 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducibility in Machine Learning-based Research: Overview, Barriers and Drivers
Jun 20, 2024Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises primarily due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the level of reproducibility in ML-driven research remains unsatisfactory. Therefore, in this article, we discuss the reproducibility of ML-driven research with three main aims: (i) identify the barriers to reproducibility when applying ML in research as well as categorize the barriers to different types of reproducibility (description, code, data, and experiment reproducibility), (ii) identify potential drivers such as tools, practices, and interventions that support ML reproducibility as well as distinguish between technology-driven drivers, procedural drivers, and drivers related to awareness and education, and (iii) map the drivers to the barriers. With this work, we hope to provide insights and contribute to the decision-making process regarding the adoption of different solutions to support ML reproducibility.
Take the aTrain. Introducing an Interface for the Accessible Transcription of Interviews
Oct 18, 2023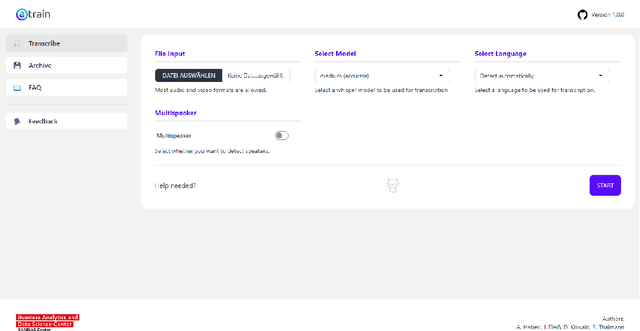

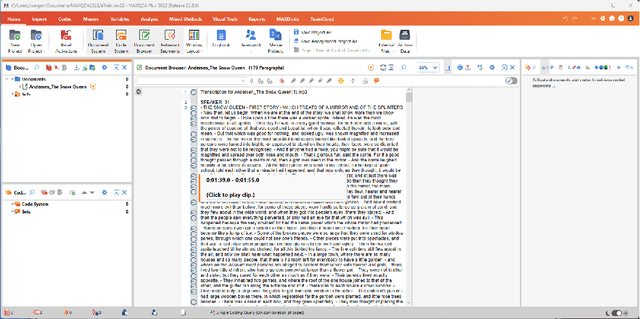

aTrain is an open-source and offline tool for transcribing audio data in multiple languages with CPU and NVIDIA GPU support. It is specifically designed for researchers using qualitative data generated from various forms of speech interactions with research participants. aTrain requires no programming skills, runs on most computers, does not require an internet connection, and was verified not to upload data to any server. aTrain combines OpenAI's Whisper model with speaker recognition to provide output that integrates with the popular qualitative data analysis software tools MAXQDA and ATLAS.ti. It has an easy-to-use graphical interface and is provided as a Windows-App through the Microsoft Store allowing for simple installation by researchers. The source code is freely available on GitHub. Having developed aTrain with a focus on speed on local computers, we show that the transcription time on current mobile CPUs is around 2 to 3 times the duration of the audio file using the highest-accuracy transcription models. If an entry-level graphics card is available, the transcription speed increases to 20% of the audio duration.