 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Simplicity and Sophistication using GLinear: A Novel Architecture for Enhanced Time Series Prediction
Jan 08, 2025



Time Series Forecasting (TSF) is an important application across many fields. There is a debate about whether Transformers, despite being good at understanding long sequences, struggle with preserving temporal relationships in time series data. Recent research suggests that simpler linear models might outperform or at least provide competitive performance compared to complex Transformer-based models for TSF tasks. In this paper, we propose a novel data-efficient architecture, GLinear, for multivariate TSF that exploits periodic patterns to provide better accuracy. It also provides better prediction accuracy by using a smaller amount of historical data compared to other state-of-the-art linear predictors. Four different datasets (ETTh1, Electricity, Traffic, and Weather) are used to evaluate the performance of the proposed predictor. A performance comparison with state-of-the-art linear architectures (such as NLinear, DLinear, and RLinear) and transformer-based time series predictor (Autoformer) shows that the GLinear, despite being parametrically efficient, significantly outperforms the existing architectures in most cases of multivariate TSF. We hope that the proposed GLinear opens new fronts of research and development of simpler and more sophisticated architectures for data and computationally efficient time-series analysis.
EnStack: An Ensemble Stacking Framework of Large Language Models for Enhanced Vulnerability Detection in Source Code
Nov 25, 2024Automated detection of software vulnerabilities is critical for enhancing security, yet existing methods often struggle with the complexity and diversity of modern codebases. In this paper, we introduce EnStack, a novel ensemble stacking framework that enhances vulnerability detection using natural language processing (NLP) techniques. Our approach synergizes multiple pre-trained large language models (LLMs) specialized in code understanding CodeBERT for semantic analysis, GraphCodeBERT for structural representation, and UniXcoder for cross-modal capabilities. By fine-tuning these models on the Draper VDISC dataset and integrating their outputs through meta-classifiers such as Logistic Regression, Support Vector Machines (SVM), Random Forest, and XGBoost, EnStack effectively captures intricate code patterns and vulnerabilities that individual models may overlook. The meta-classifiers consolidate the strengths of each LLM, resulting in a comprehensive model that excels in detecting subtle and complex vulnerabilities across diverse programming contexts. Experimental results demonstrate that EnStack significantly outperforms existing methods, achieving notable improvements in accuracy, precision, recall, and F1-score. This work highlights the potential of ensemble LLM approaches in code analysis tasks and offers valuable insights into applying NLP techniques for advancing automated vulnerability detection.
Embedding with Large Language Models for Classification of HIPAA Safeguard Compliance Rules
Oct 28, 2024
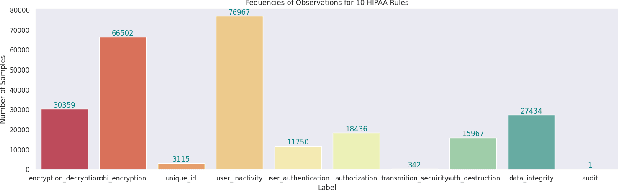
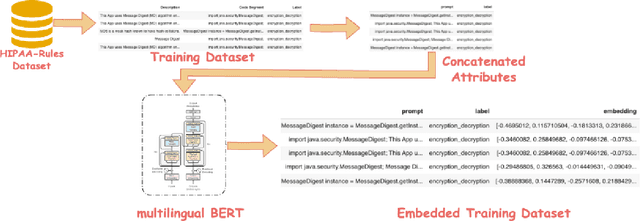
Although software developers of mHealth apps are responsible for protecting patient data and adhering to strict privacy and security requirements, many of them lack awareness of HIPAA regulations and struggle to distinguish between HIPAA rules categories. Therefore, providing guidance of HIPAA rules patterns classification is essential for developing secured applications for Google Play Store. In this work, we identified the limitations of traditional Word2Vec embeddings in processing code patterns. To address this, we adopt multilingual BERT (Bidirectional Encoder Representations from Transformers) which offers contextualized embeddings to the attributes of dataset to overcome the issues. Therefore, we applied this BERT to our dataset for embedding code patterns and then uses these embedded code to various machine learning approaches. Our results demonstrate that the models significantly enhances classification performance, with Logistic Regression achieving a remarkable accuracy of 99.95\%. Additionally, we obtained high accuracy from Support Vector Machine (99.79\%), Random Forest (99.73\%), and Naive Bayes (95.93\%), outperforming existing approaches. This work underscores the effectiveness and showcases its potential for secure application development.
Fine-tuned Large Language Models (LLMs): Improved Prompt Injection Attacks Detection
Oct 28, 2024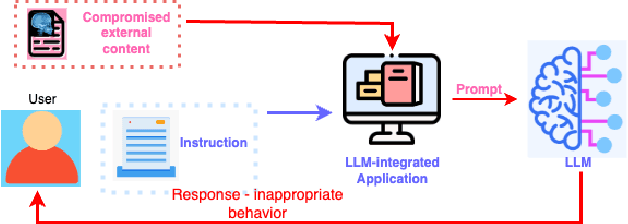
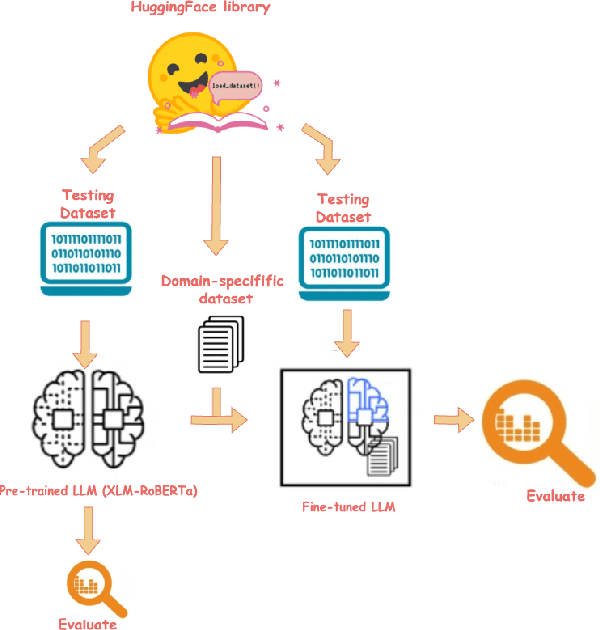
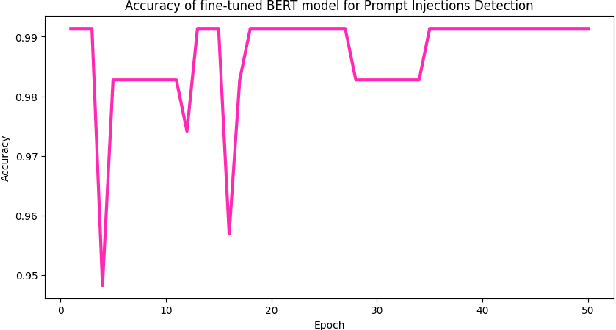
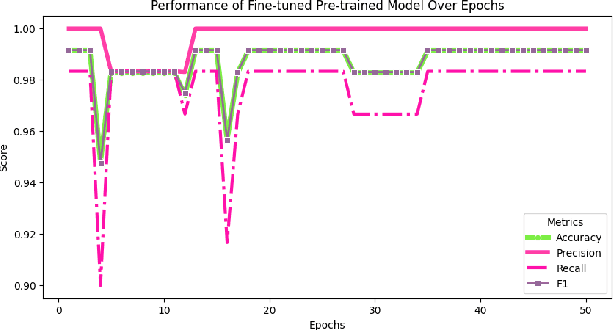
Large language models (LLMs) are becoming a popular tool as they have significantly advanced in their capability to tackle a wide range of language-based tasks. However, LLMs applications are highly vulnerable to prompt injection attacks, which poses a critical problem. These attacks target LLMs applications through using carefully designed input prompts to divert the model from adhering to original instruction, thereby it could execute unintended actions. These manipulations pose serious security threats which potentially results in data leaks, biased outputs, or harmful responses. This project explores the security vulnerabilities in relation to prompt injection attacks. To detect whether a prompt is vulnerable or not, we follows two approaches: 1) a pre-trained LLM, and 2) a fine-tuned LLM. Then, we conduct a thorough analysis and comparison of the classification performance. Firstly, we use pre-trained XLM-RoBERTa model to detect prompt injections using test dataset without any fine-tuning and evaluate it by zero-shot classification. Then, this proposed work will apply supervised fine-tuning to this pre-trained LLM using a task-specific labeled dataset from deepset in huggingface, and this fine-tuned model achieves impressive results with 99.13\% accuracy, 100\% precision, 98.33\% recall and 99.15\% F1-score thorough rigorous experimentation and evaluation. We observe that our approach is highly efficient in detecting prompt injection attacks.
A Trustable LSTM-Autoencoder Network for Cyberbullying Detection on Social Media Using Synthetic Data
Aug 15, 2023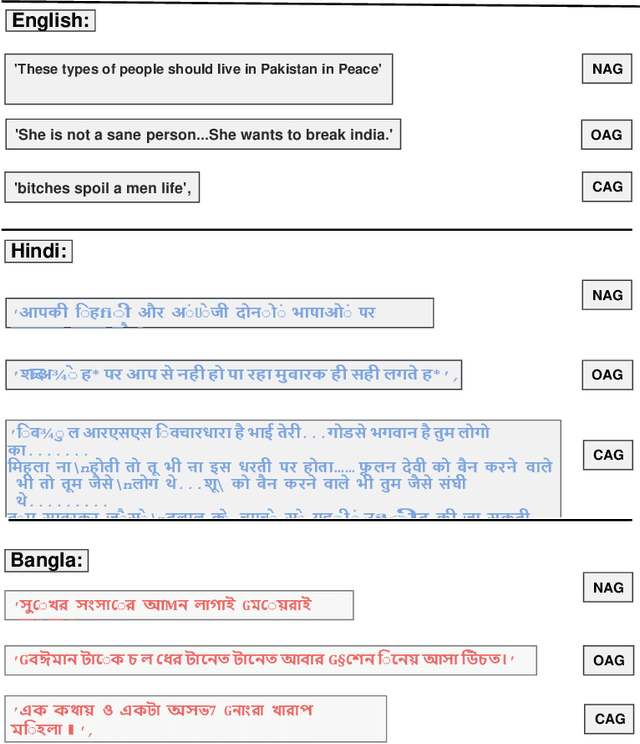

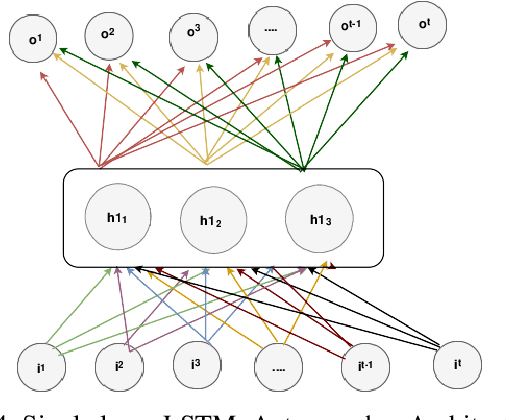
Social media cyberbullying has a detrimental effect on human life. As online social networking grows daily, the amount of hate speech also increases. Such terrible content can cause depression and actions related to suicide. This paper proposes a trustable LSTM-Autoencoder Network for cyberbullying detection on social media using synthetic data. We have demonstrated a cutting-edge method to address data availability difficulties by producing machine-translated data. However, several languages such as Hindi and Bangla still lack adequate investigations due to a lack of datasets. We carried out experimental identification of aggressive comments on Hindi, Bangla, and English datasets using the proposed model and traditional models, including Long Short-Term Memory (LSTM), Bidirectional Long Short-Term Memory (BiLSTM), LSTM-Autoencoder, Word2vec, Bidirectional Encoder Representations from Transformers (BERT), and Generative Pre-trained Transformer 2 (GPT-2) models. We employed evaluation metrics such as f1-score, accuracy, precision, and recall to assess the models performance. Our proposed model outperformed all the models on all datasets, achieving the highest accuracy of 95%. Our model achieves state-of-the-art results among all the previous works on the dataset we used in this paper.
Feature Engineering-Based Detection of Buffer Overflow Vulnerability in Source Code Using Neural Networks
Jun 01, 2023



One of the most significant challenges in the field of software code auditing is the presence of vulnerabilities in software source code. Every year, more and more software flaws are discovered, either internally in proprietary code or publicly disclosed. These flaws are highly likely to be exploited and can lead to system compromise, data leakage, or denial of service. To create a large-scale machine learning system for function level vulnerability identification, we utilized a sizable dataset of C and C++ open-source code containing millions of functions with potential buffer overflow exploits. We have developed an efficient and scalable vulnerability detection method based on neural network models that learn features extracted from the source codes. The source code is first converted into an intermediate representation to remove unnecessary components and shorten dependencies. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. Furthermore, we have proposed a neural network model that can overcome issues associated with traditional neural networks. We have used evaluation metrics such as F1 score, precision, recall, accuracy, and total execution time to measure the performance. We have conducted a comparative analysis between results derived from features containing a minimal text representation and semantic and syntactic information.
Autism Disease Detection Using Transfer Learning Techniques: Performance Comparison Between Central Processing Unit vs Graphics Processing Unit Functions for Neural Networks
Jun 01, 2023Neural network approaches are machine learning methods that are widely used in various domains, such as healthcare and cybersecurity. Neural networks are especially renowned for their ability to deal with image datasets. During the training process with images, various fundamental mathematical operations are performed in the neural network. These operations include several algebraic and mathematical functions, such as derivatives, convolutions, and matrix inversions and transpositions. Such operations demand higher processing power than what is typically required for regular computer usage. Since CPUs are built with serial processing, they are not appropriate for handling large image datasets. On the other hand, GPUs have parallel processing capabilities and can provide higher speed. This paper utilizes advanced neural network techniques, such as VGG16, Resnet50, Densenet, Inceptionv3, Xception, Mobilenet, XGBOOST VGG16, and our proposed models, to compare CPU and GPU resources. We implemented a system for classifying Autism disease using face images of autistic and non-autistic children to compare performance during testing. We used evaluation matrices such as Accuracy, F1 score, Precision, Recall, and Execution time. It was observed that GPU outperformed CPU in all tests conducted. Moreover, the performance of the neural network models in terms of accuracy increased on GPU compared to CPU.
Software Supply Chain Vulnerabilities Detection in Source Code: Performance Comparison between Traditional and Quantum Machine Learning Algorithms
May 31, 2023



The software supply chain (SSC) attack has become one of the crucial issues that are being increased rapidly with the advancement of the software development domain. In general, SSC attacks execute during the software development processes lead to vulnerabilities in software products targeting downstream customers and even involved stakeholders. Machine Learning approaches are proven in detecting and preventing software security vulnerabilities. Besides, emerging quantum machine learning can be promising in addressing SSC attacks. Considering the distinction between traditional and quantum machine learning, performance could be varies based on the proportions of the experimenting dataset. In this paper, we conduct a comparative analysis between quantum neural networks (QNN) and conventional neural networks (NN) with a software supply chain attack dataset known as ClaMP. Our goal is to distinguish the performance between QNN and NN and to conduct the experiment, we develop two different models for QNN and NN by utilizing Pennylane for quantum and TensorFlow and Keras for traditional respectively. We evaluated the performance of both models with different proportions of the ClaMP dataset to identify the f1 score, recall, precision, and accuracy. We also measure the execution time to check the efficiency of both models. The demonstration result indicates that execution time for QNN is slower than NN with a higher percentage of datasets. Due to recent advancements in QNN, a large level of experiments shall be carried out to understand both models accurately in our future research.
Deep Learning Approach for Classifying the Aggressive Comments on Social Media: Machine Translated Data Vs Real Life Data
Mar 13, 2023Aggressive comments on social media negatively impact human life. Such offensive contents are responsible for depression and suicidal-related activities. Since online social networking is increasing day by day, the hate content is also increasing. Several investigations have been done on the domain of cyberbullying, cyberaggression, hate speech, etc. The majority of the inquiry has been done in the English language. Some languages (Hindi and Bangla) still lack proper investigations due to the lack of a dataset. This paper particularly worked on the Hindi, Bangla, and English datasets to detect aggressive comments and have shown a novel way of generating machine-translated data to resolve data unavailability issues. A fully machine-translated English dataset has been analyzed with the models such as the Long Short term memory model (LSTM), Bidirectional Long-short term memory model (BiLSTM), LSTM-Autoencoder, word2vec, Bidirectional Encoder Representations from Transformers (BERT), and generative pre-trained transformer (GPT-2) to make an observation on how the models perform on a machine-translated noisy dataset. We have compared the performance of using the noisy data with two more datasets such as raw data, which does not contain any noises, and semi-noisy data, which contains a certain amount of noisy data. We have classified both the raw and semi-noisy data using the aforementioned models. To evaluate the performance of the models, we have used evaluation metrics such as F1-score,accuracy, precision, and recall. We have achieved the highest accuracy on raw data using the gpt2 model, semi-noisy data using the BERT model, and fully machine-translated data using the BERT model. Since many languages do not have proper data availability, our approach will help researchers create machine-translated datasets for several analysis purposes.
Multi-class Skin Cancer Classification Architecture Based on Deep Convolutional Neural Network
Mar 13, 2023



Skin cancer detection is challenging since different types of skin lesions share high similarities. This paper proposes a computer-based deep learning approach that will accurately identify different kinds of skin lesions. Deep learning approaches can detect skin cancer very accurately since the models learn each pixel of an image. Sometimes humans can get confused by the similarities of the skin lesions, which we can minimize by involving the machine. However, not all deep learning approaches can give better predictions. Some deep learning models have limitations, leading the model to a false-positive result. We have introduced several deep learning models to classify skin lesions to distinguish skin cancer from different types of skin lesions. Before classifying the skin lesions, data preprocessing and data augmentation methods are used. Finally, a Convolutional Neural Network (CNN) model and six transfer learning models such as Resnet-50, VGG-16, Densenet, Mobilenet, Inceptionv3, and Xception are applied to the publically available benchmark HAM10000 dataset to classify seven classes of skin lesions and to conduct a comparative analysis. The models will detect skin cancer by differentiating the cancerous cell from the non-cancerous ones. The models performance is measured using performance metrics such as precision, recall, f1 score, and accuracy. We receive accuracy of 90, 88, 88, 87, 82, and 77 percent for inceptionv3, Xception, Densenet, Mobilenet, Resnet, CNN, and VGG16, respectively. Furthermore, we develop five different stacking models such as inceptionv3-inceptionv3, Densenet-mobilenet, inceptionv3-Xception, Resnet50-Vgg16, and stack-six for classifying the skin lesions and found that the stacking models perform poorly. We achieve the highest accuracy of 78 percent among all the stacking models.