 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-enhanced Contrastive Reinforcement Learning for Sequential Recommendation
Paper and Code
Oct 25, 2023
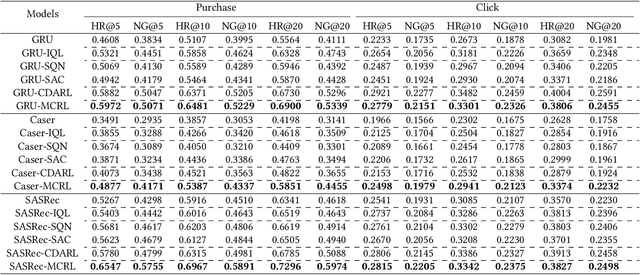
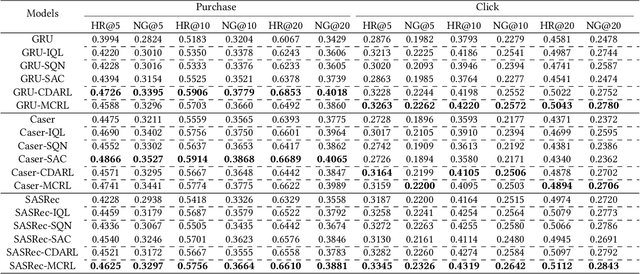
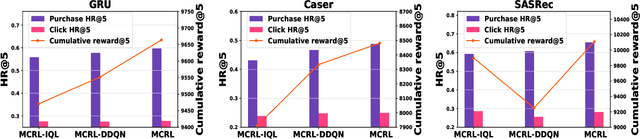
Reinforcement learning (RL) has been widely applied in recommendation systems due to its potential in optimizing the long-term engagement of users. From the perspective of RL, recommendation can be formulated as a Markov decision process (MDP), where recommendation system (agent) can interact with users (environment) and acquire feedback (reward signals).However, it is impractical to conduct online interactions with the concern on user experience and implementation complexity, and we can only train RL recommenders with offline datasets containing limited reward signals and state transitions. Therefore, the data sparsity issue of reward signals and state transitions is very severe, while it has long been overlooked by existing RL recommenders.Worse still, RL methods learn through the trial-and-error mode, but negative feedback cannot be obtained in implicit feedback recommendation tasks, which aggravates the overestimation problem of offline RL recommender. To address these challenges, we propose a novel RL recommender named model-enhanced contrastive reinforcement learning (MCRL). On the one hand, we learn a value function to estimate the long-term engagement of users, together with a conservative value learning mechanism to alleviate the overestimation problem.On the other hand, we construct some positive and negative state-action pairs to model the reward function and state transition function with contrastive learning to exploit the internal structure information of MDP. Experiments demonstrate that the proposed method significantly outperforms existing offline RL and self-supervised RL methods with different representative backbone networks on two real-world datasets.