 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Integrated Attribute Guided Dense Attention Model for Fine-Grained Generalized Zero-Shot Learning
Feb 05, 2021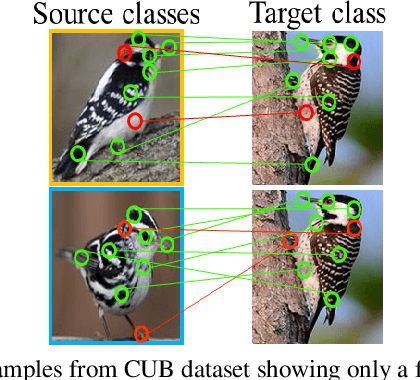
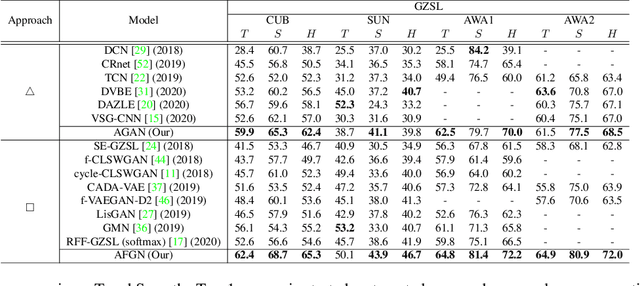
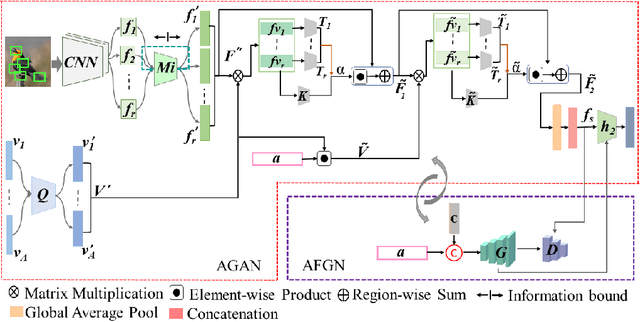
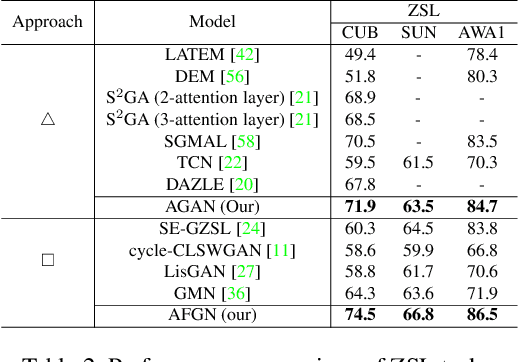
Embedding learning (EL) and feature synthesizing (FS) are two of the popular categories of fine-grained GZSL methods. The global feature exploring EL or FS methods do not explore fine distinction as they ignore local details. And, the local detail exploring EL or FS methods either neglect direct attribute guidance or global information. Consequently, neither method performs well. In this paper, we propose to explore global and direct attribute-supervised local visual features for both EL and FS categories in an integrated manner for fine-grained GZSL. The proposed integrated network has an EL sub-network and a FS sub-network. Consequently, the proposed integrated network can be tested in two ways. We propose a novel two-step dense attention mechanism to discover attribute-guided local visual features. We introduce new mutual learning between the sub-networks to exploit mutually beneficial information for optimization. Moreover, to reduce bias towards the source domain during testing, we propose to compute source-target class similarity based on mutual information and transfer-learn the target classes. We demonstrate that our proposed method outperforms contemporary methods on benchmark datasets.
Bidirectional Mapping Coupled GAN for Generalized Zero-Shot Learning
Dec 30, 2020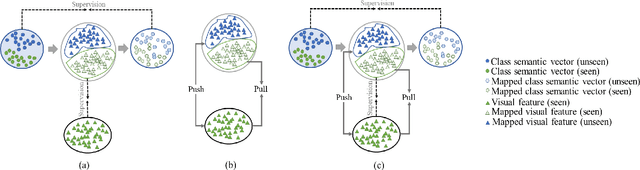
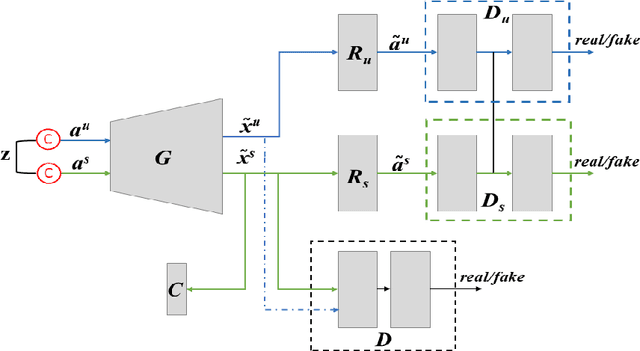

Bidirectional mapping-based generative models have achieved remarkable performance for the generalized zero-shot learning (GZSL) recognition by learning to construct visual features from class semantics and reconstruct class semantics back from generated visual features. The performance of these models relies on the quality of synthesized features. This depends on the ability of the model to capture the underlying seen data distribution by relating semantic-visual spaces, learning discriminative information, and re-purposing the learned distribution to recognize unseen data. This means learning the seen-unseen domains joint distribution is crucial for GZSL tasks. However, existing models only learn the underlying distribution of the seen domain as unseen data is inaccessible. In this work, we propose to utilize the available unseen class semantics along with seen class semantics and learn dual-domain joint distribution through a strong visual-semantic coupling. Therefore, we propose a bidirectional mapping coupled generative adversarial network (BMCoGAN) by extending the coupled generative adversarial network (CoGAN) into a dual-domain learning bidirectional mapping model. We further integrate a Wasserstein generative adversarial optimization to supervise the joint distribution learning. For retaining distinctive information in the synthesized visual space and reducing bias towards seen classes, we design an optimization, which pushes synthesized seen features towards real seen features and pulls synthesized unseen features away from real seen features. We evaluate BMCoGAN on several benchmark datasets against contemporary methods and show its superior performance. Also, we present ablative analysis to demonstrate the importance of different components in BMCoGAN.
Open Set Domain Adaptation with Multi-Classifier Adversarial Network
Jul 08, 2020
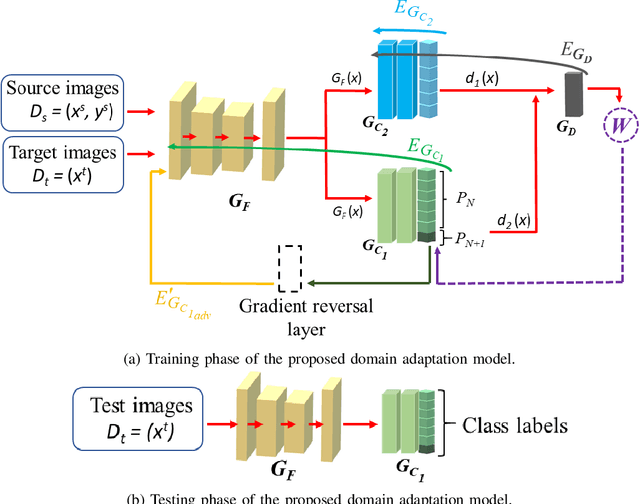

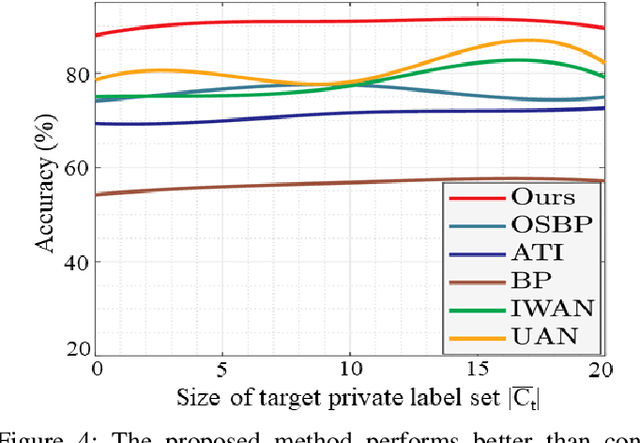
Domain adaptation aims to transfer knowledge from a domain with adequate labeled samples to a domain with scarce labeled samples. The majority of existing domain adaptation methods rely on the assumption of having identical label spaces across the source and target domains, which limits their application in real-world scenarios. To get rid of such an assumption, prior research has introduced various open set domain adaptation settings in the literature. This paper focuses on the type of open set domain adaptation setting where the target domain has both private (`unknown classes') label space beside the shared (`known classes') label space. However, the source domain only has the `known classes' label space. Prevalent distribution-matching domain adaptation methods are inadequate in such a setting that demands adaptation from a smaller source domain to a larger and diverse target domain with more classes. For addressing this specific open set domain adaptation setting, prior research introduces a domain adversarial model with an empirical fixed threshold which lacks at handling false-negative transfers. We propose a multi-classifier based weighting scheme for the adversarial domain adaptation model to address this issue and improve performance. Our proposed method assigns distinguishable weights to target samples belonging to the known and unknown classes to limit false-negative transfers, and simultaneously reduce the domain gap between shared classes of the source and target domains. A thorough evaluation shows that our proposed method outperforms existing domain adaptation methods for a number of domain adaptation datasets.
Depth Augmented Networks with Optimal Fine-tuning
Mar 25, 2019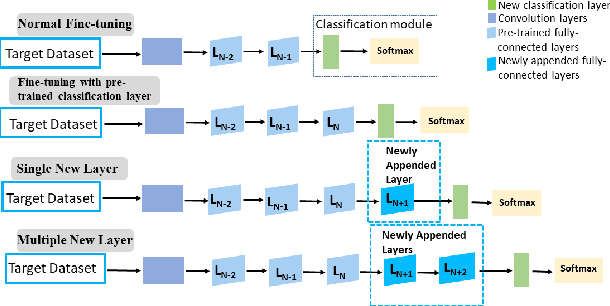
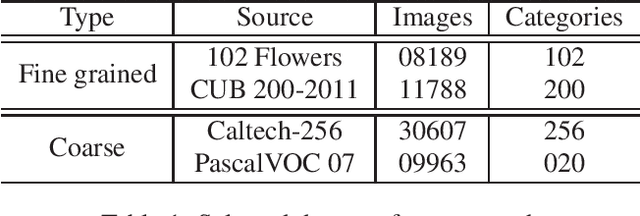
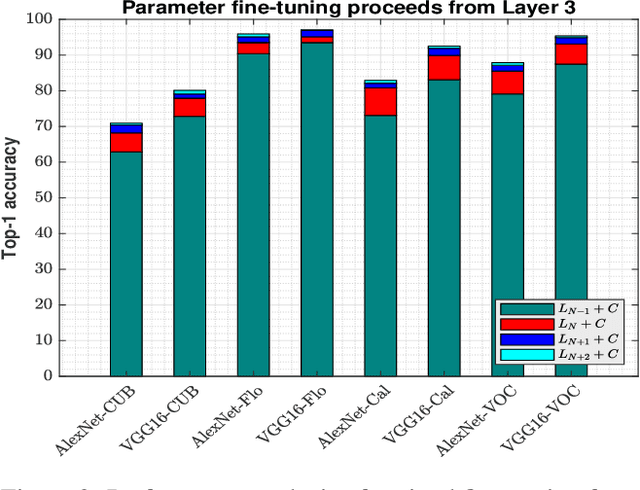

Convolutional neural networks (CNN) have been shown to achieve state-of-the-art performance in a significant number of computer vision tasks. Although they require large labelled training datasets to learn the CNN models, they have striking attributes of transferring learned representations from large source sets to smaller target sets by normal fine-tuning approaches. Prior research has shown that these techniques boost the performance on smaller target sets. In this paper, we demonstrate that growing network depth capacity beyond classification layer along with careful normalization and scaling scheme boosts fine-tuning by creating harmony between the pre-trained and new layers to adjust more to the target task. This indicates pre-trained classification layer holds high-level (global) image information that can be propagated through the newly introduced layers in fine-tuning. We evaluate our depth augmented networks following our designed incremental fine-tuning scheme on several benchmark datatsets and show that they outperform contemporary transfer learning approaches. On average, for fine-grained datasets we achieve up to 6.7% (AlexNet), 5.4% (VGG16) and for coarse datasets 9.3% (AlexNet), 8.7% (VGG16) improvement than normal fine-tuning. In addition, our in-depth analysis manifests freezing highly generic layers encourage better learning of target tasks. Furthermore, we have found that the learning rate for newly introduced layers of depth augmented networks depend on target set and size of new layers.
An Efficient Transfer Learning Technique by Using Final Fully-Connected Layer Output Features of Deep Networks
Nov 19, 2018
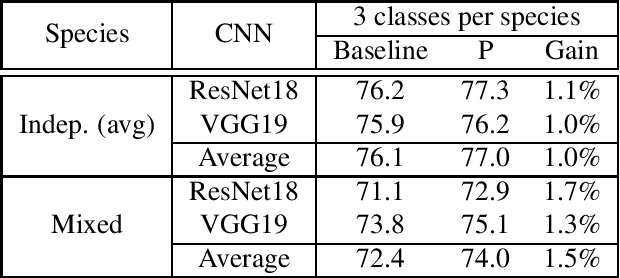
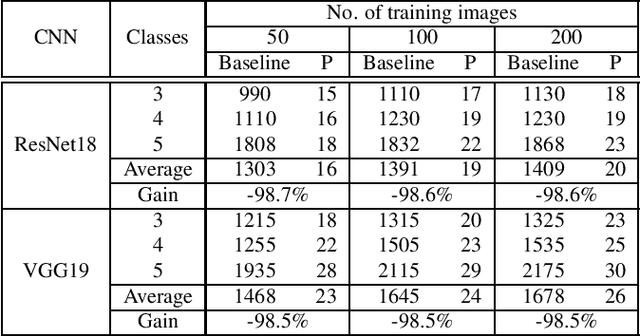
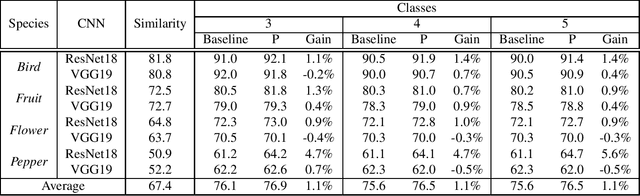
In this paper, we propose a computationally efficient transfer learning approach using the output vector of final fully-connected layer of deep convolutional neural networks for classification. Our proposed technique uses a single layer perceptron classifier designed with hyper-parameters to focus on improving computational efficiency without adversely affecting the performance of classification compared to the baseline technique. Our investigations show that our technique converges much faster than baseline yielding very competitive classification results. We execute thorough experiments to understand the impact of similarity between pre-trained and new classes, similarity among new classes, number of training samples in the performance of classification using transfer learning of the final fully-connected layer's output features.