 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Efficacy of Sentinel-2 versus Aerial Imagery in Serrated Tussock Classification
Dec 12, 2025Invasive species pose major global threats to ecosystems and agriculture. Serrated tussock (\textit{Nassella trichotoma}) is a highly competitive invasive grass species that disrupts native grasslands, reduces pasture productivity, and increases land management costs. In Victoria, Australia, it presents a major challenge due to its aggressive spread and ecological impact. While current ground surveys and subsequent management practices are effective at small scales, they are not feasible for landscape-scale monitoring. Although aerial imagery offers high spatial resolution suitable for detailed classification, its high cost limits scalability. Satellite-based remote sensing provides a more cost-effective and scalable alternative, though often with lower spatial resolution. This study evaluates whether multi-temporal Sentinel-2 imagery, despite its lower spatial resolution, can provide a comparable and cost-effective alternative for landscape-scale monitoring of serrated tussock by leveraging its higher spectral resolution and seasonal phenological information. A total of eleven models have been developed using various combinations of spectral bands, texture features, vegetation indices, and seasonal data. Using a random forest classifier, the best-performing Sentinel-2 model (M76*) has achieved an Overall Accuracy (OA) of 68\% and an Overall Kappa (OK) of 0.55, slightly outperforming the best-performing aerial imaging model's OA of 67\% and OK of 0.52 on the same dataset. These findings highlight the potential of multi-seasonal feature-enhanced satellite-based models for scalable invasive species classification.
ReflectGAN: Modeling Vegetation Effects for Soil Carbon Estimation from Satellite Imagery
May 24, 2025


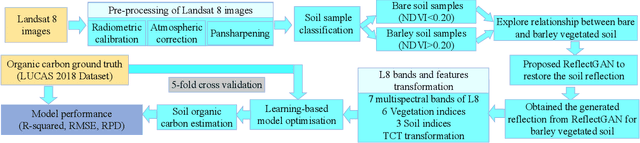
Soil organic carbon (SOC) is a critical indicator of soil health, but its accurate estimation from satellite imagery is hindered in vegetated regions due to spectral contamination from plant cover, which obscures soil reflectance and reduces model reliability. This study proposes the Reflectance Transformation Generative Adversarial Network (ReflectGAN), a novel paired GAN-based framework designed to reconstruct accurate bare soil reflectance from vegetated soil satellite observations. By learning the spectral transformation between vegetated and bare soil reflectance, ReflectGAN facilitates more precise SOC estimation under mixed land cover conditions. Using the LUCAS 2018 dataset and corresponding Landsat 8 imagery, we trained multiple learning-based models on both original and ReflectGAN-reconstructed reflectance inputs. Models trained on ReflectGAN outputs consistently outperformed those using existing vegetation correction methods. For example, the best-performing model (RF) achieved an $R^2$ of 0.54, RMSE of 3.95, and RPD of 2.07 when applied to the ReflectGAN-generated signals, representing a 35\% increase in $R^2$, a 43\% reduction in RMSE, and a 43\% improvement in RPD compared to the best existing method (PMM-SU). The performance of the models with ReflectGAN is also better compared to their counterparts when applied to another dataset, i.e., Sentinel-2 imagery. These findings demonstrate the potential of ReflectGAN to improve SOC estimation accuracy in vegetated landscapes, supporting more reliable soil monitoring.
Hyperspectral Imaging-Based Grain Quality Assessment With Limited Labelled Data
Nov 17, 2024



Recently hyperspectral imaging (HSI)-based grain quality assessment has gained research attention. However, unlike other imaging modalities, HSI data lacks sufficient labelled samples required to effectively train deep convolutional neural network (DCNN)-based classifiers. In this paper, we present a novel approach to grain quality assessment using HSI combined with few-shot learning (FSL) techniques. Traditional methods for grain quality evaluation, while reliable, are invasive, time-consuming, and costly. HSI offers a non-invasive, real-time alternative by capturing both spatial and spectral information. However, a significant challenge in applying DCNNs for HSI-based grain classification is the need for large labelled databases, which are often difficult to obtain. To address this, we explore the use of FSL, which enables models to perform well with limited labelled data, making it a practical solution for real-world applications where rapid deployment is required. We also explored the application of FSL for the classification of hyperspectral images of bulk grains to enable rapid quality assessment at various receival points in the grain supply chain. We evaluated the performance of few-shot classifiers in two scenarios: first, classification of grain types seen during training, and second, generalisation to unseen grain types, a crucial feature for real-world applications. In the first scenario, we introduce a novel approach using pre-computed collective class prototypes (CCPs) to enhance inference efficiency and robustness. In the second scenario, we assess the model's ability to classify novel grain types using limited support examples. Our experimental results show that despite using very limited labelled data for training, our FSL classifiers accuracy is comparable to that of a fully trained classifier trained using a significantly larger labelled database.
FSDR: A Novel Deep Learning-based Feature Selection Algorithm for Pseudo Time-Series Data using Discrete Relaxation
Mar 13, 2024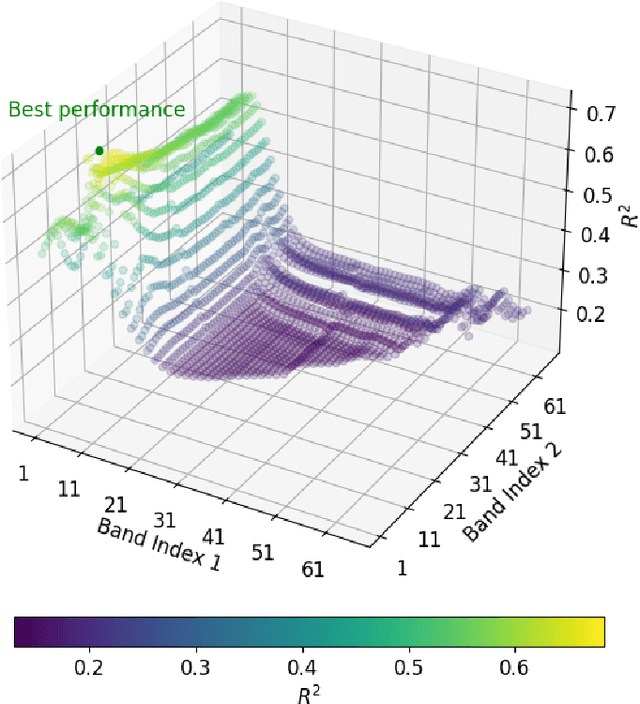
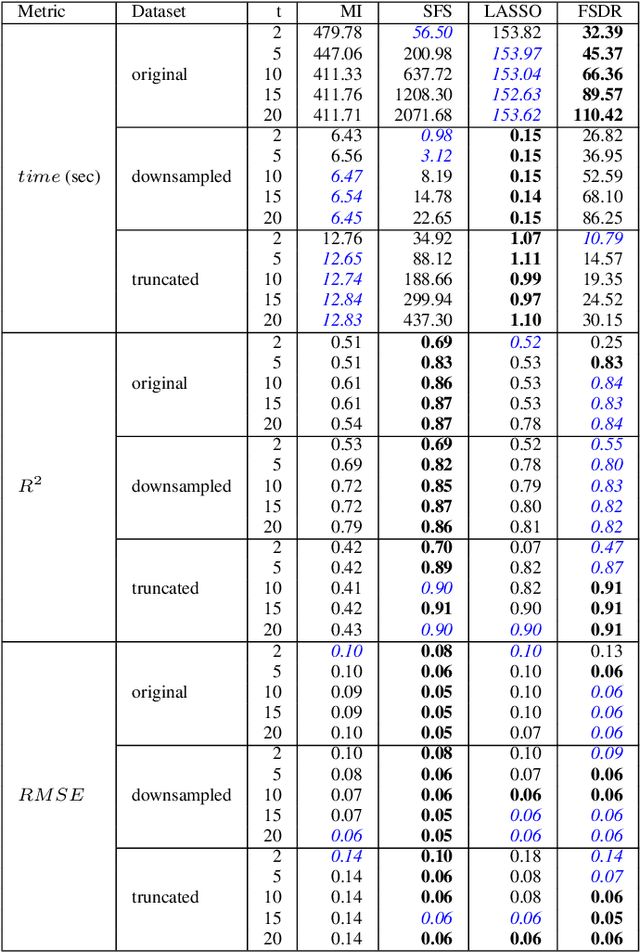
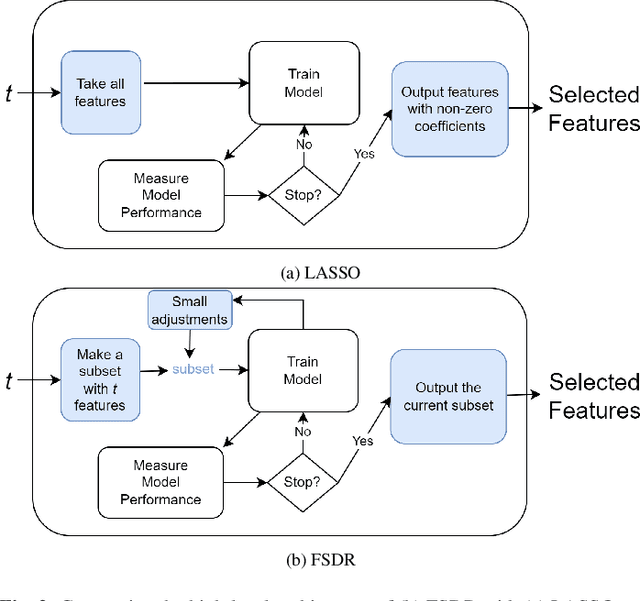
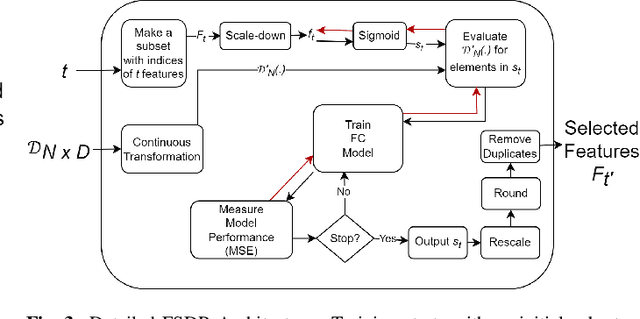
Conventional feature selection algorithms applied to Pseudo Time-Series (PTS) data, which consists of observations arranged in sequential order without adhering to a conventional temporal dimension, often exhibit impractical computational complexities with high dimensional data. To address this challenge, we introduce a Deep Learning (DL)-based feature selection algorithm: Feature Selection through Discrete Relaxation (FSDR), tailored for PTS data. Unlike the existing feature selection algorithms, FSDR learns the important features as model parameters using discrete relaxation, which refers to the process of approximating a discrete optimisation problem with a continuous one. FSDR is capable of accommodating a high number of feature dimensions, a capability beyond the reach of existing DL-based or traditional methods. Through testing on a hyperspectral dataset (i.e., a type of PTS data), our experimental results demonstrate that FSDR outperforms three commonly used feature selection algorithms, taking into account a balance among execution time, $R^2$, and $RMSE$.
Anti-aliasing Deep Image Classifiers using Novel Depth Adaptive Blurring and Activation Function
Oct 03, 2021
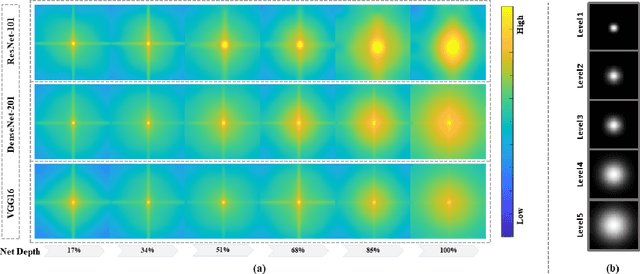


Deep convolutional networks are vulnerable to image translation or shift, partly due to common down-sampling layers, e.g., max-pooling and strided convolution. These operations violate the Nyquist sampling rate and cause aliasing. The textbook solution is low-pass filtering (blurring) before down-sampling, which can benefit deep networks as well. Even so, non-linearity units, such as ReLU, often re-introduce the problem, suggesting that blurring alone may not suffice. In this work, first, we analyse deep features with Fourier transform and show that Depth Adaptive Blurring is more effective, as opposed to monotonic blurring. To this end, we outline how this can replace existing down-sampling methods. Second, we introduce a novel activation function -- with a built-in low pass filter, to keep the problem from reappearing. From experiments, we observe generalisation on other forms of transformations and corruptions as well, e.g., rotation, scale, and noise. We evaluate our method under three challenging settings: (1) a variety of image translations; (2) adversarial attacks -- both $\ell_{p}$ bounded and unbounded; and (3) data corruptions and perturbations. In each setting, our method achieves state-of-the-art results and improves clean accuracy on various benchmark datasets.
A novel network training approach for open set image recognition
Sep 27, 2021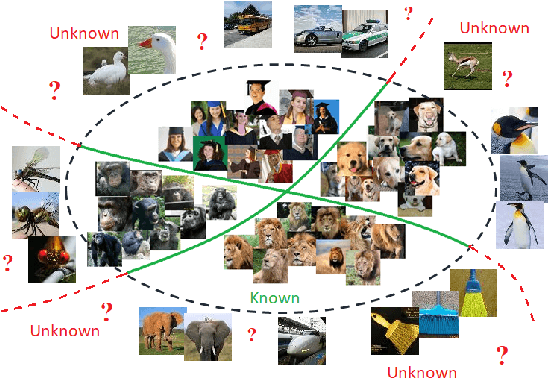
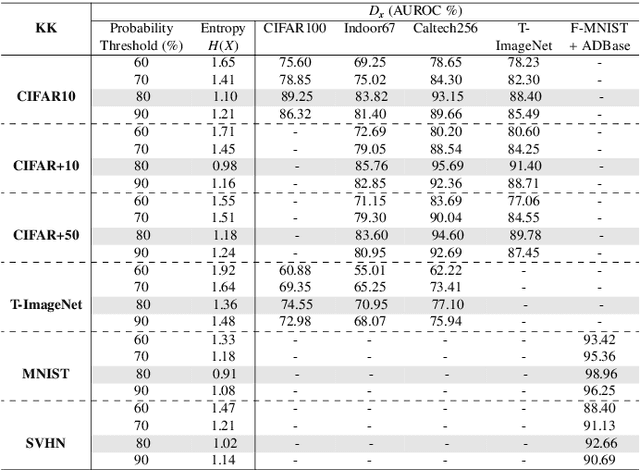
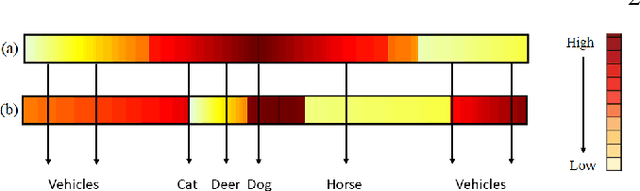
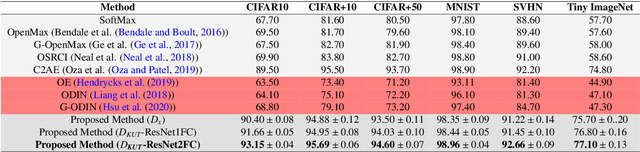
Convolutional Neural Networks (CNNs) are commonly designed for closed set arrangements, where test instances only belong to some "Known Known" (KK) classes used in training. As such, they predict a class label for a test sample based on the distribution of the KK classes. However, when used under the Open Set Recognition (OSR) setup (where an input may belong to an "Unknown Unknown" or UU class), such a network will always classify a test instance as one of the KK classes even if it is from a UU class. As a solution, recently, data augmentation based on Generative Adversarial Networks(GAN) has been used. In this work, we propose a novel approach for mining a "Known UnknownTrainer" or KUT set and design a deep OSR Network (OSRNet) to harness this dataset. The goal isto teach OSRNet the essence of the UUs through KUT set, which is effectively a collection of mined "hard Known Unknown negatives". Once trained, OSRNet can detect the UUs while maintaining high classification accuracy on KKs. We evaluate OSRNet on six benchmark datasets and demonstrate it outperforms contemporary OSR methods.
Network Representation Learning: From Traditional Feature Learning to Deep Learning
Mar 07, 2021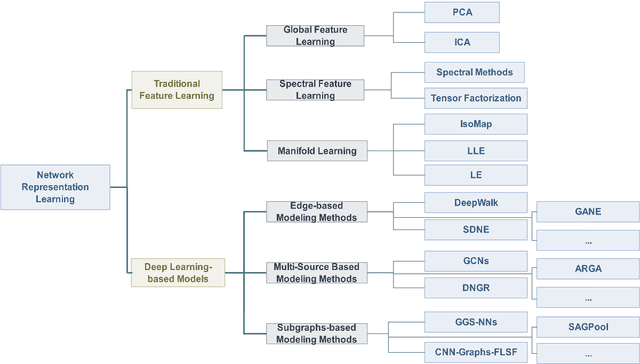
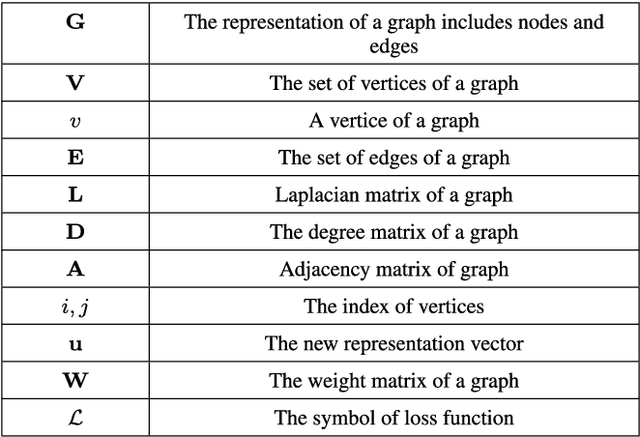
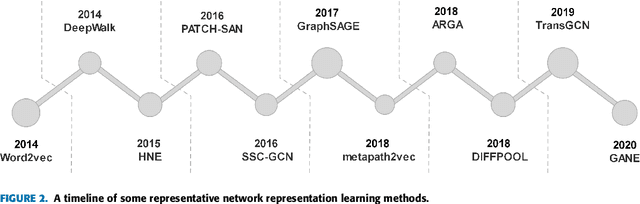

Network representation learning (NRL) is an effective graph analytics technique and promotes users to deeply understand the hidden characteristics of graph data. It has been successfully applied in many real-world tasks related to network science, such as social network data processing, biological information processing, and recommender systems. Deep Learning is a powerful tool to learn data features. However, it is non-trivial to generalize deep learning to graph-structured data since it is different from the regular data such as pictures having spatial information and sounds having temporal information. Recently, researchers proposed many deep learning-based methods in the area of NRL. In this survey, we investigate classical NRL from traditional feature learning method to the deep learning-based model, analyze relationships between them, and summarize the latest progress. Finally, we discuss open issues considering NRL and point out the future directions in this field.
Thank you for Attention: A survey on Attention-based Artificial Neural Networks for Automatic Speech Recognition
Feb 14, 2021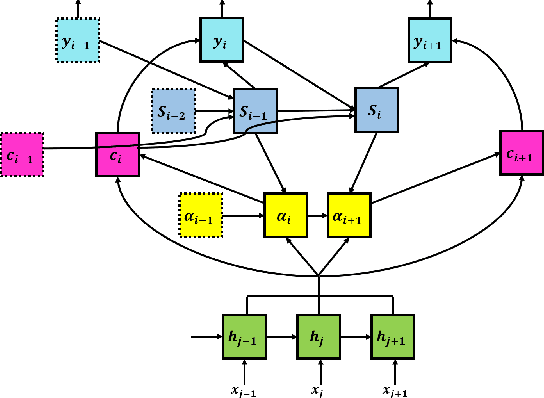
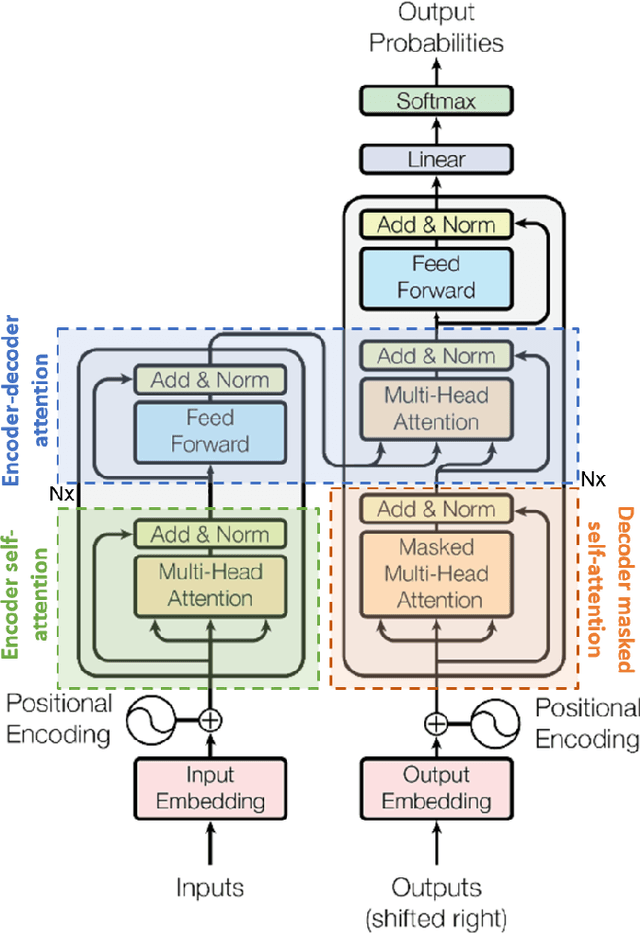
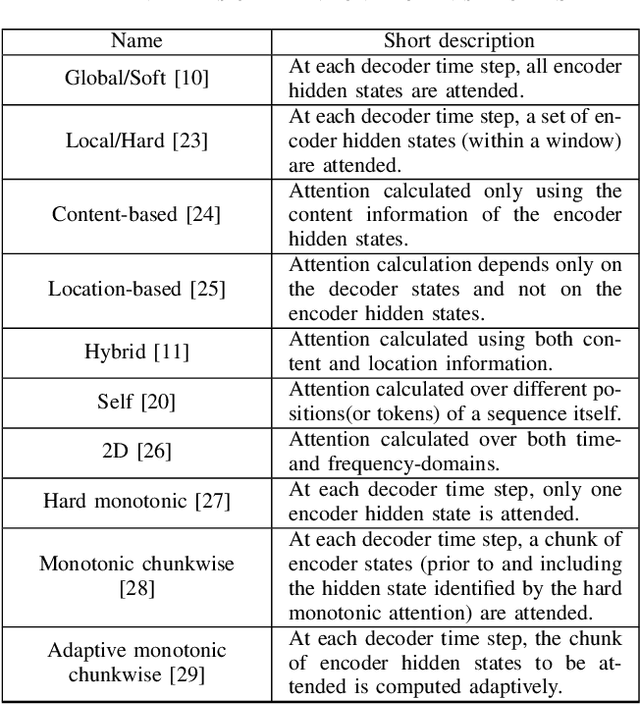
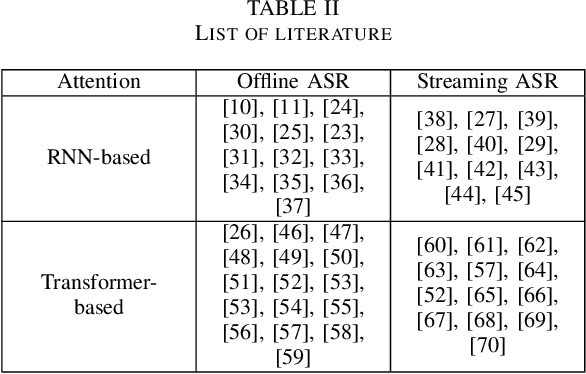
Attention is a very popular and effective mechanism in artificial neural network-based sequence-to-sequence models. In this survey paper, a comprehensive review of the different attention models used in developing automatic speech recognition systems is provided. The paper focuses on the development and evolution of attention models for offline and streaming speech recognition within recurrent neural network- and Transformer- based architectures.
An Integrated Attribute Guided Dense Attention Model for Fine-Grained Generalized Zero-Shot Learning
Feb 05, 2021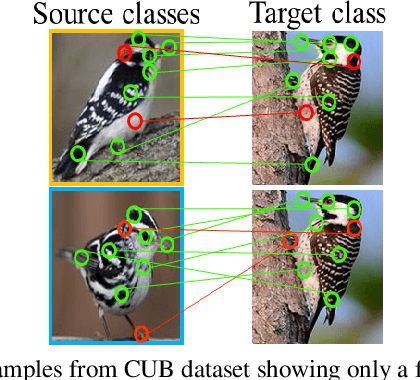
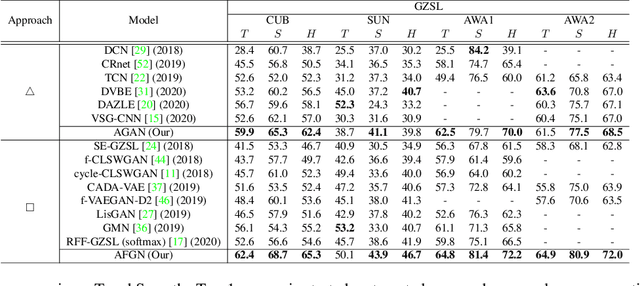
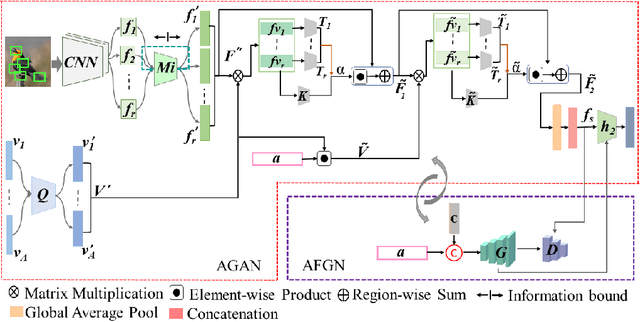
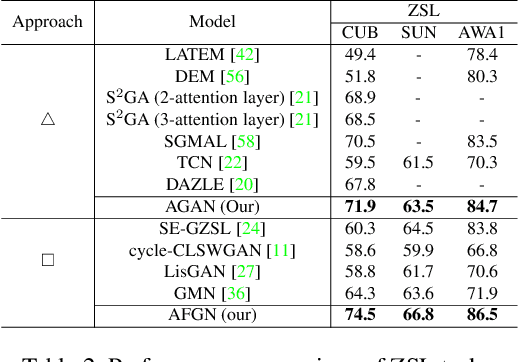
Embedding learning (EL) and feature synthesizing (FS) are two of the popular categories of fine-grained GZSL methods. The global feature exploring EL or FS methods do not explore fine distinction as they ignore local details. And, the local detail exploring EL or FS methods either neglect direct attribute guidance or global information. Consequently, neither method performs well. In this paper, we propose to explore global and direct attribute-supervised local visual features for both EL and FS categories in an integrated manner for fine-grained GZSL. The proposed integrated network has an EL sub-network and a FS sub-network. Consequently, the proposed integrated network can be tested in two ways. We propose a novel two-step dense attention mechanism to discover attribute-guided local visual features. We introduce new mutual learning between the sub-networks to exploit mutually beneficial information for optimization. Moreover, to reduce bias towards the source domain during testing, we propose to compute source-target class similarity based on mutual information and transfer-learn the target classes. We demonstrate that our proposed method outperforms contemporary methods on benchmark datasets.
Bidirectional Mapping Coupled GAN for Generalized Zero-Shot Learning
Dec 30, 2020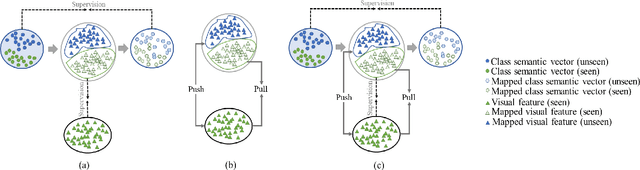
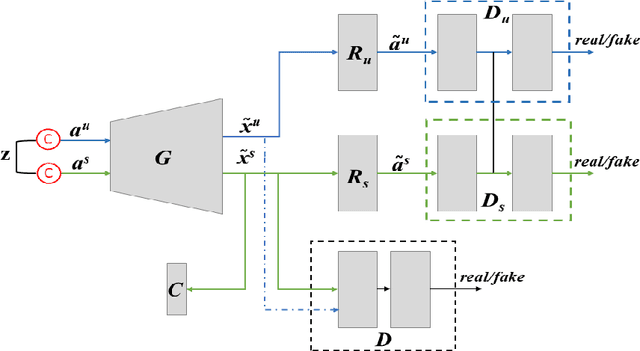

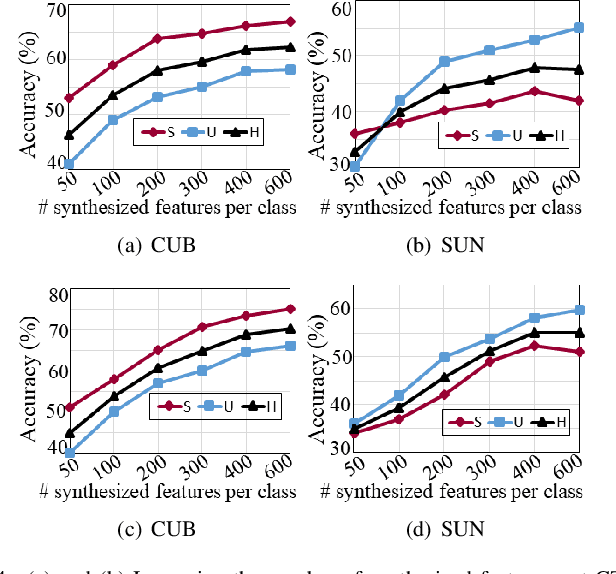
Bidirectional mapping-based generative models have achieved remarkable performance for the generalized zero-shot learning (GZSL) recognition by learning to construct visual features from class semantics and reconstruct class semantics back from generated visual features. The performance of these models relies on the quality of synthesized features. This depends on the ability of the model to capture the underlying seen data distribution by relating semantic-visual spaces, learning discriminative information, and re-purposing the learned distribution to recognize unseen data. This means learning the seen-unseen domains joint distribution is crucial for GZSL tasks. However, existing models only learn the underlying distribution of the seen domain as unseen data is inaccessible. In this work, we propose to utilize the available unseen class semantics along with seen class semantics and learn dual-domain joint distribution through a strong visual-semantic coupling. Therefore, we propose a bidirectional mapping coupled generative adversarial network (BMCoGAN) by extending the coupled generative adversarial network (CoGAN) into a dual-domain learning bidirectional mapping model. We further integrate a Wasserstein generative adversarial optimization to supervise the joint distribution learning. For retaining distinctive information in the synthesized visual space and reducing bias towards seen classes, we design an optimization, which pushes synthesized seen features towards real seen features and pulls synthesized unseen features away from real seen features. We evaluate BMCoGAN on several benchmark datasets against contemporary methods and show its superior performance. Also, we present ablative analysis to demonstrate the importance of different components in BMCoGAN.