 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuned Large Language Models (LLMs): Improved Prompt Injection Attacks Detection
Paper and Code
Oct 28, 2024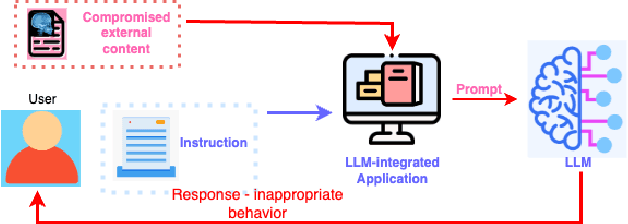
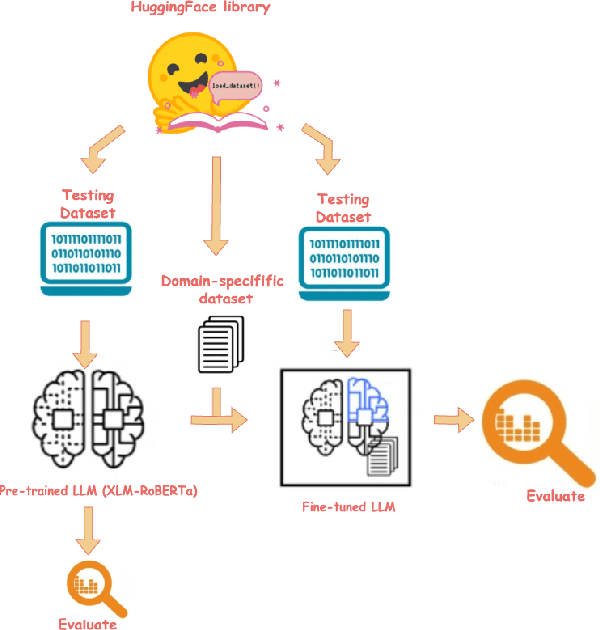
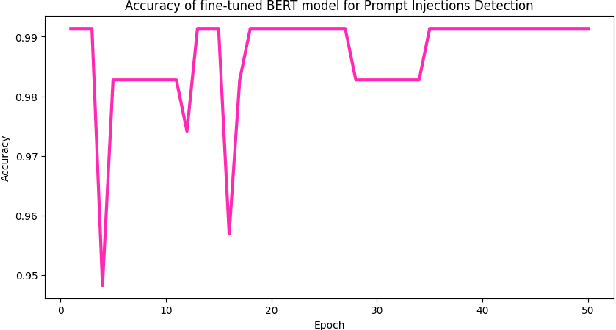
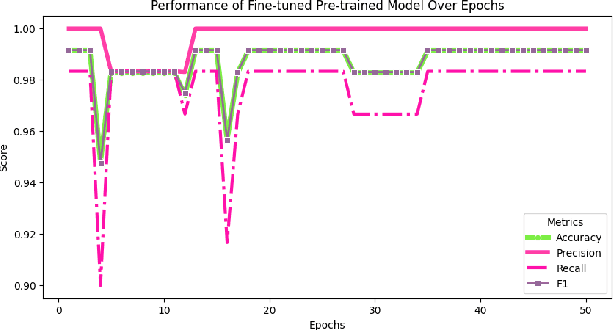
Large language models (LLMs) are becoming a popular tool as they have significantly advanced in their capability to tackle a wide range of language-based tasks. However, LLMs applications are highly vulnerable to prompt injection attacks, which poses a critical problem. These attacks target LLMs applications through using carefully designed input prompts to divert the model from adhering to original instruction, thereby it could execute unintended actions. These manipulations pose serious security threats which potentially results in data leaks, biased outputs, or harmful responses. This project explores the security vulnerabilities in relation to prompt injection attacks. To detect whether a prompt is vulnerable or not, we follows two approaches: 1) a pre-trained LLM, and 2) a fine-tuned LLM. Then, we conduct a thorough analysis and comparison of the classification performance. Firstly, we use pre-trained XLM-RoBERTa model to detect prompt injections using test dataset without any fine-tuning and evaluate it by zero-shot classification. Then, this proposed work will apply supervised fine-tuning to this pre-trained LLM using a task-specific labeled dataset from deepset in huggingface, and this fine-tuned model achieves impressive results with 99.13\% accuracy, 100\% precision, 98.33\% recall and 99.15\% F1-score thorough rigorous experimentation and evaluation. We observe that our approach is highly efficient in detecting prompt injection attacks.