 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry
Nov 15, 2024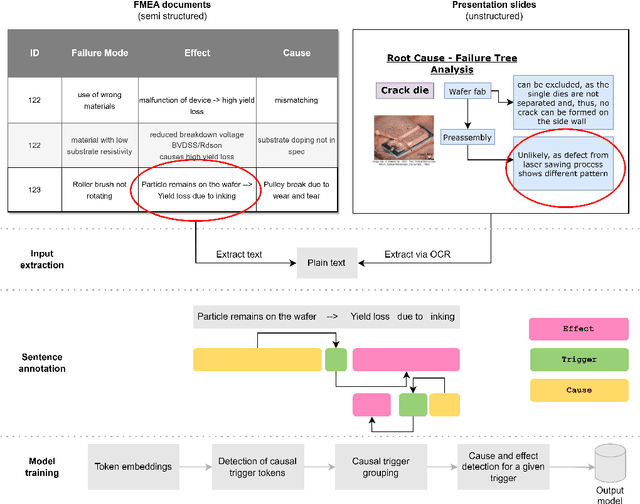
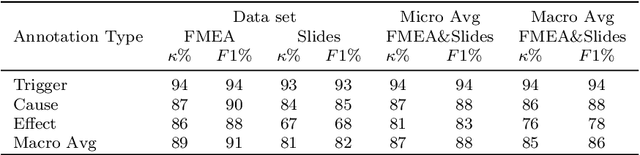
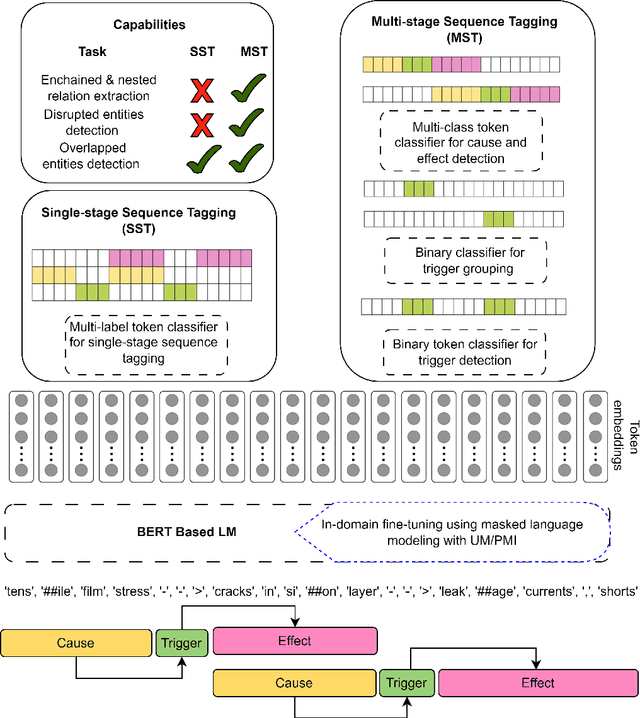
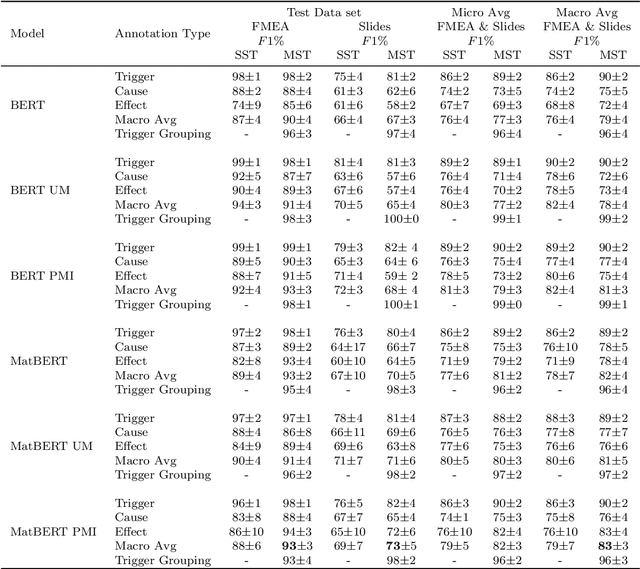
The extraction of causal information from textual data is crucial in the industry for identifying and mitigating potential failures, enhancing process efficiency, prompting quality improvements, and addressing various operational challenges. This paper presents a study on the development of automated methods for causal information extraction from actual industrial documents in the semiconductor manufacturing industry. The study proposes two types of causal information extraction methods, single-stage sequence tagging (SST) and multi-stage sequence tagging (MST), and evaluates their performance using existing documents from a semiconductor manufacturing company, including presentation slides and FMEA (Failure Mode and Effects Analysis) documents. The study also investigates the effect of representation learning on downstream tasks. The presented case study showcases that the proposed MST methods for extracting causal information from industrial documents are suitable for practical applications, especially for semi structured documents such as FMEAs, with a 93\% F1 score. Additionally, MST achieves a 73\% F1 score on texts extracted from presentation slides. Finally, the study highlights the importance of choosing a language model that is more aligned with the domain and in-domain fine-tuning.