 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Trustable LSTM-Autoencoder Network for Cyberbullying Detection on Social Media Using Synthetic Data
Aug 15, 2023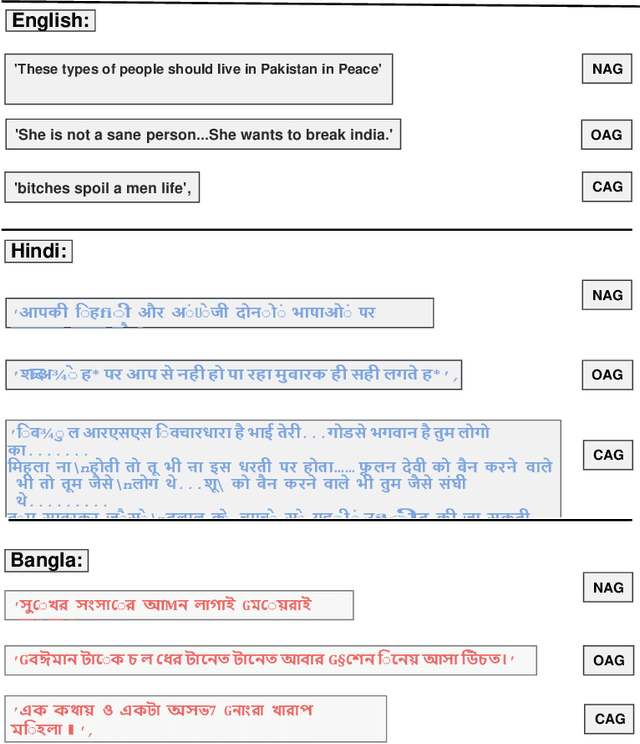

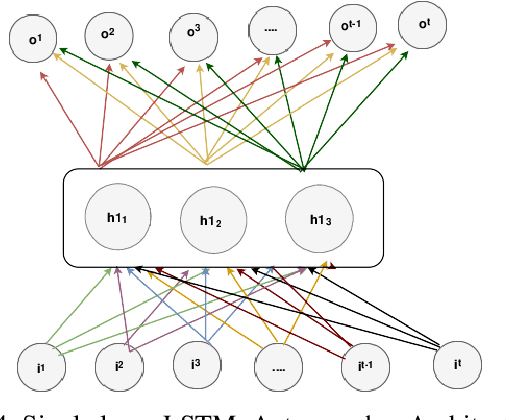
Social media cyberbullying has a detrimental effect on human life. As online social networking grows daily, the amount of hate speech also increases. Such terrible content can cause depression and actions related to suicide. This paper proposes a trustable LSTM-Autoencoder Network for cyberbullying detection on social media using synthetic data. We have demonstrated a cutting-edge method to address data availability difficulties by producing machine-translated data. However, several languages such as Hindi and Bangla still lack adequate investigations due to a lack of datasets. We carried out experimental identification of aggressive comments on Hindi, Bangla, and English datasets using the proposed model and traditional models, including Long Short-Term Memory (LSTM), Bidirectional Long Short-Term Memory (BiLSTM), LSTM-Autoencoder, Word2vec, Bidirectional Encoder Representations from Transformers (BERT), and Generative Pre-trained Transformer 2 (GPT-2) models. We employed evaluation metrics such as f1-score, accuracy, precision, and recall to assess the models performance. Our proposed model outperformed all the models on all datasets, achieving the highest accuracy of 95%. Our model achieves state-of-the-art results among all the previous works on the dataset we used in this paper.
BlockTheFall: Wearable Device-based Fall Detection Framework Powered by Machine Learning and Blockchain for Elderly Care
Jun 10, 2023



Falls among the elderly are a major health concern, frequently resulting in serious injuries and a reduced quality of life. In this paper, we propose "BlockTheFall," a wearable device-based fall detection framework which detects falls in real time by using sensor data from wearable devices. To accurately identify patterns and detect falls, the collected sensor data is analyzed using machine learning algorithms. To ensure data integrity and security, the framework stores and verifies fall event data using blockchain technology. The proposed framework aims to provide an efficient and dependable solution for fall detection with improved emergency response, and elderly individuals' overall well-being. Further experiments and evaluations are being carried out to validate the effectiveness and feasibility of the proposed framework, which has shown promising results in distinguishing genuine falls from simulated falls. By providing timely and accurate fall detection and response, this framework has the potential to substantially boost the quality of elderly care.
Case Study-Based Approach of Quantum Machine Learning in Cybersecurity: Quantum Support Vector Machine for Malware Classification and Protection
Jun 01, 2023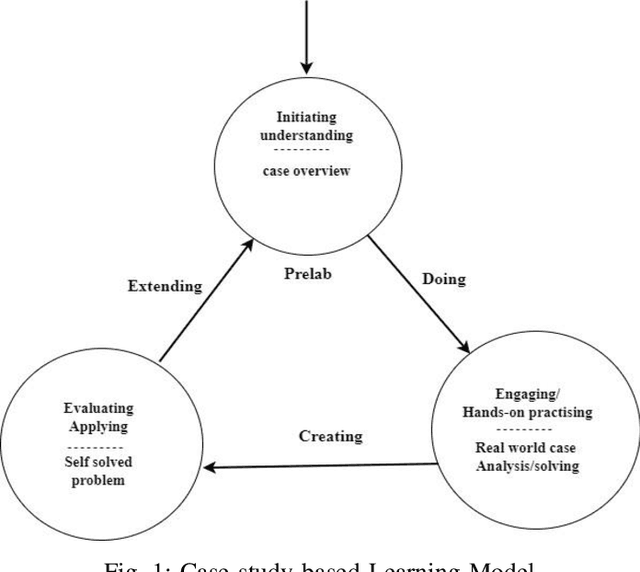
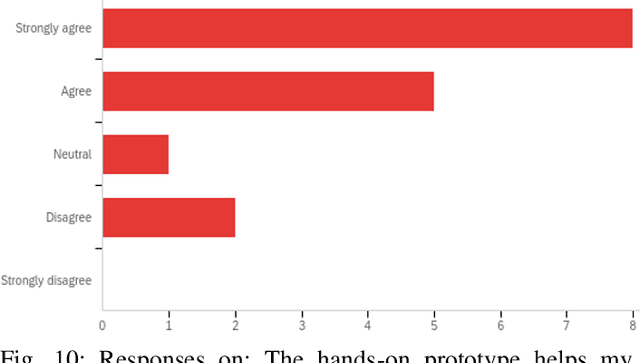
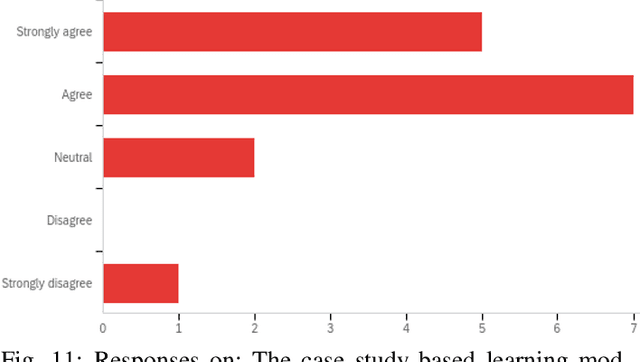

Quantum machine learning (QML) is an emerging field of research that leverages quantum computing to improve the classical machine learning approach to solve complex real world problems. QML has the potential to address cybersecurity related challenges. Considering the novelty and complex architecture of QML, resources are not yet explicitly available that can pave cybersecurity learners to instill efficient knowledge of this emerging technology. In this research, we design and develop QML-based ten learning modules covering various cybersecurity topics by adopting student centering case-study based learning approach. We apply one subtopic of QML on a cybersecurity topic comprised of pre-lab, lab, and post-lab activities towards providing learners with hands-on QML experiences in solving real-world security problems. In order to engage and motivate students in a learning environment that encourages all students to learn, pre-lab offers a brief introduction to both the QML subtopic and cybersecurity problem. In this paper, we utilize quantum support vector machine (QSVM) for malware classification and protection where we use open source Pennylane QML framework on the drebin215 dataset. We demonstrate our QSVM model and achieve an accuracy of 95% in malware classification and protection. We will develop all the modules and introduce them to the cybersecurity community in the coming days.
Autism Disease Detection Using Transfer Learning Techniques: Performance Comparison Between Central Processing Unit vs Graphics Processing Unit Functions for Neural Networks
Jun 01, 2023Neural network approaches are machine learning methods that are widely used in various domains, such as healthcare and cybersecurity. Neural networks are especially renowned for their ability to deal with image datasets. During the training process with images, various fundamental mathematical operations are performed in the neural network. These operations include several algebraic and mathematical functions, such as derivatives, convolutions, and matrix inversions and transpositions. Such operations demand higher processing power than what is typically required for regular computer usage. Since CPUs are built with serial processing, they are not appropriate for handling large image datasets. On the other hand, GPUs have parallel processing capabilities and can provide higher speed. This paper utilizes advanced neural network techniques, such as VGG16, Resnet50, Densenet, Inceptionv3, Xception, Mobilenet, XGBOOST VGG16, and our proposed models, to compare CPU and GPU resources. We implemented a system for classifying Autism disease using face images of autistic and non-autistic children to compare performance during testing. We used evaluation matrices such as Accuracy, F1 score, Precision, Recall, and Execution time. It was observed that GPU outperformed CPU in all tests conducted. Moreover, the performance of the neural network models in terms of accuracy increased on GPU compared to CPU.
Feature Engineering-Based Detection of Buffer Overflow Vulnerability in Source Code Using Neural Networks
Jun 01, 2023



One of the most significant challenges in the field of software code auditing is the presence of vulnerabilities in software source code. Every year, more and more software flaws are discovered, either internally in proprietary code or publicly disclosed. These flaws are highly likely to be exploited and can lead to system compromise, data leakage, or denial of service. To create a large-scale machine learning system for function level vulnerability identification, we utilized a sizable dataset of C and C++ open-source code containing millions of functions with potential buffer overflow exploits. We have developed an efficient and scalable vulnerability detection method based on neural network models that learn features extracted from the source codes. The source code is first converted into an intermediate representation to remove unnecessary components and shorten dependencies. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. Furthermore, we have proposed a neural network model that can overcome issues associated with traditional neural networks. We have used evaluation metrics such as F1 score, precision, recall, accuracy, and total execution time to measure the performance. We have conducted a comparative analysis between results derived from features containing a minimal text representation and semantic and syntactic information.
Software Supply Chain Vulnerabilities Detection in Source Code: Performance Comparison between Traditional and Quantum Machine Learning Algorithms
May 31, 2023



The software supply chain (SSC) attack has become one of the crucial issues that are being increased rapidly with the advancement of the software development domain. In general, SSC attacks execute during the software development processes lead to vulnerabilities in software products targeting downstream customers and even involved stakeholders. Machine Learning approaches are proven in detecting and preventing software security vulnerabilities. Besides, emerging quantum machine learning can be promising in addressing SSC attacks. Considering the distinction between traditional and quantum machine learning, performance could be varies based on the proportions of the experimenting dataset. In this paper, we conduct a comparative analysis between quantum neural networks (QNN) and conventional neural networks (NN) with a software supply chain attack dataset known as ClaMP. Our goal is to distinguish the performance between QNN and NN and to conduct the experiment, we develop two different models for QNN and NN by utilizing Pennylane for quantum and TensorFlow and Keras for traditional respectively. We evaluated the performance of both models with different proportions of the ClaMP dataset to identify the f1 score, recall, precision, and accuracy. We also measure the execution time to check the efficiency of both models. The demonstration result indicates that execution time for QNN is slower than NN with a higher percentage of datasets. Due to recent advancements in QNN, a large level of experiments shall be carried out to understand both models accurately in our future research.
Exploring the Vulnerabilities of Machine Learning and Quantum Machine Learning to Adversarial Attacks using a Malware Dataset: A Comparative Analysis
May 31, 2023


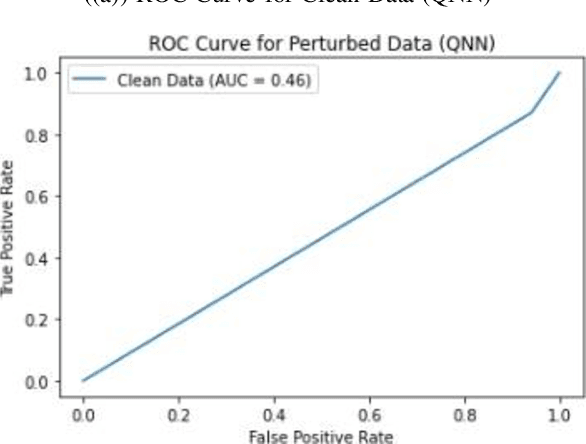
The burgeoning fields of machine learning (ML) and quantum machine learning (QML) have shown remarkable potential in tackling complex problems across various domains. However, their susceptibility to adversarial attacks raises concerns when deploying these systems in security sensitive applications. In this study, we present a comparative analysis of the vulnerability of ML and QML models, specifically conventional neural networks (NN) and quantum neural networks (QNN), to adversarial attacks using a malware dataset. We utilize a software supply chain attack dataset known as ClaMP and develop two distinct models for QNN and NN, employing Pennylane for quantum implementations and TensorFlow and Keras for traditional implementations. Our methodology involves crafting adversarial samples by introducing random noise to a small portion of the dataset and evaluating the impact on the models performance using accuracy, precision, recall, and F1 score metrics. Based on our observations, both ML and QML models exhibit vulnerability to adversarial attacks. While the QNNs accuracy decreases more significantly compared to the NN after the attack, it demonstrates better performance in terms of precision and recall, indicating higher resilience in detecting true positives under adversarial conditions. We also find that adversarial samples crafted for one model type can impair the performance of the other, highlighting the need for robust defense mechanisms. Our study serves as a foundation for future research focused on enhancing the security and resilience of ML and QML models, particularly QNN, given its recent advancements. A more extensive range of experiments will be conducted to better understand the performance and robustness of both models in the face of adversarial attacks.
Multi-class Skin Cancer Classification Architecture Based on Deep Convolutional Neural Network
Mar 13, 2023



Skin cancer detection is challenging since different types of skin lesions share high similarities. This paper proposes a computer-based deep learning approach that will accurately identify different kinds of skin lesions. Deep learning approaches can detect skin cancer very accurately since the models learn each pixel of an image. Sometimes humans can get confused by the similarities of the skin lesions, which we can minimize by involving the machine. However, not all deep learning approaches can give better predictions. Some deep learning models have limitations, leading the model to a false-positive result. We have introduced several deep learning models to classify skin lesions to distinguish skin cancer from different types of skin lesions. Before classifying the skin lesions, data preprocessing and data augmentation methods are used. Finally, a Convolutional Neural Network (CNN) model and six transfer learning models such as Resnet-50, VGG-16, Densenet, Mobilenet, Inceptionv3, and Xception are applied to the publically available benchmark HAM10000 dataset to classify seven classes of skin lesions and to conduct a comparative analysis. The models will detect skin cancer by differentiating the cancerous cell from the non-cancerous ones. The models performance is measured using performance metrics such as precision, recall, f1 score, and accuracy. We receive accuracy of 90, 88, 88, 87, 82, and 77 percent for inceptionv3, Xception, Densenet, Mobilenet, Resnet, CNN, and VGG16, respectively. Furthermore, we develop five different stacking models such as inceptionv3-inceptionv3, Densenet-mobilenet, inceptionv3-Xception, Resnet50-Vgg16, and stack-six for classifying the skin lesions and found that the stacking models perform poorly. We achieve the highest accuracy of 78 percent among all the stacking models.
Handwritten Word Recognition using Deep Learning Approach: A Novel Way of Generating Handwritten Words
Mar 13, 2023



A handwritten word recognition system comes with issues such as lack of large and diverse datasets. It is necessary to resolve such issues since millions of official documents can be digitized by training deep learning models using a large and diverse dataset. Due to the lack of data availability, the trained model does not give the expected result. Thus, it has a high chance of showing poor results. This paper proposes a novel way of generating diverse handwritten word images using handwritten characters. The idea of our project is to train the BiLSTM-CTC architecture with generated synthetic handwritten words. The whole approach shows the process of generating two types of large and diverse handwritten word datasets: overlapped and non-overlapped. Since handwritten words also have issues like overlapping between two characters, we have tried to put it into our experimental part. We have also demonstrated the process of recognizing handwritten documents using the deep learning model. For the experiments, we have targeted the Bangla language, which lacks the handwritten word dataset, and can be followed for any language. Our approach is less complex and less costly than traditional GAN models. Finally, we have evaluated our model using Word Error Rate (WER), accuracy, f1-score, precision, and recall metrics. The model gives 39% WER score, 92% percent accuracy, and 92% percent f1 scores using non-overlapped data and 63% percent WER score, 83% percent accuracy, and 85% percent f1 scores using overlapped data.
Automated Vulnerability Detection in Source Code Using Quantum Natural Language Processing
Mar 13, 2023One of the most important challenges in the field of software code audit is the presence of vulnerabilities in software source code. These flaws are highly likely ex-ploited and lead to system compromise, data leakage, or denial of ser-vice. C and C++ open source code are now available in order to create a large-scale, classical machine-learning and quantum machine-learning system for function-level vulnerability identification. We assembled a siz-able dataset of millions of open-source functions that point to poten-tial exploits. We created an efficient and scalable vulnerability detection method based on a deep neural network model Long Short Term Memory (LSTM), and quantum machine learning model Long Short Term Memory (QLSTM), that can learn features extracted from the source codes. The source code is first converted into a minimal intermediate representation to remove the pointless components and shorten the de-pendency. Therefore, We keep the semantic and syntactic information using state of the art word embedding algorithms such as Glove and fastText. The embedded vectors are subsequently fed into the classical and quantum convolutional neural networks to classify the possible vulnerabilities. To measure the performance, we used evaluation metrics such as F1 score, precision, re-call, accuracy, and total execution time. We made a comparison between the results derived from the classical LSTM and quantum LSTM using basic feature representation as well as semantic and syntactic represen-tation. We found that the QLSTM with semantic and syntactic features detects significantly accurate vulnerability and runs faster than its classical counterpart.