 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermal Imaging for Contactless Cardiorespiratory and Sudomotor Response Monitoring
Feb 12, 2026Thermal infrared imaging captures skin temperature changes driven by autonomic regulation and can potentially provide contactless estimation of electrodermal activity (EDA), heart rate (HR), and breathing rate (BR). While visible-light methods address HR and BR, they cannot access EDA, a standard marker of sympathetic activation. This paper characterizes the extraction of these three biosignals from facial thermal video using a signal-processing pipeline that tracks anatomical regions, applies spatial aggregation, and separates slow sudomotor trends from faster cardiorespiratory components. For HR, we apply an orthogonal matrix image transformation (OMIT) decomposition across multiple facial regions of interest (ROIs), and for BR we average nasal and cheek signals before spectral peak detection. We evaluate 288 EDA configurations and the HR/BR pipeline on 31 sessions from the public SIMULATOR STUDY 1 (SIM1) driver monitoring dataset. The best fixed EDA configuration (nose region, exponential moving average) reaches a mean absolute correlation of $0.40 \pm 0.23$ against palm EDA, with individual sessions reaching 0.89. BR estimation achieves a mean absolute error of $3.1 \pm 1.1$ bpm, while HR estimation yields $13.8 \pm 7.5$ bpm MAE, limited by the low camera frame rate (7.5 Hz). We report signal polarity alternation across sessions, short thermodynamic latency for well-tracked signals, and condition-dependent and demographic effects on extraction quality. These results provide baseline performance bounds and design guidance for thermal contactless biosignal estimation.
Harmonic LLMs are Trustworthy
Apr 30, 2024We introduce an intuitive method to test the robustness (stability and explainability) of any black-box LLM in real-time, based upon the local deviation from harmoniticity, denoted as $\gamma$. To the best of our knowledge this is the first completely model-agnostic and unsupervised method of measuring the robustness of any given response from an LLM, based upon the model itself conforming to a purely mathematical standard. We conduct human annotation experiments to show the positive correlation of $\gamma$ with false or misleading answers, and demonstrate that following the gradient of $\gamma$ in stochastic gradient ascent efficiently exposes adversarial prompts. Measuring $\gamma$ across thousands of queries in popular LLMs (GPT-4, ChatGPT, Claude-2.1, Mixtral-8x7B, Smaug-72B, Llama2-7B, and MPT-7B) allows us to estimate the liklihood of wrong or hallucinatory answers automatically and quantitatively rank the reliability of these models in various objective domains (Web QA, TruthfulQA, and Programming QA). Across all models and domains tested, human ratings confirm that $\gamma \to 0$ indicates trustworthiness, and the low-$\gamma$ leaders among these models are GPT-4, ChatGPT, and Smaug-72B.
FSDR: A Novel Deep Learning-based Feature Selection Algorithm for Pseudo Time-Series Data using Discrete Relaxation
Mar 13, 2024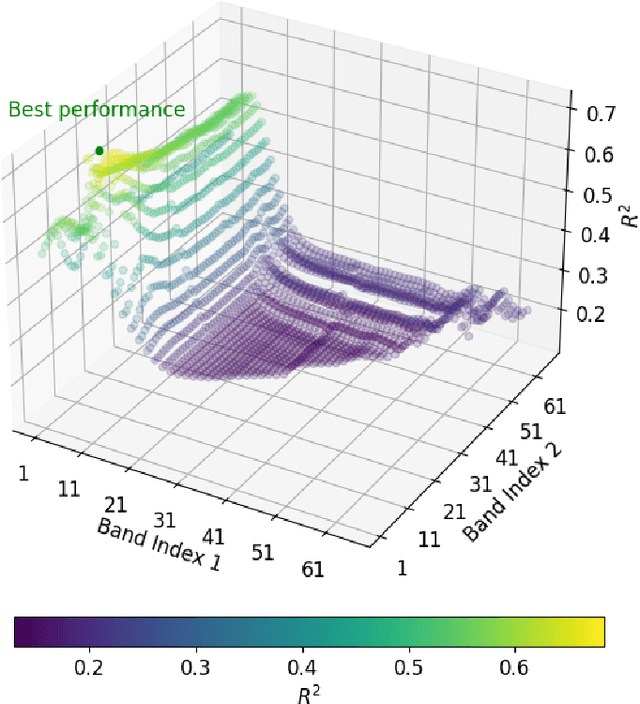
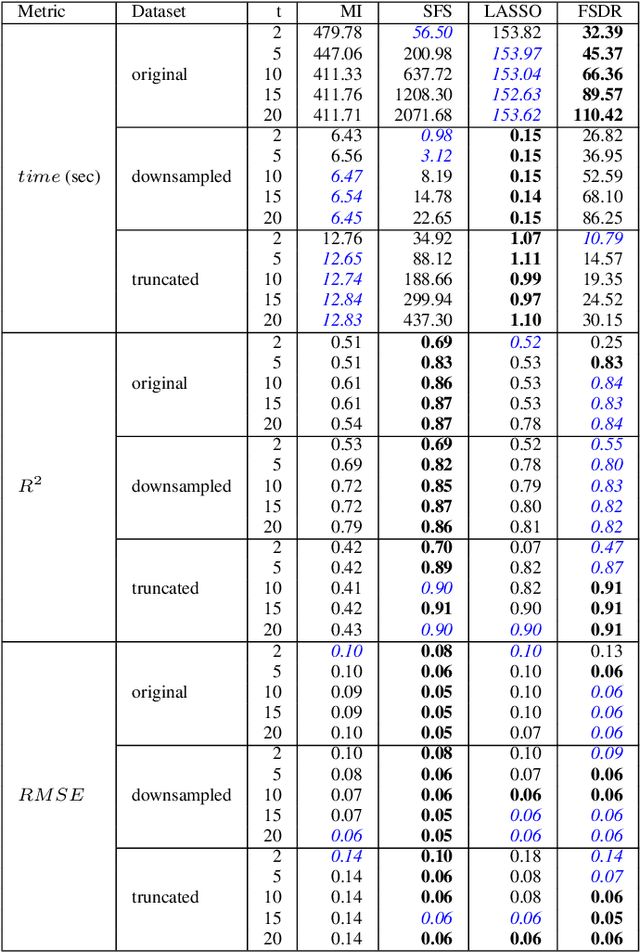
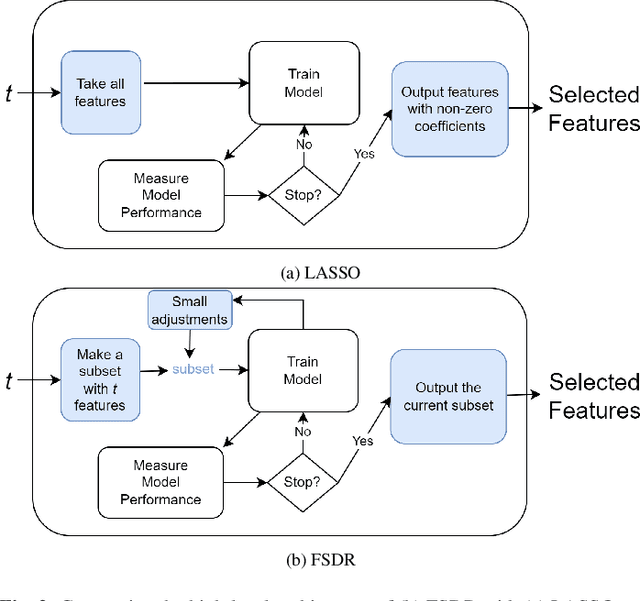
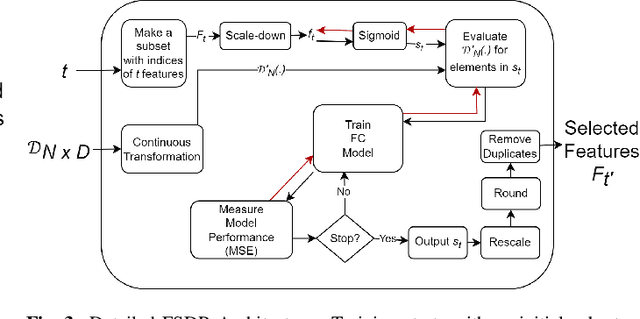
Conventional feature selection algorithms applied to Pseudo Time-Series (PTS) data, which consists of observations arranged in sequential order without adhering to a conventional temporal dimension, often exhibit impractical computational complexities with high dimensional data. To address this challenge, we introduce a Deep Learning (DL)-based feature selection algorithm: Feature Selection through Discrete Relaxation (FSDR), tailored for PTS data. Unlike the existing feature selection algorithms, FSDR learns the important features as model parameters using discrete relaxation, which refers to the process of approximating a discrete optimisation problem with a continuous one. FSDR is capable of accommodating a high number of feature dimensions, a capability beyond the reach of existing DL-based or traditional methods. Through testing on a hyperspectral dataset (i.e., a type of PTS data), our experimental results demonstrate that FSDR outperforms three commonly used feature selection algorithms, taking into account a balance among execution time, $R^2$, and $RMSE$.
Case Study-Based Approach of Quantum Machine Learning in Cybersecurity: Quantum Support Vector Machine for Malware Classification and Protection
Jun 01, 2023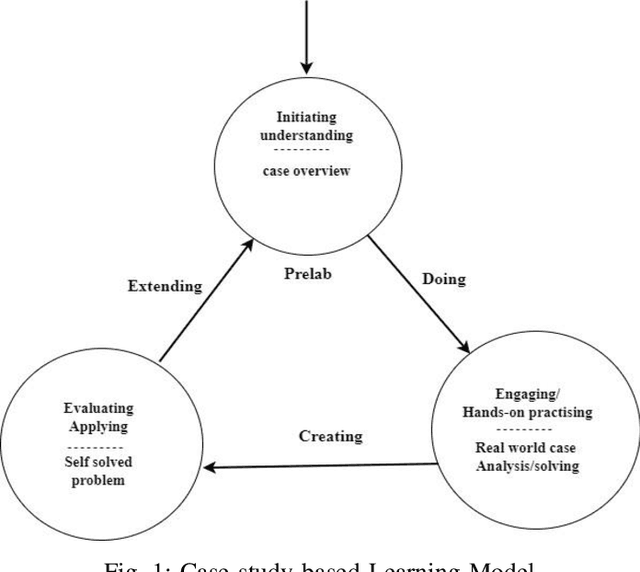
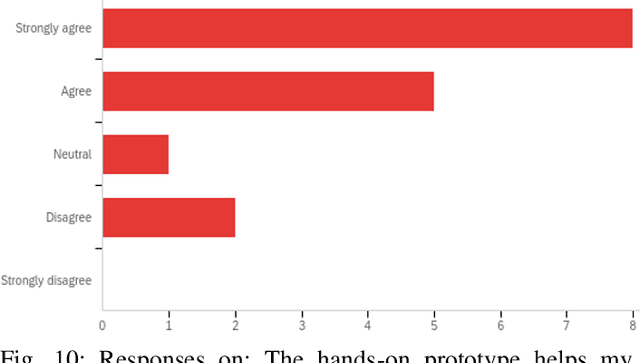
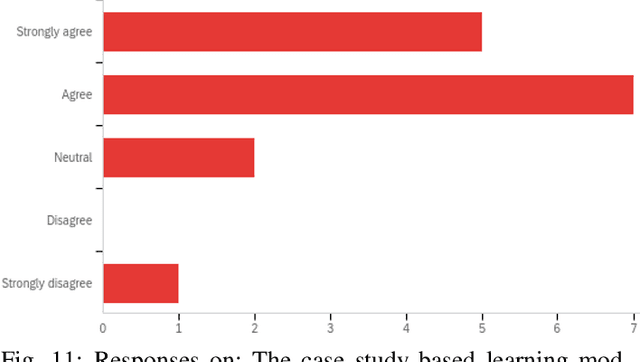

Quantum machine learning (QML) is an emerging field of research that leverages quantum computing to improve the classical machine learning approach to solve complex real world problems. QML has the potential to address cybersecurity related challenges. Considering the novelty and complex architecture of QML, resources are not yet explicitly available that can pave cybersecurity learners to instill efficient knowledge of this emerging technology. In this research, we design and develop QML-based ten learning modules covering various cybersecurity topics by adopting student centering case-study based learning approach. We apply one subtopic of QML on a cybersecurity topic comprised of pre-lab, lab, and post-lab activities towards providing learners with hands-on QML experiences in solving real-world security problems. In order to engage and motivate students in a learning environment that encourages all students to learn, pre-lab offers a brief introduction to both the QML subtopic and cybersecurity problem. In this paper, we utilize quantum support vector machine (QSVM) for malware classification and protection where we use open source Pennylane QML framework on the drebin215 dataset. We demonstrate our QSVM model and achieve an accuracy of 95% in malware classification and protection. We will develop all the modules and introduce them to the cybersecurity community in the coming days.
A New Statistical Framework for Genetic Pleiotropic Analysis of High Dimensional Phenotype Data
Dec 03, 2015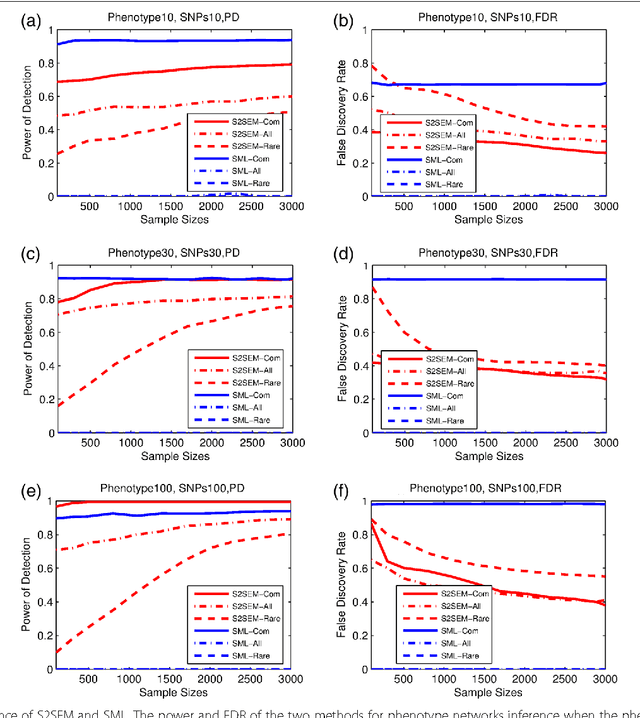
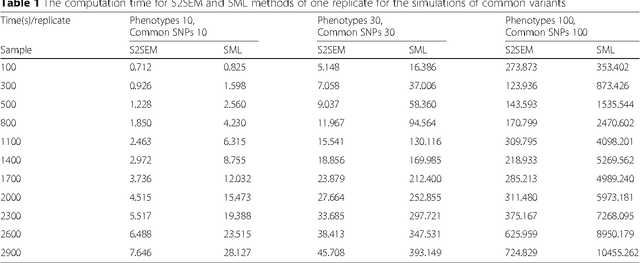
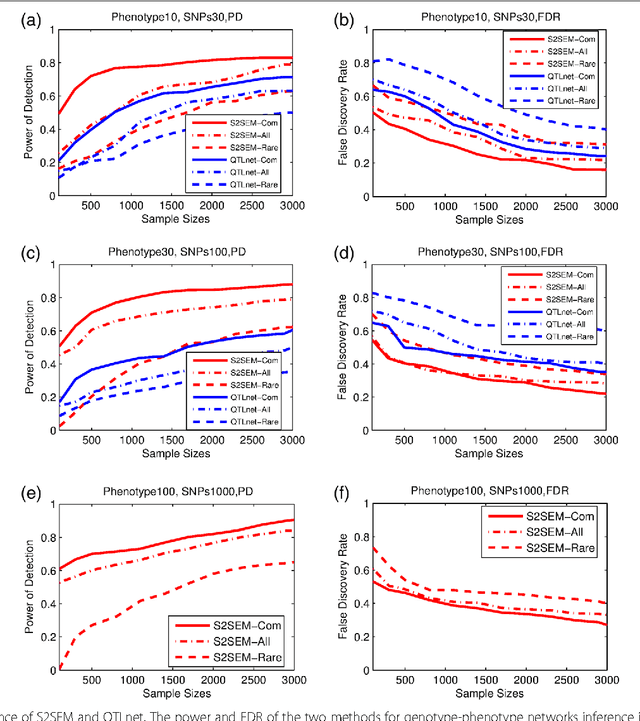
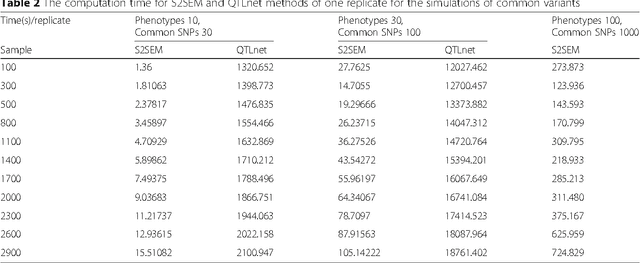
The widely used genetic pleiotropic analysis of multiple phenotypes are often designed for examining the relationship between common variants and a few phenotypes. They are not suited for both high dimensional phenotypes and high dimensional genotype (next-generation sequencing) data. To overcome these limitations, we develop sparse structural equation models (SEMs) as a general framework for a new paradigm of genetic analysis of multiple phenotypes. To incorporate both common and rare variants into the analysis, we extend the traditional multivariate SEMs to sparse functional SEMs. To deal with high dimensional phenotype and genotype data, we employ functional data analysis and the alternative direction methods of multiplier (ADMM) techniques to reduce data dimension and improve computational efficiency. Using large scale simulations we showed that the proposed methods have higher power to detect true causal genetic pleiotropic structure than other existing methods. Simulations also demonstrate that the gene-based pleiotropic analysis has higher power than the single variant-based pleiotropic analysis. The proposed method is applied to exome sequence data from the NHLBI Exome Sequencing Project (ESP) with 11 phenotypes, which identifies a network with 137 genes connected to 11 phenotypes and 341 edges. Among them, 114 genes showed pleiotropic genetic effects and 45 genes were reported to be associated with phenotypes in the analysis or other cardiovascular disease (CVD) related phenotypes in the literature.