 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElements of effective machine learning datasets in astronomy
Paper and Code
Nov 29, 2022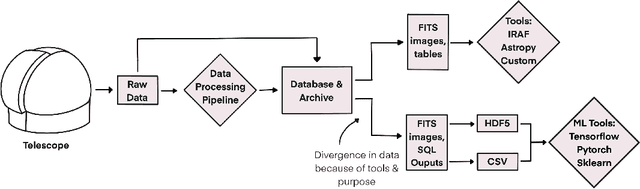
In this work, we identify elements of effective machine learning datasets in astronomy and present suggestions for their design and creation. Machine learning has become an increasingly important tool for analyzing and understanding the large-scale flood of data in astronomy. To take advantage of these tools, datasets are required for training and testing. However, building machine learning datasets for astronomy can be challenging. Astronomical data is collected from instruments built to explore science questions in a traditional fashion rather than to conduct machine learning. Thus, it is often the case that raw data, or even downstream processed data is not in a form amenable to machine learning. We explore the construction of machine learning datasets and we ask: what elements define effective machine learning datasets? We define effective machine learning datasets in astronomy to be formed with well-defined data points, structure, and metadata. We discuss why these elements are important for astronomical applications and ways to put them in practice. We posit that these qualities not only make the data suitable for machine learning, they also help to foster usable, reusable, and replicable science practices.