 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Language to Action: A Review of Large Language Models as Autonomous Agents and Tool Users
Aug 24, 2025The pursuit of human-level artificial intelligence (AI) has significantly advanced the development of autonomous agents and Large Language Models (LLMs). LLMs are now widely utilized as decision-making agents for their ability to interpret instructions, manage sequential tasks, and adapt through feedback. This review examines recent developments in employing LLMs as autonomous agents and tool users and comprises seven research questions. We only used the papers published between 2023 and 2025 in conferences of the A* and A rank and Q1 journals. A structured analysis of the LLM agents' architectural design principles, dividing their applications into single-agent and multi-agent systems, and strategies for integrating external tools is presented. In addition, the cognitive mechanisms of LLM, including reasoning, planning, and memory, and the impact of prompting methods and fine-tuning procedures on agent performance are also investigated. Furthermore, we evaluated current benchmarks and assessment protocols and have provided an analysis of 68 publicly available datasets to assess the performance of LLM-based agents in various tasks. In conducting this review, we have identified critical findings on verifiable reasoning of LLMs, the capacity for self-improvement, and the personalization of LLM-based agents. Finally, we have discussed ten future research directions to overcome these gaps.
Fine-tuned Large Language Models (LLMs): Improved Prompt Injection Attacks Detection
Oct 28, 2024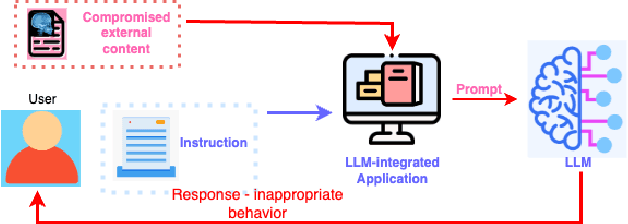
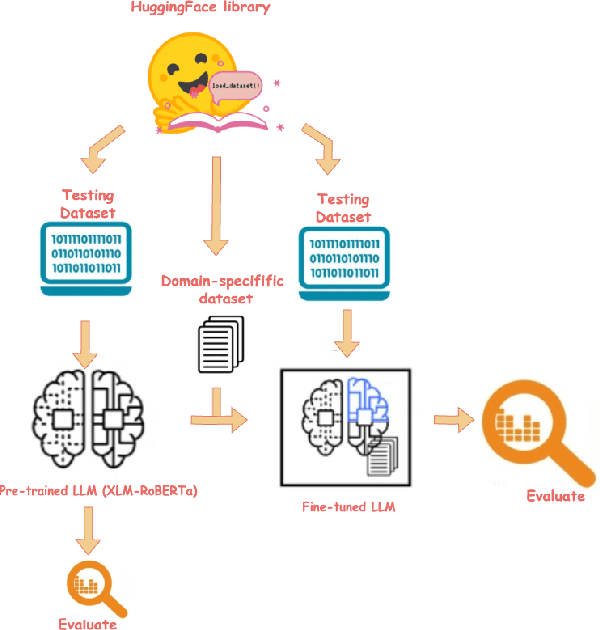
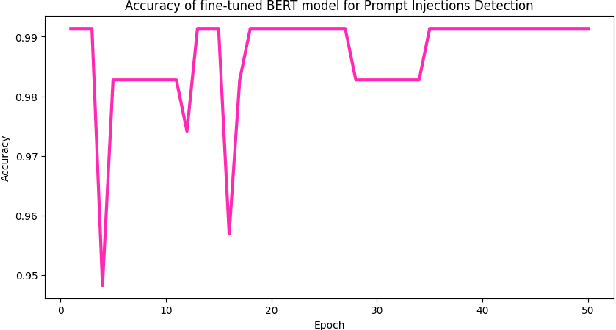
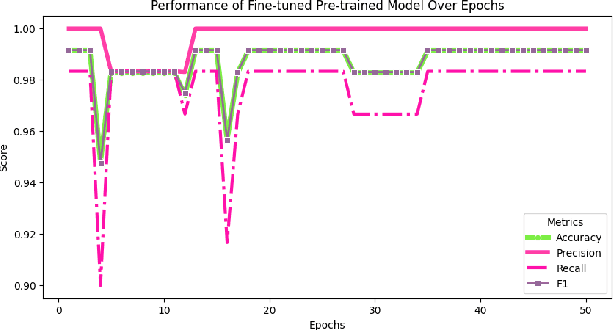
Large language models (LLMs) are becoming a popular tool as they have significantly advanced in their capability to tackle a wide range of language-based tasks. However, LLMs applications are highly vulnerable to prompt injection attacks, which poses a critical problem. These attacks target LLMs applications through using carefully designed input prompts to divert the model from adhering to original instruction, thereby it could execute unintended actions. These manipulations pose serious security threats which potentially results in data leaks, biased outputs, or harmful responses. This project explores the security vulnerabilities in relation to prompt injection attacks. To detect whether a prompt is vulnerable or not, we follows two approaches: 1) a pre-trained LLM, and 2) a fine-tuned LLM. Then, we conduct a thorough analysis and comparison of the classification performance. Firstly, we use pre-trained XLM-RoBERTa model to detect prompt injections using test dataset without any fine-tuning and evaluate it by zero-shot classification. Then, this proposed work will apply supervised fine-tuning to this pre-trained LLM using a task-specific labeled dataset from deepset in huggingface, and this fine-tuned model achieves impressive results with 99.13\% accuracy, 100\% precision, 98.33\% recall and 99.15\% F1-score thorough rigorous experimentation and evaluation. We observe that our approach is highly efficient in detecting prompt injection attacks.
Embedding with Large Language Models for Classification of HIPAA Safeguard Compliance Rules
Oct 28, 2024
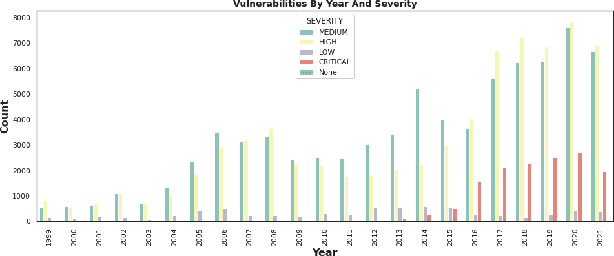
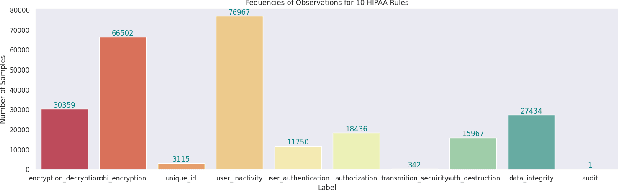
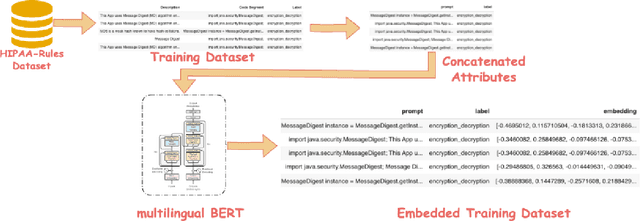
Although software developers of mHealth apps are responsible for protecting patient data and adhering to strict privacy and security requirements, many of them lack awareness of HIPAA regulations and struggle to distinguish between HIPAA rules categories. Therefore, providing guidance of HIPAA rules patterns classification is essential for developing secured applications for Google Play Store. In this work, we identified the limitations of traditional Word2Vec embeddings in processing code patterns. To address this, we adopt multilingual BERT (Bidirectional Encoder Representations from Transformers) which offers contextualized embeddings to the attributes of dataset to overcome the issues. Therefore, we applied this BERT to our dataset for embedding code patterns and then uses these embedded code to various machine learning approaches. Our results demonstrate that the models significantly enhances classification performance, with Logistic Regression achieving a remarkable accuracy of 99.95\%. Additionally, we obtained high accuracy from Support Vector Machine (99.79\%), Random Forest (99.73\%), and Naive Bayes (95.93\%), outperforming existing approaches. This work underscores the effectiveness and showcases its potential for secure application development.