 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarathon: A Race Through the Realm of Long Context with Large Language Models
Paper and Code

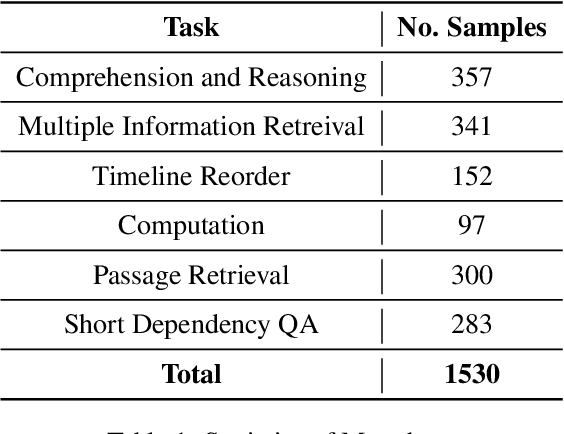


Although there are currently many benchmarks available for evaluating the long context understanding and reasoning capability of large language models, with the expansion of the context window in these models, the existing long context benchmarks are no longer sufficient for evaluating the long context understanding and reasoning capability of large language models. In this paper, we have developed a fresh long context evaluation benchmark, which we name it Marathon in the form of multiple choice questions, inspired by benchmarks such as MMLU, for assessing the long context comprehension capability of large language models quickly, accurately, and objectively. We have evaluated several of the latest and most popular large language models, as well as three recent and effective long context optimization methods, on our benchmark. This showcases the long context reasoning and comprehension capabilities of these large language models and validates the effectiveness of these optimization methods. Marathon is available at https://huggingface.co/datasets/Lemoncoke/Marathon.