 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake the aTrain. Introducing an Interface for the Accessible Transcription of Interviews
Oct 18, 2023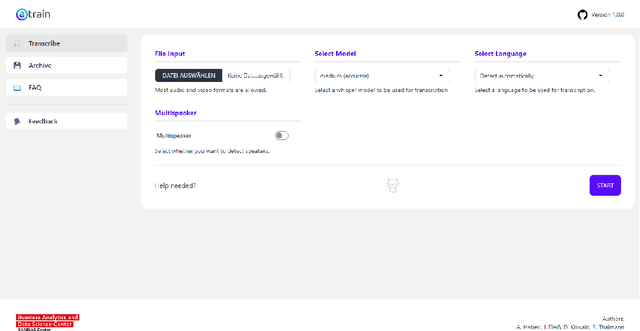

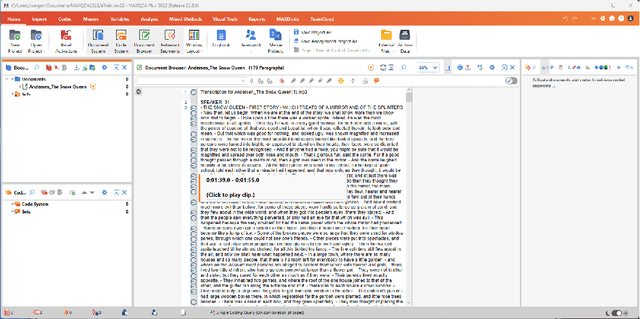

aTrain is an open-source and offline tool for transcribing audio data in multiple languages with CPU and NVIDIA GPU support. It is specifically designed for researchers using qualitative data generated from various forms of speech interactions with research participants. aTrain requires no programming skills, runs on most computers, does not require an internet connection, and was verified not to upload data to any server. aTrain combines OpenAI's Whisper model with speaker recognition to provide output that integrates with the popular qualitative data analysis software tools MAXQDA and ATLAS.ti. It has an easy-to-use graphical interface and is provided as a Windows-App through the Microsoft Store allowing for simple installation by researchers. The source code is freely available on GitHub. Having developed aTrain with a focus on speed on local computers, we show that the transcription time on current mobile CPUs is around 2 to 3 times the duration of the audio file using the highest-accuracy transcription models. If an entry-level graphics card is available, the transcription speed increases to 20% of the audio duration.