 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoTetris: Towards Compositional Text-to-Video Generation
Paper and Code

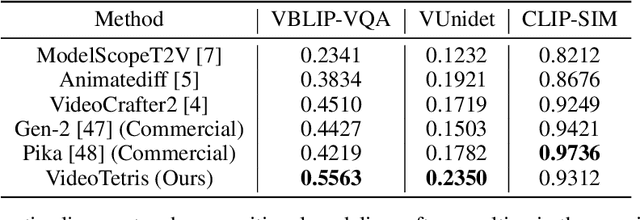
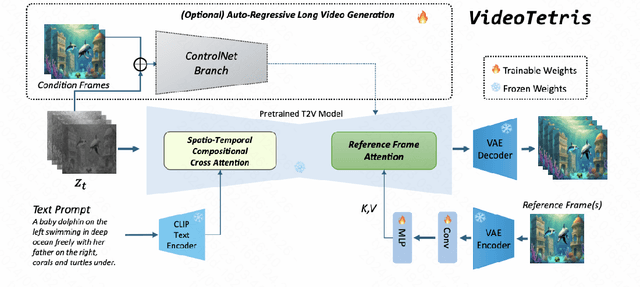

Diffusion models have demonstrated great success in text-to-video (T2V) generation. However, existing methods may face challenges when handling complex (long) video generation scenarios that involve multiple objects or dynamic changes in object numbers. To address these limitations, we propose VideoTetris, a novel framework that enables compositional T2V generation. Specifically, we propose spatio-temporal compositional diffusion to precisely follow complex textual semantics by manipulating and composing the attention maps of denoising networks spatially and temporally. Moreover, we propose an enhanced video data preprocessing to enhance the training data regarding motion dynamics and prompt understanding, equipped with a new reference frame attention mechanism to improve the consistency of auto-regressive video generation. Extensive experiments demonstrate that our VideoTetris achieves impressive qualitative and quantitative results in compositional T2V generation. Code is available at: https://github.com/YangLing0818/VideoTetris