 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Sequences with Multi-Scale Dynamics for 4D Reconstruction from Monocular Casual Videos
Feb 14, 2026Understanding dynamic scenes from casual videos is critical for scalable robot learning, yet four-dimensional (4D) reconstruction under strictly monocular settings remains highly ill-posed. To address this challenge, our key insight is that real-world dynamics exhibits a multi-scale regularity from object to particle level. To this end, we design the multi-scale dynamics mechanism that factorizes complex motion fields. Within this formulation, we propose Gaussian sequences with multi-scale dynamics, a novel representation for dynamic 3D Gaussians derived through compositions of multi-level motion. This layered structure substantially alleviates ambiguity of reconstruction and promotes physically plausible dynamics. We further incorporate multi-modal priors from vision foundation models to establish complementary supervision, constraining the solution space and improving the reconstruction fidelity. Our approach enables accurate and globally consistent 4D reconstruction from monocular casual videos. Experiments of dynamic novel-view synthesis (NVS) on benchmark and real-world manipulation datasets demonstrate considerable improvements over existing methods.
Egocentric Instruction-oriented Affordance Prediction via Large Multimodal Model
Aug 25, 2025Affordance is crucial for intelligent robots in the context of object manipulation. In this paper, we argue that affordance should be task-/instruction-dependent, which is overlooked by many previous works. That is, different instructions can lead to different manipulation regions and directions even for the same object. According to this observation, we present a new dataset comprising fifteen thousand object-instruction-affordance triplets. All scenes in the dataset are from an egocentric viewpoint, designed to approximate the perspective of a human-like robot. Furthermore, we investigate how to enable large multimodal models (LMMs) to serve as affordance predictors by implementing a ``search against verifiers'' pipeline. An LMM is asked to progressively predict affordances, with the output at each step being verified by itself during the iterative process, imitating a reasoning process. Experiments show that our method not only unlocks new instruction-oriented affordance prediction capabilities, but also achieves outstanding performance broadly.
Stimulating Imagination: Towards General-purpose Object Rearrangement
Aug 03, 2024



General-purpose object placement is a fundamental capability of an intelligent generalist robot, i.e., being capable of rearranging objects following human instructions even in novel environments. To achieve this, we break the rearrangement down into three parts, including object localization, goal imagination and robot control, and propose a framework named SPORT. SPORT leverages pre-trained large vision models for broad semantic reasoning about objects, and learns a diffusion-based 3D pose estimator to ensure physically-realistic results. Only object types (to be moved or reference) are communicated between these two parts, which brings two benefits. One is that we can fully leverage the powerful ability of open-set object localization and recognition since no specific fine-tuning is needed for robotic scenarios. Furthermore, the diffusion-based estimator only need to "imagine" the poses of the moving and reference objects after the placement, while no necessity for their semantic information. Thus the training burden is greatly reduced and no massive training is required. The training data for goal pose estimation is collected in simulation and annotated with GPT-4. A set of simulation and real-world experiments demonstrate the potential of our approach to accomplish general-purpose object rearrangement, placing various objects following precise instructions.
VideoTetris: Towards Compositional Text-to-Video Generation
Jun 06, 2024
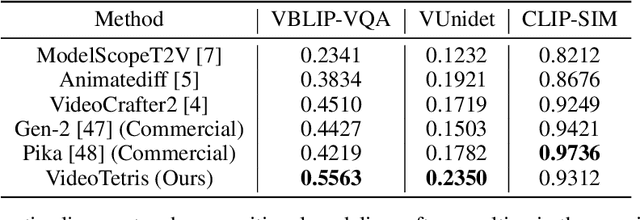
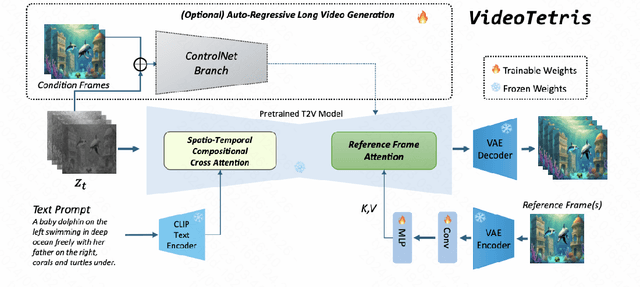

Diffusion models have demonstrated great success in text-to-video (T2V) generation. However, existing methods may face challenges when handling complex (long) video generation scenarios that involve multiple objects or dynamic changes in object numbers. To address these limitations, we propose VideoTetris, a novel framework that enables compositional T2V generation. Specifically, we propose spatio-temporal compositional diffusion to precisely follow complex textual semantics by manipulating and composing the attention maps of denoising networks spatially and temporally. Moreover, we propose an enhanced video data preprocessing to enhance the training data regarding motion dynamics and prompt understanding, equipped with a new reference frame attention mechanism to improve the consistency of auto-regressive video generation. Extensive experiments demonstrate that our VideoTetris achieves impressive qualitative and quantitative results in compositional T2V generation. Code is available at: https://github.com/YangLing0818/VideoTetris
Exploiting Behavioral Consistence for Universal User Representation
Dec 11, 2020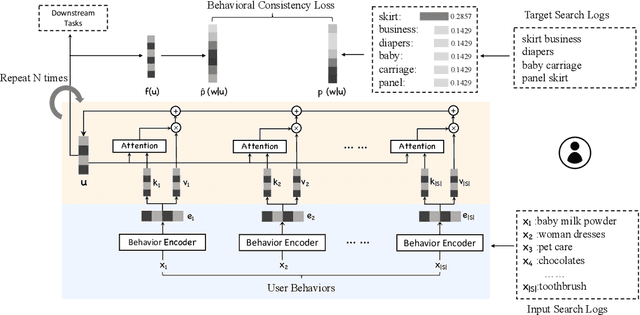
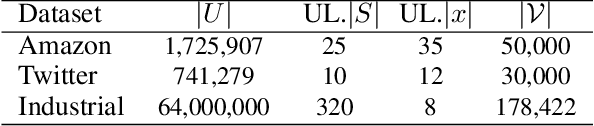
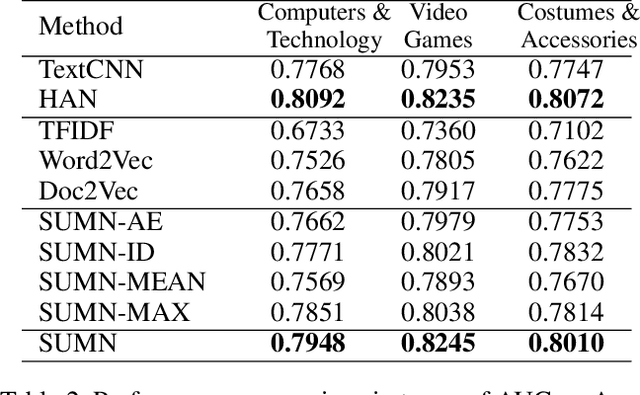
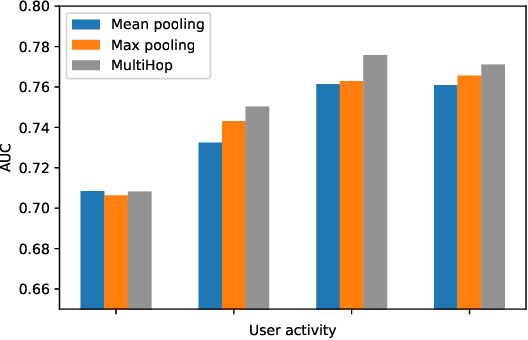
User modeling is critical for developing personalized services in industry. A common way for user modeling is to learn user representations that can be distinguished by their interests or preferences. In this work, we focus on developing universal user representation model. The obtained universal representations are expected to contain rich information, and be applicable to various downstream applications without further modifications (e.g., user preference prediction and user profiling). Accordingly, we can be free from the heavy work of training task-specific models for every downstream task as in previous works. In specific, we propose Self-supervised User Modeling Network (SUMN) to encode behavior data into the universal representation. It includes two key components. The first one is a new learning objective, which guides the model to fully identify and preserve valuable user information under a self-supervised learning framework. The other one is a multi-hop aggregation layer, which benefits the model capacity in aggregating diverse behaviors. Extensive experiments on benchmark datasets show that our approach can outperform state-of-the-art unsupervised representation methods, and even compete with supervised ones.