 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMA-E: Empowering E-commerce Authoring with Multi-Aspect Instruction Following
Aug 09, 2023E-commerce authoring involves creating attractive, abundant, and targeted promotional content to drive product sales. The emergence of large language models (LLMs) introduces an innovative paradigm, offering a unified solution to address various authoring tasks within this scenario. However, mainstream LLMs trained on general corpora with common sense knowledge reveal limitations in fitting complex and personalized features unique to e-commerce products and customers. Furthermore, LLMs like GPT-3.5 necessitate remote accessibility, raising concerns about safeguarding voluminous customer privacy data during transmission. This paper proposes the LLaMA-E, the unified and customized instruction-following language models focusing on diverse e-commerce authoring tasks. Specifically, the domain experts create the seed instruction set from the tasks of ads generation, query-enhanced product title rewriting, product classification, purchase intent speculation, and general Q&A. These tasks enable the models to comprehensively understand precise e-commerce authoring knowledge by interleaving features covering typical service aspects of customers, sellers, and platforms. The GPT-3.5 is introduced as a teacher model, which expands the seed instructions to form a training set for the LLaMA-E models with various scales. The experimental results show that the proposed LLaMA-E models achieve state-of-the-art results in quantitative and qualitative evaluations, also exhibiting the advantage in zero-shot scenes. To the best of our knowledge, this study is the first to serve the LLMs to specific e-commerce authoring scenarios.
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022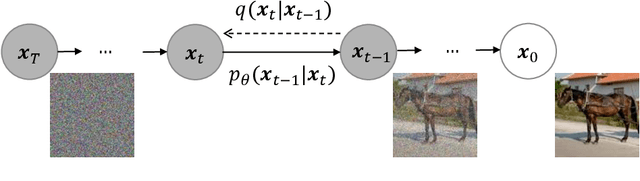
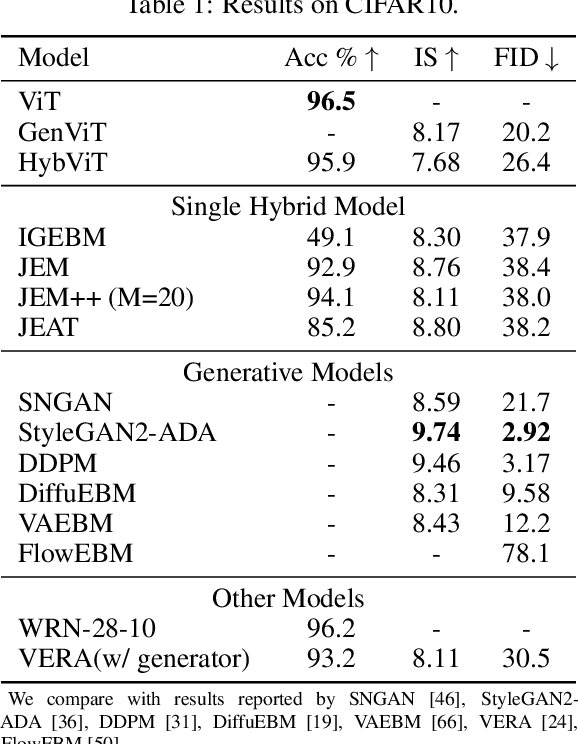
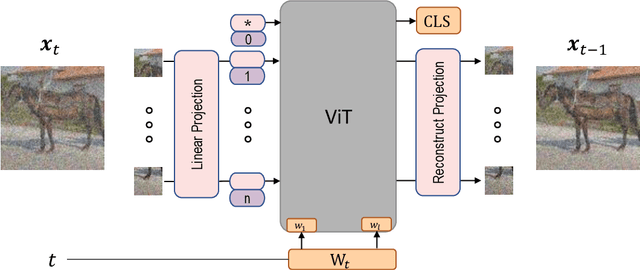
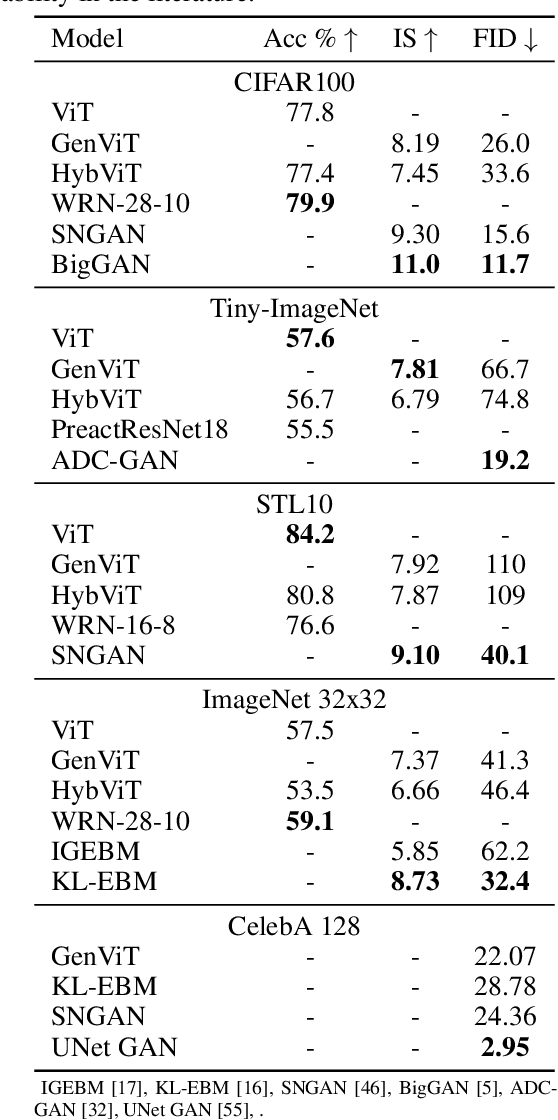
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .