 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Machine Learning Models Beyond Adversarial Attacks
Paper and Code
Apr 21, 2022
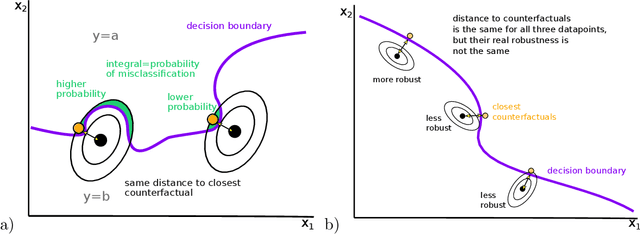

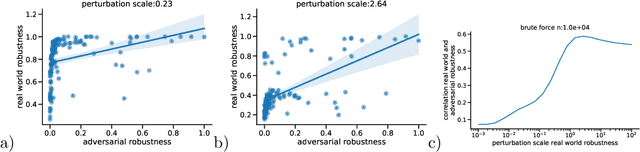
Correctly quantifying the robustness of machine learning models is a central aspect in judging their suitability for specific tasks, and thus, ultimately, for generating trust in the models. We show that the widely used concept of adversarial robustness and closely related metrics based on counterfactuals are not necessarily valid metrics for determining the robustness of ML models against perturbations that occur "naturally", outside specific adversarial attack scenarios. Additionally, we argue that generic robustness metrics in principle are insufficient for determining real-world-robustness. Instead we propose a flexible approach that models possible perturbations in input data individually for each application. This is then combined with a probabilistic approach that computes the likelihood that a real-world perturbation will change a prediction, thus giving quantitative information of the robustness of the trained machine learning model. The method does not require access to the internals of the classifier and thus in principle works for any black-box model. It is, however, based on Monte-Carlo sampling and thus only suited for input spaces with small dimensions. We illustrate our approach on two dataset, as well as on analytically solvable cases. Finally, we discuss ideas on how real-world robustness could be computed or estimated in high-dimensional input spaces.