 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODA: Semantic-Oriented Distributional Alignment for Generative Recommendation
Feb 28, 2026Generative recommendation has emerged as a scalable alternative to traditional retrieve-and-rank pipelines by operating in a compact token space. However, existing methods mainly rely on discrete code-level supervision, which leads to information loss and limits the joint optimization between the tokenizer and the generative recommender. In this work, we propose a distribution-level supervision paradigm that leverages probability distributions over multi-layer codebooks as soft and information-rich representations. Building on this idea, we introduce Semantic-Oriented Distributional Alignment (SODA), a plug-and-play contrastive supervision framework based on Bayesian Personalized Ranking, which aligns semantically rich distributions via negative KL divergence while enabling end-to-end differentiable training. Extensive experiments on multiple real-world datasets demonstrate that SODA consistently improves the performance of various generative recommender backbones, validating its effectiveness and generality. Codes will be available upon acceptance.
UniGRec: Unified Generative Recommendation with Soft Identifiers for End-to-End Optimization
Jan 24, 2026Generative recommendation has recently emerged as a transformative paradigm that directly generates target items, surpassing traditional cascaded approaches. It typically involves two components: a tokenizer that learns item identifiers and a recommender trained on them. Existing methods often decouple tokenization from recommendation or rely on asynchronous alternating optimization, limiting full end-to-end alignment. To address this, we unify the tokenizer and recommender under the ultimate recommendation objective via differentiable soft item identifiers, enabling joint end-to-end training. However, this introduces three challenges: training-inference discrepancy due to soft-to-hard mismatch, item identifier collapse from codeword usage imbalance, and collaborative signal deficiency due to an overemphasis on fine-grained token-level semantics. To tackle these challenges, we propose UniGRec, a unified generative recommendation framework that addresses them from three perspectives. UniGRec employs Annealed Inference Alignment during tokenization to smoothly bridge soft training and hard inference, a Codeword Uniformity Regularization to prevent identifier collapse and encourage codebook diversity, and a Dual Collaborative Distillation mechanism that distills collaborative priors from a lightweight teacher model to jointly guide both the tokenizer and the recommender. Extensive experiments on real-world datasets demonstrate that UniGRec consistently outperforms state-of-the-art baseline methods. Our codes are available at https://github.com/Jialei-03/UniGRec.
UniRVQA: A Unified Framework for Retrieval-Augmented Vision Question Answering via Self-Reflective Joint Training
Apr 05, 2025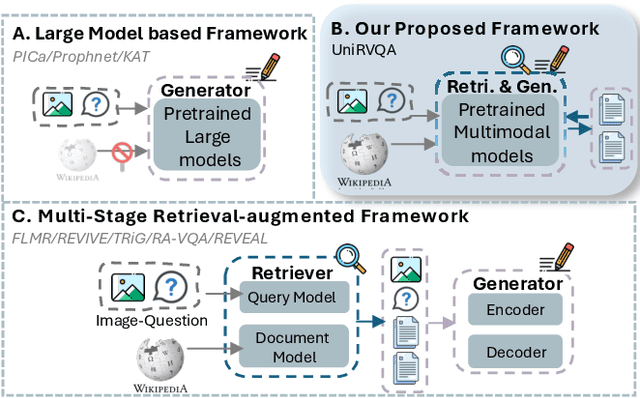
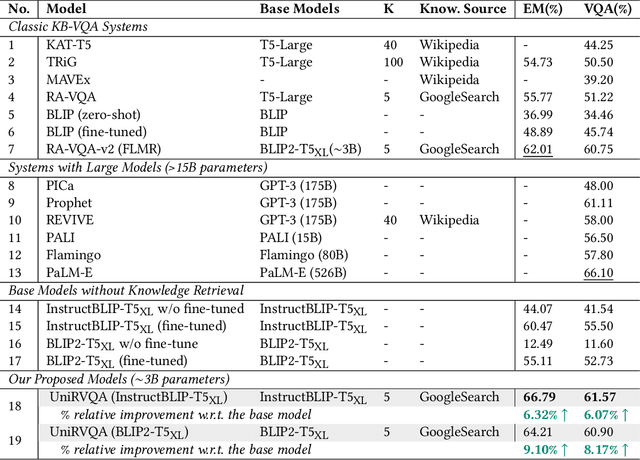
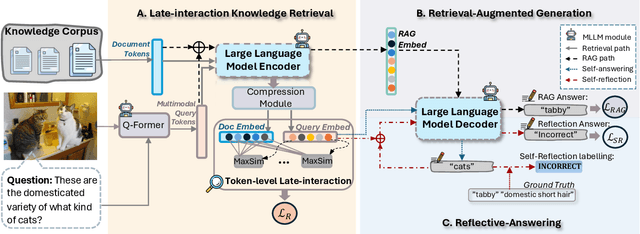
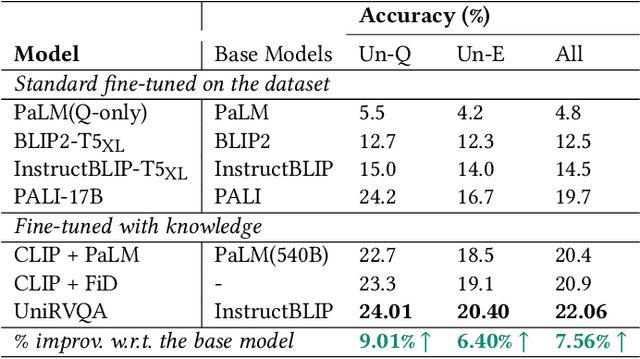
Knowledge-based Vision Question Answering (KB-VQA) systems address complex visual-grounded questions requiring external knowledge, such as web-sourced encyclopedia articles. Existing methods often use sequential and separate frameworks for the retriever and the generator with limited parametric knowledge sharing. However, since both retrieval and generation tasks require accurate understanding of contextual and external information, such separation can potentially lead to suboptimal system performance. Another key challenge is the integration of multimodal information. General-purpose multimodal pre-trained models, while adept at multimodal representation learning, struggle with fine-grained retrieval required for knowledge-intensive visual questions. Recent specialized pre-trained models mitigate the issue, but are computationally expensive. To bridge the gap, we propose a Unified Retrieval-Augmented VQA framework (UniRVQA). UniRVQA adapts general multimodal pre-trained models for fine-grained knowledge-intensive tasks within a unified framework, enabling cross-task parametric knowledge sharing and the extension of existing multimodal representation learning capability. We further introduce a reflective-answering mechanism that allows the model to explicitly evaluate and refine its knowledge boundary. Additionally, we integrate late interaction into the retrieval-augmented generation joint training process to enhance fine-grained understanding of queries and documents. Our approach achieves competitive performance against state-of-the-art models, delivering a significant 4.7% improvement in answering accuracy, and brings an average 7.5% boost in base MLLMs' VQA performance.
Let Me Do It For You: Towards LLM Empowered Recommendation via Tool Learning
May 24, 2024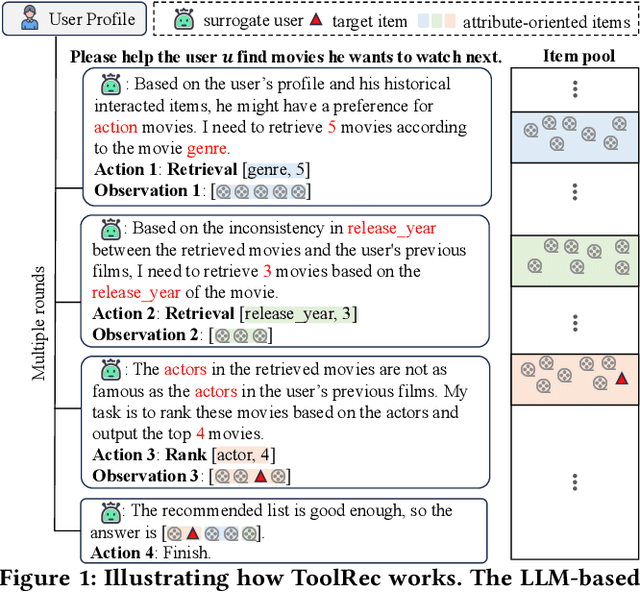
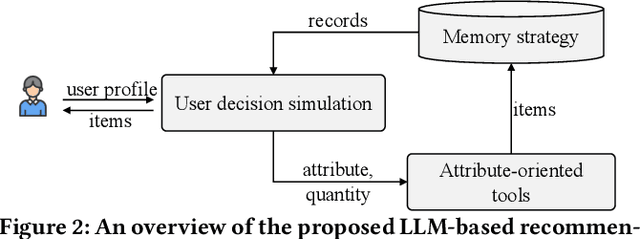
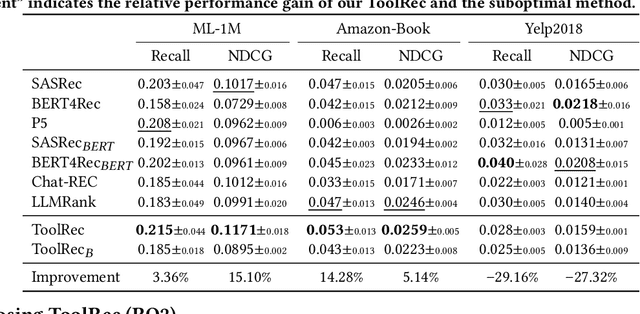
Conventional recommender systems (RSs) face challenges in precisely capturing users' fine-grained preferences. Large language models (LLMs) have shown capabilities in commonsense reasoning and leveraging external tools that may help address these challenges. However, existing LLM-based RSs suffer from hallucinations, misalignment between the semantic space of items and the behavior space of users, or overly simplistic control strategies (e.g., whether to rank or directly present existing results). To bridge these gap, we introduce ToolRec, a framework for LLM-empowered recommendations via tool learning that uses LLMs as surrogate users, thereby guiding the recommendation process and invoking external tools to generate a recommendation list that aligns closely with users' nuanced preferences. We formulate the recommendation process as a process aimed at exploring user interests in attribute granularity. The process factors in the nuances of the context and user preferences. The LLM then invokes external tools based on a user's attribute instructions and probes different segments of the item pool. We consider two types of attribute-oriented tools: rank tools and retrieval tools. Through the integration of LLMs, ToolRec enables conventional recommender systems to become external tools with a natural language interface. Extensive experiments verify the effectiveness of ToolRec, particularly in scenarios that are rich in semantic content.
Model-enhanced Contrastive Reinforcement Learning for Sequential Recommendation
Oct 25, 2023
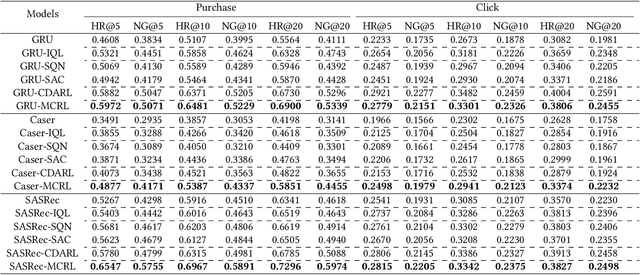
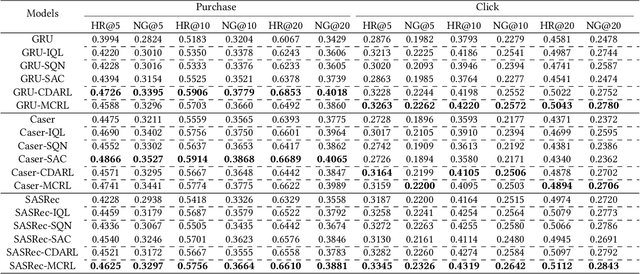
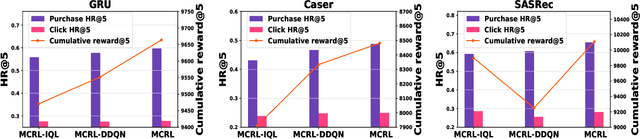
Reinforcement learning (RL) has been widely applied in recommendation systems due to its potential in optimizing the long-term engagement of users. From the perspective of RL, recommendation can be formulated as a Markov decision process (MDP), where recommendation system (agent) can interact with users (environment) and acquire feedback (reward signals).However, it is impractical to conduct online interactions with the concern on user experience and implementation complexity, and we can only train RL recommenders with offline datasets containing limited reward signals and state transitions. Therefore, the data sparsity issue of reward signals and state transitions is very severe, while it has long been overlooked by existing RL recommenders.Worse still, RL methods learn through the trial-and-error mode, but negative feedback cannot be obtained in implicit feedback recommendation tasks, which aggravates the overestimation problem of offline RL recommender. To address these challenges, we propose a novel RL recommender named model-enhanced contrastive reinforcement learning (MCRL). On the one hand, we learn a value function to estimate the long-term engagement of users, together with a conservative value learning mechanism to alleviate the overestimation problem.On the other hand, we construct some positive and negative state-action pairs to model the reward function and state transition function with contrastive learning to exploit the internal structure information of MDP. Experiments demonstrate that the proposed method significantly outperforms existing offline RL and self-supervised RL methods with different representative backbone networks on two real-world datasets.
LLaMA-E: Empowering E-commerce Authoring with Multi-Aspect Instruction Following
Aug 09, 2023E-commerce authoring involves creating attractive, abundant, and targeted promotional content to drive product sales. The emergence of large language models (LLMs) introduces an innovative paradigm, offering a unified solution to address various authoring tasks within this scenario. However, mainstream LLMs trained on general corpora with common sense knowledge reveal limitations in fitting complex and personalized features unique to e-commerce products and customers. Furthermore, LLMs like GPT-3.5 necessitate remote accessibility, raising concerns about safeguarding voluminous customer privacy data during transmission. This paper proposes the LLaMA-E, the unified and customized instruction-following language models focusing on diverse e-commerce authoring tasks. Specifically, the domain experts create the seed instruction set from the tasks of ads generation, query-enhanced product title rewriting, product classification, purchase intent speculation, and general Q&A. These tasks enable the models to comprehensively understand precise e-commerce authoring knowledge by interleaving features covering typical service aspects of customers, sellers, and platforms. The GPT-3.5 is introduced as a teacher model, which expands the seed instructions to form a training set for the LLaMA-E models with various scales. The experimental results show that the proposed LLaMA-E models achieve state-of-the-art results in quantitative and qualitative evaluations, also exhibiting the advantage in zero-shot scenes. To the best of our knowledge, this study is the first to serve the LLMs to specific e-commerce authoring scenarios.
Reformulating CTR Prediction: Learning Invariant Feature Interactions for Recommendation
Apr 26, 2023Click-Through Rate (CTR) prediction plays a core role in recommender systems, serving as the final-stage filter to rank items for a user. The key to addressing the CTR task is learning feature interactions that are useful for prediction, which is typically achieved by fitting historical click data with the Empirical Risk Minimization (ERM) paradigm. Representative methods include Factorization Machines and Deep Interest Network, which have achieved wide success in industrial applications. However, such a manner inevitably learns unstable feature interactions, i.e., the ones that exhibit strong correlations in historical data but generalize poorly for future serving. In this work, we reformulate the CTR task -- instead of pursuing ERM on historical data, we split the historical data chronologically into several periods (a.k.a, environments), aiming to learn feature interactions that are stable across periods. Such feature interactions are supposed to generalize better to predict future behavior data. Nevertheless, a technical challenge is that existing invariant learning solutions like Invariant Risk Minimization are not applicable, since the click data entangles both environment-invariant and environment-specific correlations. To address this dilemma, we propose Disentangled Invariant Learning (DIL) which disentangles feature embeddings to capture the two types of correlations separately. To improve the modeling efficiency, we further design LightDIL which performs the disentanglement at the higher level of the feature field. Extensive experiments demonstrate the effectiveness of DIL in learning stable feature interactions for CTR. We release the code at https://github.com/zyang1580/DIL.
Fairness-aware Differentially Private Collaborative Filtering
Mar 16, 2023Recently, there has been an increasing adoption of differential privacy guided algorithms for privacy-preserving machine learning tasks. However, the use of such algorithms comes with trade-offs in terms of algorithmic fairness, which has been widely acknowledged. Specifically, we have empirically observed that the classical collaborative filtering method, trained by differentially private stochastic gradient descent (DP-SGD), results in a disparate impact on user groups with respect to different user engagement levels. This, in turn, causes the original unfair model to become even more biased against inactive users. To address the above issues, we propose \textbf{DP-Fair}, a two-stage framework for collaborative filtering based algorithms. Specifically, it combines differential privacy mechanisms with fairness constraints to protect user privacy while ensuring fair recommendations. The experimental results, based on Amazon datasets, and user history logs collected from Etsy, one of the largest e-commerce platforms, demonstrate that our proposed method exhibits superior performance in terms of both overall accuracy and user group fairness on both shallow and deep recommendation models compared to vanilla DP-SGD.
Transferable Fairness for Cold-Start Recommendation
Jan 25, 2023



With the increasing use and impact of recommender systems in our daily lives, how to achieve fairness in recommendation has become an important problem. Previous works on fairness-aware recommendation mainly focus on a predefined set of (usually warm-start) users. However, recommender systems often face more challenging fairness issues for new users or cold-start users due to their insufficient amount of interactions. Therefore, it is essential to study whether the trained model still performs fairly for a new set of cold-start users. This paper considers the scenario where the recommender system meets new users who only have limited or even no interaction with the platform, and aims at providing high-quality and fair recommendations to such users effectively. The sufficient interaction data from warm users is treated as the source user domain, while the data from new users is treated as the target user domain, and we consider to transfer the counterfactual fairness from the source users to the target users. To this end, we introduce a framework to achieve transferable counterfactual fairness in recommendation. The proposed method is able to transfer the knowledge of a fair model learned from the source users to the target users with the hope of improving the recommendation performance and keeping the fairness property on the target users. Experiments on two real-world datasets with representative recommendation algorithms show that our method not only promotes fairness for the target users, but also outperforms comparative models in terms of recommendation performance.
Causal Inference for Knowledge Graph based Recommendation
Dec 20, 2022



Knowledge Graph (KG), as a side-information, tends to be utilized to supplement the collaborative filtering (CF) based recommendation model. By mapping items with the entities in KGs, prior studies mostly extract the knowledge information from the KGs and inject it into the representations of users and items. Despite their remarkable performance, they fail to model the user preference on attributes in the KG, since they ignore that (1) the structure information of KG may hinder the user preference learning, and (2) the user's interacted attributes will result in the bias issue on the similarity scores. With the help of causality tools, we construct the causal-effect relation between the variables in KG-based recommendation and identify the reasons causing the mentioned challenges. Accordingly, we develop a new framework, termed Knowledge Graph-based Causal Recommendation (KGCR), which implements the deconfounded user preference learning and adopts counterfactual inference to eliminate bias in the similarity scoring. Ultimately, we evaluate our proposed model on three datasets, including Amazon-book, LastFM, and Yelp2018 datasets. By conducting extensive experiments on the datasets, we demonstrate that KGCR outperforms several state-of-the-art baselines, such as KGNN-LS, KGAT and KGIN.