 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrice-guided user attention in large-scale E-commerce group recommendation
Oct 02, 2024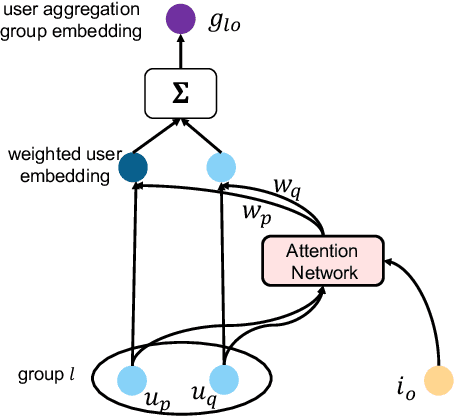
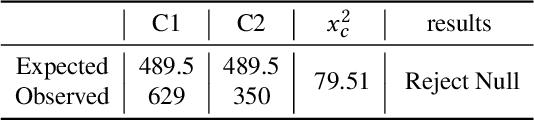
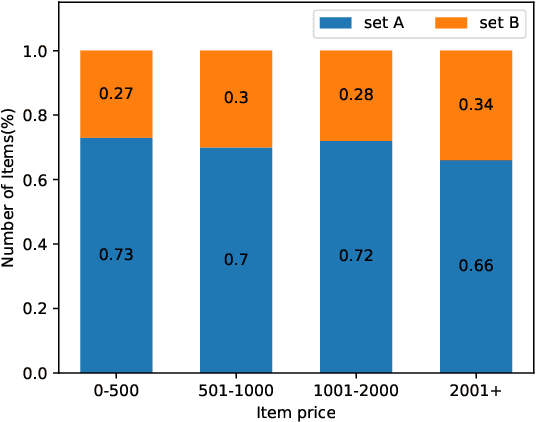
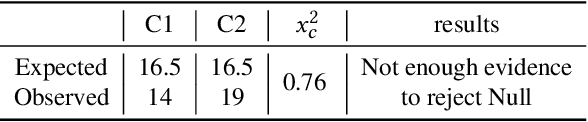
Existing group recommender systems utilize attention mechanisms to identify critical users who influence group decisions the most. We analyzed user attention scores from a widely-used group recommendation model on a real-world E-commerce dataset and found that item price and user interaction history significantly influence the selection of critical users. When item prices are low, users with extensive interaction histories are more influential in group decision-making. Conversely, their influence diminishes with higher item prices. Based on these observations, we propose a novel group recommendation approach that incorporates item price as a guiding factor for user aggregation. Our model employs an adaptive sigmoid function to adjust output logits based on item prices, enhancing the accuracy of user aggregation. Our model can be plugged into any attention-based group recommender system if the price information is available. We evaluate our model's performance on a public benchmark and a real-world dataset. We compare it with other state-of-the-art group recommendation methods. Our results demonstrate that our price-guided user attention approach outperforms the state-of-the-art methods in terms of hit ratio and mean square error.
Meta-Shop: Improving Item Advertisement For Small Businesses
Dec 02, 2022In this paper, we study item advertisements for small businesses. This application recommends prospective customers to specific items requested by businesses. From analysis, we found that the existing Recommender Systems (RS) were ineffective for small/new businesses with a few sales history. Training samples in RS can be highly biased toward popular businesses with sufficient sales and can decrease advertising performance for small businesses. We propose a meta-learning-based RS to improve advertising performance for small/new businesses and shops: Meta-Shop. Meta-Shop leverages an advanced meta-learning optimization framework and builds a model for a shop-level recommendation. It also integrates and transfers knowledge between large and small shops, consequently learning better features in small shops. We conducted experiments on a real-world E-commerce dataset and a public benchmark dataset. Meta-Shop outperformed a production baseline and the state-of-the-art RS models. Specifically, it achieved up to 16.6% relative improvement of Recall@1M and 40.4% relative improvement of nDCG@3 for user recommendations to new shops compared to the other RS models.
One-class Recommendation Systems with the Hinge Pairwise Distance Loss and Orthogonal Representations
Aug 31, 2022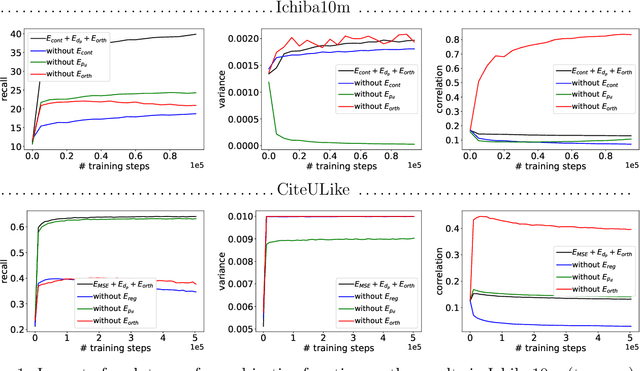
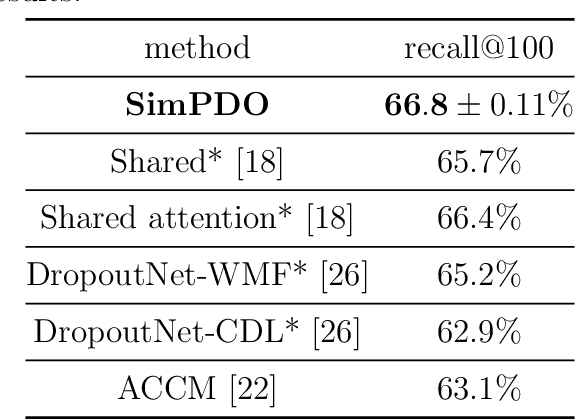

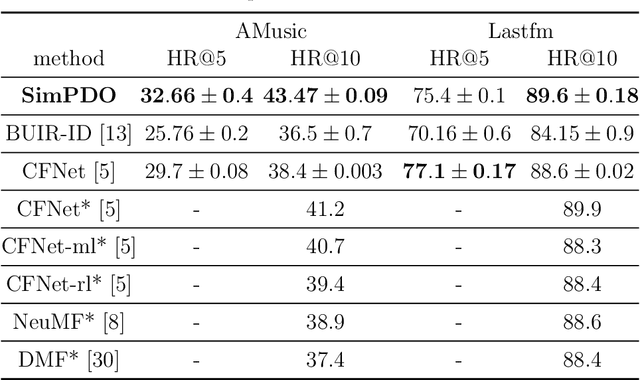
In one-class recommendation systems, the goal is to learn a model from a small set of interacted users and items and then identify the positively-related user-item pairs among a large number of pairs with unknown interactions. Most previous loss functions rely on dissimilar pairs of users and items, which are selected from the ones with unknown interactions, to obtain better prediction performance. This strategy introduces several challenges such as increasing training time and hurting the performance by picking "similar pairs with the unknown interactions" as dissimilar pairs. In this paper, the goal is to only use the similar set to train the models. We point out three trivial solutions that the models converge to when they are trained only on similar pairs: collapsed, partially collapsed, and shrinking solutions. We propose two terms that can be added to the objective functions in the literature to avoid these solutions. The first one is a hinge pairwise distance loss that avoids the shrinking and collapsed solutions by keeping the average pairwise distance of all the representations greater than a margin. The second one is an orthogonality term that minimizes the correlation between the dimensions of the representations and avoids the partially collapsed solution. We conduct experiments on a variety of tasks on public and real-world datasets. The results show that our approach using only similar pairs outperforms state-of-the-art methods using similar pairs and a large number of dissimilar pairs.
Dynamic collaborative filtering Thompson Sampling for cross-domain advertisements recommendation
Aug 25, 2022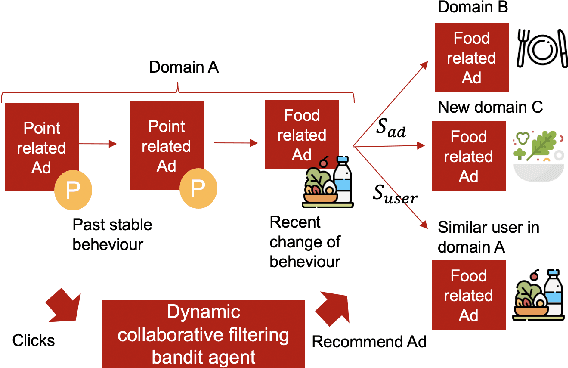


Recently online advertisers utilize Recommender systems (RSs) for display advertising to improve users' engagement. The contextual bandit model is a widely used RS to exploit and explore users' engagement and maximize the long-term rewards such as clicks or conversions. However, the current models aim to optimize a set of ads only in a specific domain and do not share information with other models in multiple domains. In this paper, we propose dynamic collaborative filtering Thompson Sampling (DCTS), the novel yet simple model to transfer knowledge among multiple bandit models. DCTS exploits similarities between users and between ads to estimate a prior distribution of Thompson sampling. Such similarities are obtained based on contextual features of users and ads. Similarities enable models in a domain that didn't have much data to converge more quickly by transferring knowledge. Moreover, DCTS incorporates temporal dynamics of users to track the user's recent change of preference. We first show transferring knowledge and incorporating temporal dynamics improve the performance of the baseline models on a synthetic dataset. Then we conduct an empirical analysis on a real-world dataset and the result showed that DCTS improves click-through rate by 9.7% than the state-of-the-art models. We also analyze hyper-parameters that adjust temporal dynamics and similarities and show the best parameter which maximizes CTR.
Learning Similarity Preserving Binary Codes for Recommender Systems
Apr 18, 2022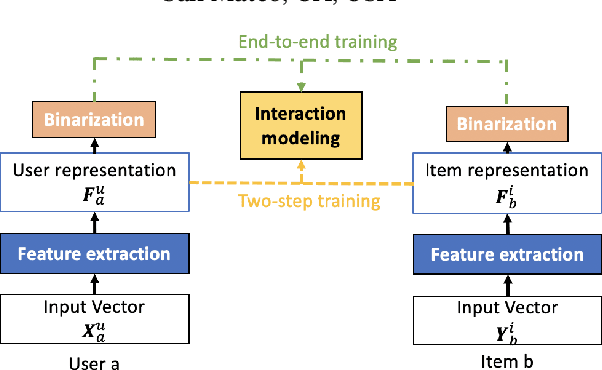
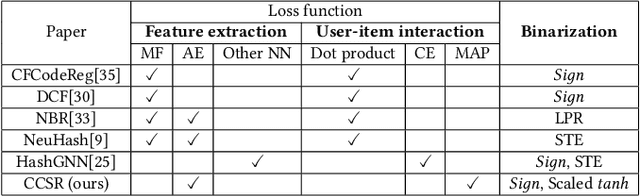
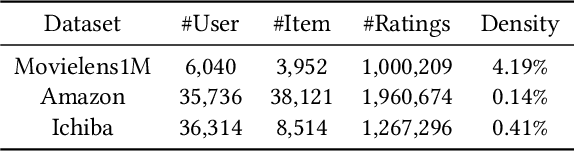
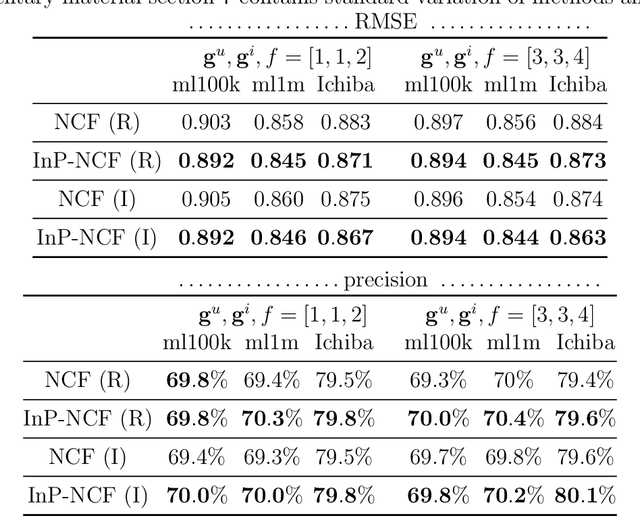
Hashing-based Recommender Systems (RSs) are widely studied to provide scalable services. The existing methods for the systems combine three modules to achieve efficiency: feature extraction, interaction modeling, and binarization. In this paper, we study an unexplored module combination for the hashing-based recommender systems, namely Compact Cross-Similarity Recommender (CCSR). Inspired by cross-modal retrieval, CCSR utilizes Maximum a Posteriori similarity instead of matrix factorization and rating reconstruction to model interactions between users and items. We conducted experiments on MovieLens1M, Amazon product review, Ichiba purchase dataset and confirmed CCSR outperformed the existing matrix factorization-based methods. On the Movielens1M dataset, the absolute performance improvements are up to 15.69% in NDCG and 4.29% in Recall. In addition, we extensively studied three binarization modules: $sign$, scaled tanh, and sign-scaled tanh. The result demonstrated that although differentiable scaled tanh is popular in recent discrete feature learning literature, a huge performance drop occurs when outputs of scaled $tanh$ are forced to be binary.
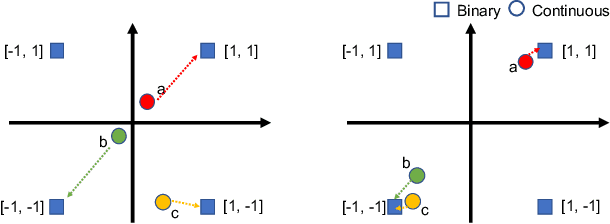
Simultaneous Learning of the Inputs and Parameters in Neural Collaborative Filtering
Mar 14, 2022


Neural network-based collaborative filtering systems focus on designing network architectures to learn better representations while fixing the input to the user/item interaction vectors and/or ID. In this paper, we first show that the non-zero elements of the inputs are learnable parameters that determine the weights in combining the user/item embeddings, and fixing them limits the power of the models in learning the representations. Then, we propose to learn the value of the non-zero elements of the inputs jointly with the neural network parameters. We analyze the model complexity and the empirical risk of our approach and prove that learning the input leads to a better generalization bound. Our experiments on several real-world datasets show that our method outperforms the state-of-the-art methods, even using shallow network structures with a smaller number of layers and parameters.
Efficient Cross-Modal Retrieval via Deep Binary Hashing and Quantization
Feb 15, 2022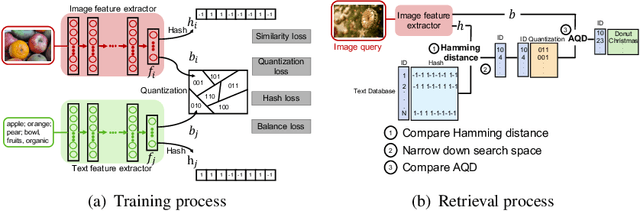

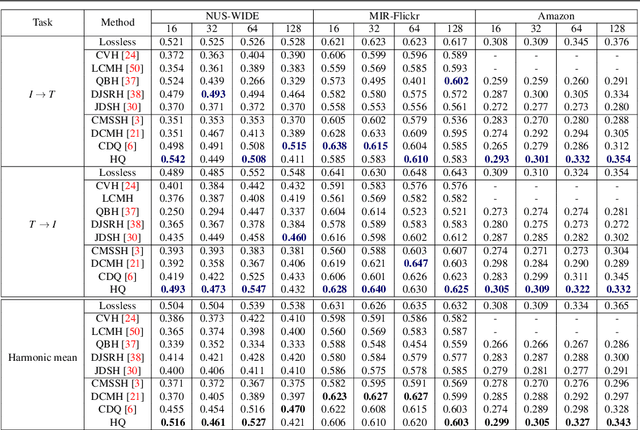
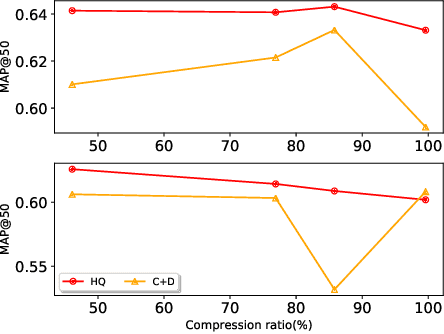
Cross-modal retrieval aims to search for data with similar semantic meanings across different content modalities. However, cross-modal retrieval requires huge amounts of storage and retrieval time since it needs to process data in multiple modalities. Existing works focused on learning single-source compact features such as binary hash codes that preserve similarities between different modalities. In this work, we propose a jointly learned deep hashing and quantization network (HQ) for cross-modal retrieval. We simultaneously learn binary hash codes and quantization codes to preserve semantic information in multiple modalities by an end-to-end deep learning architecture. At the retrieval step, binary hashing is used to retrieve a subset of items from the search space, then quantization is used to re-rank the retrieved items. We theoretically and empirically show that this two-stage retrieval approach provides faster retrieval results while preserving accuracy. Experimental results on the NUS-WIDE, MIR-Flickr, and Amazon datasets demonstrate that HQ achieves boosts of more than 7% in precision compared to supervised neural network-based compact coding models.
* Accepted at BMVC 2021
Recommending Short-lived Dynamic Packages for Golf Booking Services
Mar 13, 2021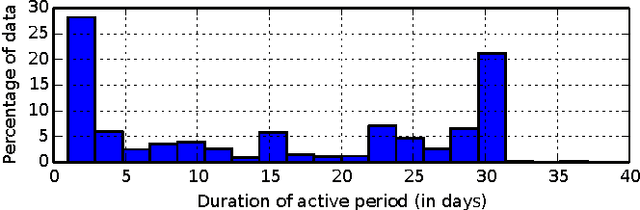
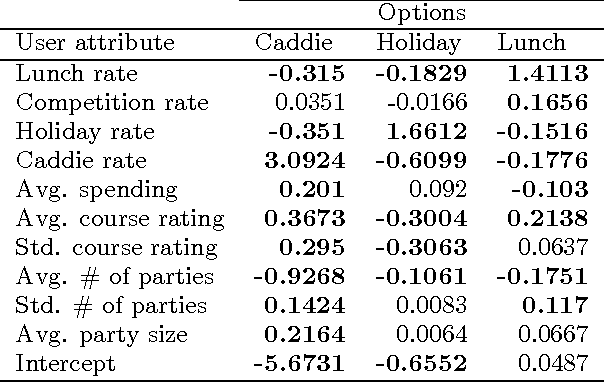
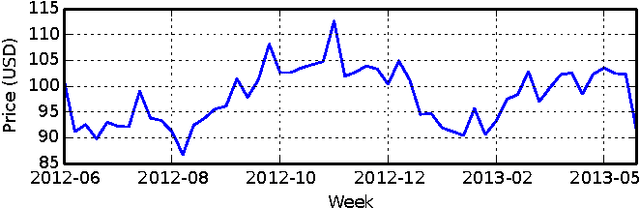

We introduce an approach to recommending short-lived dynamic packages for golf booking services. Two challenges are addressed in this work. The first is the short life of the items, which puts the system in a state of a permanent cold start. The second is the uninformative nature of the package attributes, which makes clustering or figuring latent packages challenging. Although such settings are fairly pervasive, they have not been studied in traditional recommendation research, and there is thus a call for original approaches for recommender systems. In this paper, we introduce a hybrid method that leverages user analysis and its relation to the packages, as well as package pricing and environmental analysis, and traditional collaborative filtering. The proposed approach achieved appreciable improvement in precision compared with baselines.
Neural Representations in Hybrid Recommender Systems: Prediction versus Regularization
Oct 12, 2020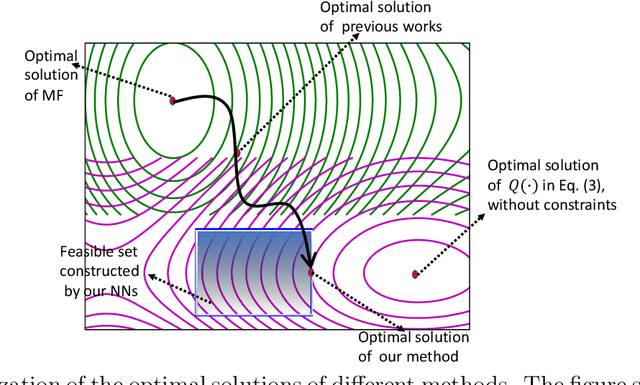
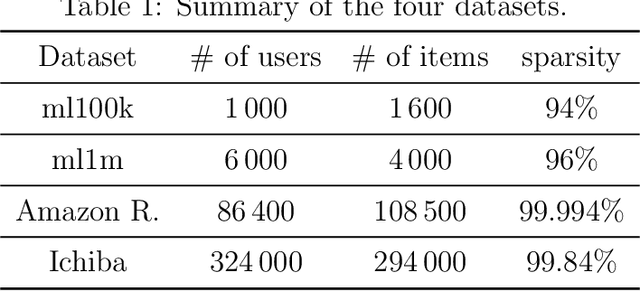
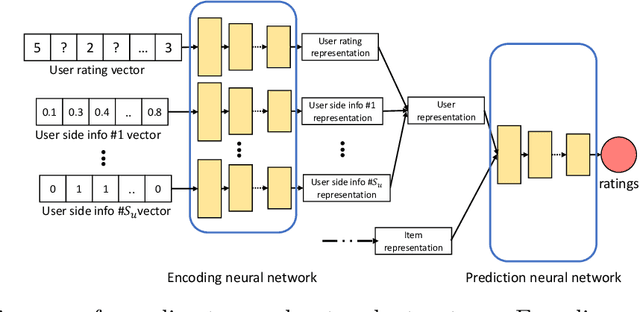
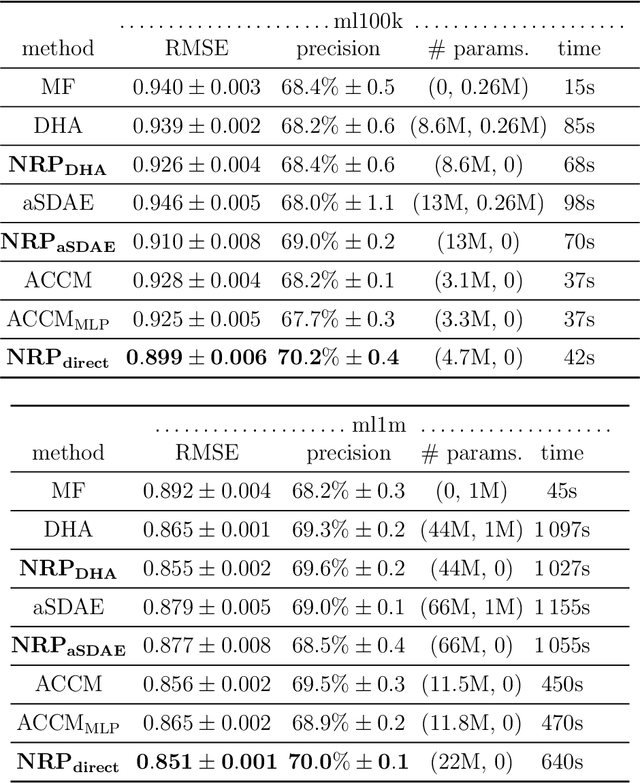
Autoencoder-based hybrid recommender systems have become popular recently because of their ability to learn user and item representations by reconstructing various information sources, including users' feedback on items (e.g., ratings) and side information of users and items (e.g., users' occupation and items' title). However, existing systems still use representations learned by matrix factorization (MF) to predict the rating, while using representations learned by neural networks as the regularizer. In this paper, we define the neural representation for prediction (NRP) framework and apply it to the autoencoder-based recommendation systems. We theoretically analyze how our objective function is related to the previous MF and autoencoder-based methods and explain what it means to use neural representations as the regularizer. We also apply the NRP framework to a direct neural network structure which predicts the ratings without reconstructing the user and item information. We conduct extensive experiments on two MovieLens datasets and two real-world e-commerce datasets. The results confirm that neural representations are better for prediction than regularization and show that the NRP framework, combined with the direct neural network structure, outperforms the state-of-the-art methods in the prediction task, with less training time and memory.