geometry Priors
Aug 29, 2024



We introduce Spurfies, a novel method for sparse-view surface reconstruction that disentangles appearance and geometry information to utilize local geometry priors trained on synthetic data. Recent research heavily focuses on 3D reconstruction using dense multi-view setups, typically requiring hundreds of images. However, these methods often struggle with few-view scenarios. Existing sparse-view reconstruction techniques often rely on multi-view stereo networks that need to learn joint priors for geometry and appearance from a large amount of data. In contrast, we introduce a neural point representation that disentangles geometry and appearance to train a local geometry prior using a subset of the synthetic ShapeNet dataset only. During inference, we utilize this surface prior as additional constraint for surface and appearance reconstruction from sparse input views via differentiable volume rendering, restricting the space of possible solutions. We validate the effectiveness of our method on the DTU dataset and demonstrate that it outperforms previous state of the art by 35% in surface quality while achieving competitive novel view synthesis quality. Moreover, in contrast to previous works, our method can be applied to larger, unbounded scenes, such as Mip-NeRF 360.
Sp2360: Sparse-view 360 Scene Reconstruction using Cascaded 2D Diffusion Priors
May 26, 2024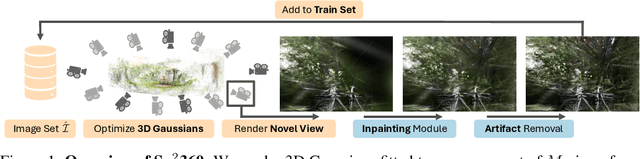



We aim to tackle sparse-view reconstruction of a 360 3D scene using priors from latent diffusion models (LDM). The sparse-view setting is ill-posed and underconstrained, especially for scenes where the camera rotates 360 degrees around a point, as no visual information is available beyond some frontal views focused on the central object(s) of interest. In this work, we show that pretrained 2D diffusion models can strongly improve the reconstruction of a scene with low-cost fine-tuning. Specifically, we present SparseSplat360 (Sp2360), a method that employs a cascade of in-painting and artifact removal models to fill in missing details and clean novel views. Due to superior training and rendering speeds, we use an explicit scene representation in the form of 3D Gaussians over NeRF-based implicit representations. We propose an iterative update strategy to fuse generated pseudo novel views with existing 3D Gaussians fitted to the initial sparse inputs. As a result, we obtain a multi-view consistent scene representation with details coherent with the observed inputs. Our evaluation on the challenging Mip-NeRF360 dataset shows that our proposed 2D to 3D distillation algorithm considerably improves the performance of a regularized version of 3DGS adapted to a sparse-view setting and outperforms existing sparse-view reconstruction methods in 360 scene reconstruction. Qualitatively, our method generates entire 360 scenes from as few as 9 input views, with a high degree of foreground and background detail.
latentSplat: Autoencoding Variational Gaussians for Fast Generalizable 3D Reconstruction
Mar 24, 2024We present latentSplat, a method to predict semantic Gaussians in a 3D latent space that can be splatted and decoded by a light-weight generative 2D architecture. Existing methods for generalizable 3D reconstruction either do not enable fast inference of high resolution novel views due to slow volume rendering, or are limited to interpolation of close input views, even in simpler settings with a single central object, where 360-degree generalization is possible. In this work, we combine a regression-based approach with a generative model, moving towards both of these capabilities within the same method, trained purely on readily available real video data. The core of our method are variational 3D Gaussians, a representation that efficiently encodes varying uncertainty within a latent space consisting of 3D feature Gaussians. From these Gaussians, specific instances can be sampled and rendered via efficient Gaussian splatting and a fast, generative decoder network. We show that latentSplat outperforms previous works in reconstruction quality and generalization, while being fast and scalable to high-resolution data.
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
Dec 21, 2023Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
Neural Parametric Gaussians for Monocular Non-Rigid Object Reconstruction
Dec 02, 2023Reconstructing dynamic objects from monocular videos is a severely underconstrained and challenging problem, and recent work has approached it in various directions. However, owing to the ill-posed nature of this problem, there has been no solution that can provide consistent, high-quality novel views from camera positions that are significantly different from the training views. In this work, we introduce Neural Parametric Gaussians (NPGs) to take on this challenge by imposing a two-stage approach: first, we fit a low-rank neural deformation model, which then is used as regularization for non-rigid reconstruction in the second stage. The first stage learns the object's deformations such that it preserves consistency in novel views. The second stage obtains high reconstruction quality by optimizing 3D Gaussians that are driven by the coarse model. To this end, we introduce a local 3D Gaussian representation, where temporally shared Gaussians are anchored in and deformed by local oriented volumes. The resulting combined model can be rendered as radiance fields, resulting in high-quality photo-realistic reconstructions of the non-rigidly deforming objects, maintaining 3D consistency across novel views. We demonstrate that NPGs achieve superior results compared to previous works, especially in challenging scenarios with few multi-view cues.
SimNP: Learning Self-Similarity Priors Between Neural Points
Sep 07, 2023Existing neural field representations for 3D object reconstruction either (1) utilize object-level representations, but suffer from low-quality details due to conditioning on a global latent code, or (2) are able to perfectly reconstruct the observations, but fail to utilize object-level prior knowledge to infer unobserved regions. We present SimNP, a method to learn category-level self-similarities, which combines the advantages of both worlds by connecting neural point radiance fields with a category-level self-similarity representation. Our contribution is two-fold. (1) We design the first neural point representation on a category level by utilizing the concept of coherent point clouds. The resulting neural point radiance fields store a high level of detail for locally supported object regions. (2) We learn how information is shared between neural points in an unconstrained and unsupervised fashion, which allows to derive unobserved regions of an object during the reconstruction process from given observations. We show that SimNP is able to outperform previous methods in reconstructing symmetric unseen object regions, surpassing methods that build upon category-level or pixel-aligned radiance fields, while providing semantic correspondences between instances