 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Watermarks for Large Language Models
Nov 29, 2024The rapid advancement of large language models (LLMs) has made it increasingly difficult to distinguish between text written by humans and machines. While watermarks already exist for LLMs, they often lack flexibility, and struggle with attacks such as paraphrasing. To address these issues, we propose a multi-feature method for generating watermarks that combines multiple distinct watermark features into an ensemble watermark. Concretely, we combine acrostica and sensorimotor norms with the established red-green watermark to achieve a 98% detection rate. After a paraphrasing attack the performance remains high with 95% detection rate. The red-green feature alone as baseline achieves a detection rate of 49%. The evaluation of all feature combinations reveals that the ensemble of all three consistently has the highest detection rate across several LLMs and watermark strength settings. Due to the flexibility of combining features in the ensemble, various requirements and trade-offs can be addressed. Additionally, for all ensemble configurations the same detection function can be used without adaptations. This method is particularly of interest to facilitate accountability and prevent societal harm.
Evaluating Large Language Models for Causal Modeling
Nov 24, 2024
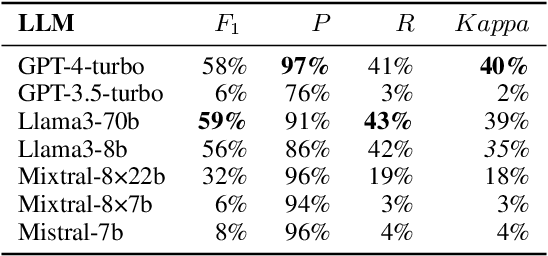

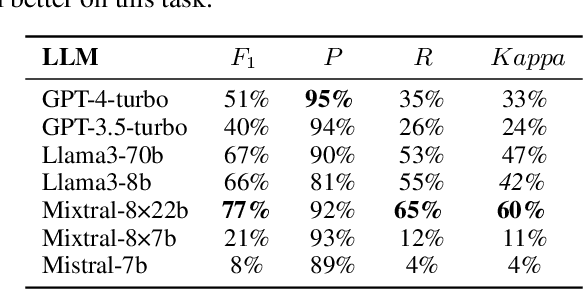
In this paper, we consider the process of transforming causal domain knowledge into a representation that aligns more closely with guidelines from causal data science. To this end, we introduce two novel tasks related to distilling causal domain knowledge into causal variables and detecting interaction entities using LLMs. We have determined that contemporary LLMs are helpful tools for conducting causal modeling tasks in collaboration with human experts, as they can provide a wider perspective. Specifically, LLMs, such as GPT-4-turbo and Llama3-70b, perform better in distilling causal domain knowledge into causal variables compared to sparse expert models, such as Mixtral-8x22b. On the contrary, sparse expert models such as Mixtral-8x22b stand out as the most effective in identifying interaction entities. Finally, we highlight the dependency between the domain where the entities are generated and the performance of the chosen LLM for causal modeling.
Stylometric Watermarks for Large Language Models
May 14, 2024The rapid advancement of large language models (LLMs) has made it increasingly difficult to distinguish between text written by humans and machines. Addressing this, we propose a novel method for generating watermarks that strategically alters token probabilities during generation. Unlike previous works, this method uniquely employs linguistic features such as stylometry. Concretely, we introduce acrostica and sensorimotor norms to LLMs. Further, these features are parameterized by a key, which is updated every sentence. To compute this key, we use semantic zero shot classification, which enhances resilience. In our evaluation, we find that for three or more sentences, our method achieves a false positive and false negative rate of 0.02. For the case of a cyclic translation attack, we observe similar results for seven or more sentences. This research is of particular of interest for proprietary LLMs to facilitate accountability and prevent societal harm.