 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving position bias estimation against sparse and skewed dataset with item embedding
May 10, 2023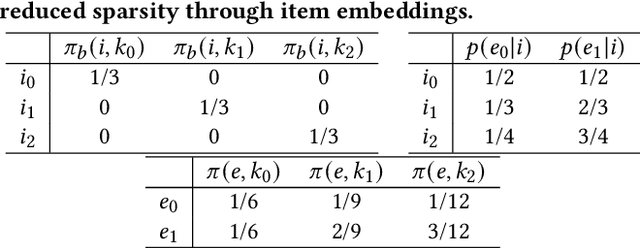
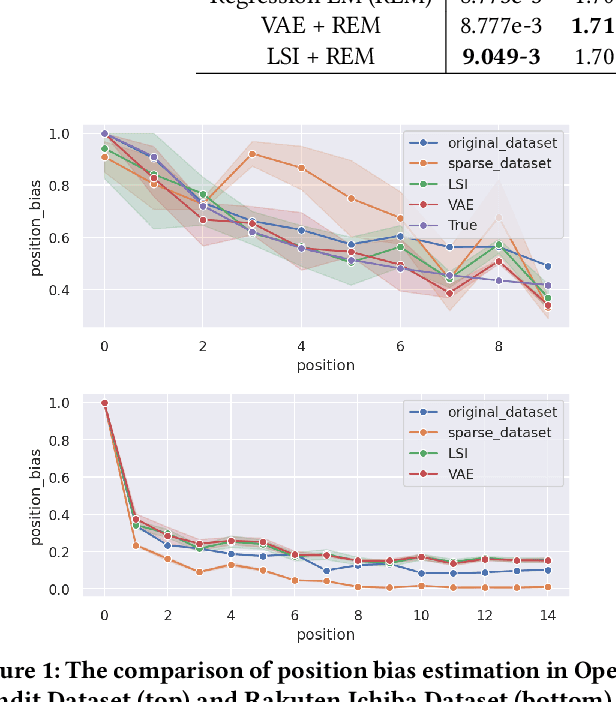
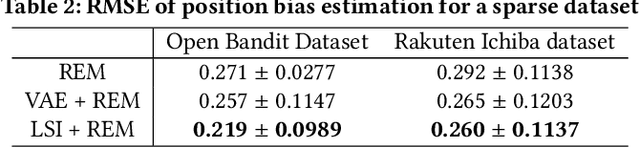
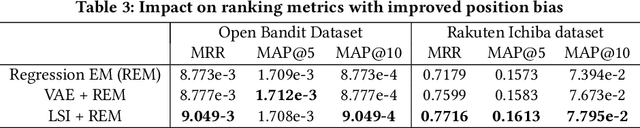
Estimating position bias is a well-known challenge in Learning to rank (L2R). Click data in e-commerce applications, such as advertisement targeting and search engines, provides implicit but abundant feedback to improve personalized rankings. However, click data inherently include various biases like position bias. Click modeling is aimed at denoising biases in click data and extracting reliable signals. Result Randomization and Regression Expectation-maximization algorithm have been proposed to solve position bias. Both methods require various pairs of observations (item, position). However, in real cases of advertising, marketers frequently display advertisements in a fixed pre-determined order, and estimation suffers from it. We propose this sparsity of (item, position) in position bias estimation as a novel problem, and we propose a variant of the Regression EM algorithm which utilizes item embeddings to alleviate the issue of the sparsity. With a synthetic dataset, we first evaluate how the position bias estimation suffers from the sparsity and skewness of the logging dataset. Next, with a real-world dataset, we empirically show that item embedding with Latent Semantic Indexing (LSI) and Variational autoencoder (VAE) improves the estimation of position bias. Our result shows that the Regression EM algorithm with VAE improves RMSE relatively by 10.3% and EM with LSI improves RMSE relatively by 33.4%.
Dynamic collaborative filtering Thompson Sampling for cross-domain advertisements recommendation
Aug 25, 2022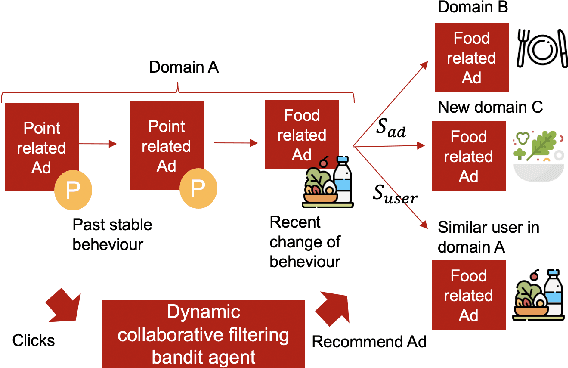
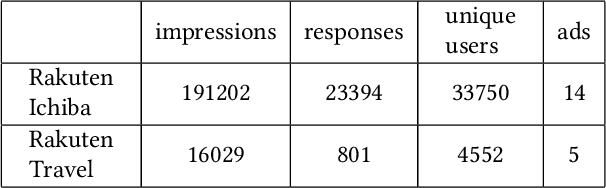


Recently online advertisers utilize Recommender systems (RSs) for display advertising to improve users' engagement. The contextual bandit model is a widely used RS to exploit and explore users' engagement and maximize the long-term rewards such as clicks or conversions. However, the current models aim to optimize a set of ads only in a specific domain and do not share information with other models in multiple domains. In this paper, we propose dynamic collaborative filtering Thompson Sampling (DCTS), the novel yet simple model to transfer knowledge among multiple bandit models. DCTS exploits similarities between users and between ads to estimate a prior distribution of Thompson sampling. Such similarities are obtained based on contextual features of users and ads. Similarities enable models in a domain that didn't have much data to converge more quickly by transferring knowledge. Moreover, DCTS incorporates temporal dynamics of users to track the user's recent change of preference. We first show transferring knowledge and incorporating temporal dynamics improve the performance of the baseline models on a synthetic dataset. Then we conduct an empirical analysis on a real-world dataset and the result showed that DCTS improves click-through rate by 9.7% than the state-of-the-art models. We also analyze hyper-parameters that adjust temporal dynamics and similarities and show the best parameter which maximizes CTR.