 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiKonv: Maximizing the Throughput of Quantized Convolution With Novel Bit-wise Management and Computation
Jul 22, 2022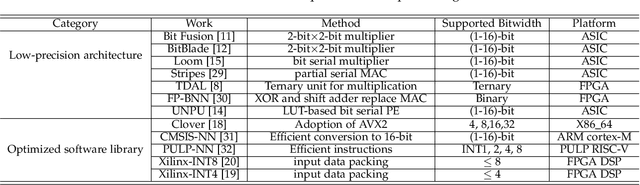
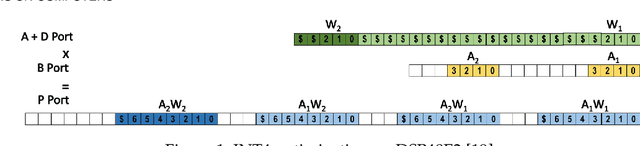
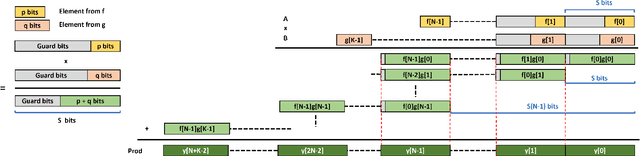
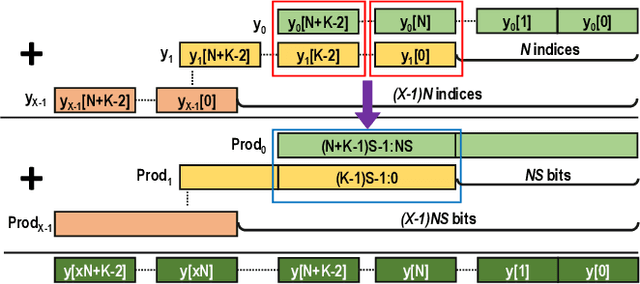
Quantization for CNN has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data representations. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as ALU in CPUs and DSP in FPGAs, can be better utilized to deliver significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the throughput of convolution on a given underlying processing unit with low-bitwidth quantized data inputs through novel bit-wise management and parallel computation. We establish theoretical framework and performance models using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit in CPU can deliver 128 binarized convolution operations (multiplications and additions) and 13 4-bit convolution operations with a single multiplication instruction, and a single 27x18 multiplier in the FPGA DSP can deliver 60, 8 or 2 convolution operations with 1, 4 or 8-bit inputs in one clock cycle. We demonstrate the effectiveness of HiKonv on both CPU and FPGA. On CPU, HiKonv outperforms the baseline implementation with 1 to 8-bit inputs and provides up to 7.6x and 1.4x performance improvements for 1-D convolution, and performs 2.74x and 3.19x over the baseline implementation for 4-bit signed and unsigned data inputs for 2-D convolution. On FPGA, HiKonv solution enables a single DSP to process multiple convolutions with a shorter processing latency. For binarized input, each DSP with HiKonv is equivalent up to 76.6 LUTs. Compared to the DAC-SDC 2020 champion model, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
HiKonv: High Throughput Quantized Convolution With Novel Bit-wise Management and Computation
Dec 28, 2021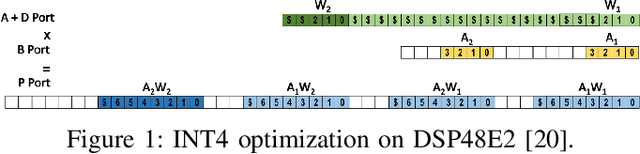
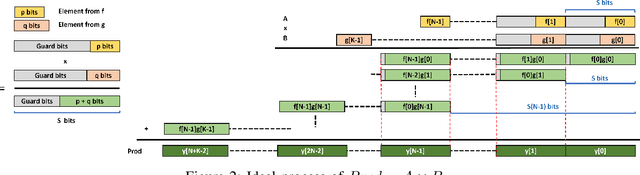

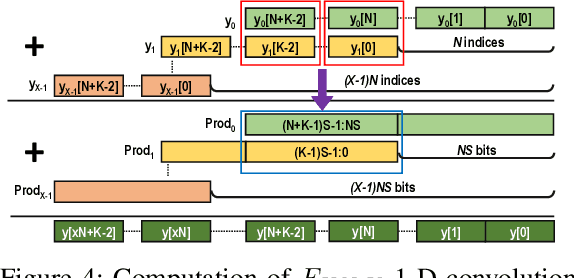
Quantization for Convolutional Neural Network (CNN) has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data inputs. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as CPUs and DSPs, can be better utilized to carry out significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the compute throughput of a given underlying processing unit to process low-bitwidth quantized data inputs through novel bit-wise parallel computation. We establish theoretical performance bounds using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit can deliver 128 binarized convolution operations (multiplications and additions) under one CPU instruction, and a single 27x18 DSP core can deliver eight convolution operations with 4-bit inputs in one cycle. We demonstrate the effectiveness of HiKonv on CPU and FPGA for both convolutional layers or a complete DNN model. For a convolutional layer quantized to 4-bit, HiKonv achieves a 3.17x latency improvement over the baseline implementation using C++ on CPU. Compared to the DAC-SDC 2020 champion model for FPGA, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
WinoCNN: Kernel Sharing Winograd Systolic Array for Efficient Convolutional Neural Network Acceleration on FPGAs
Jul 09, 2021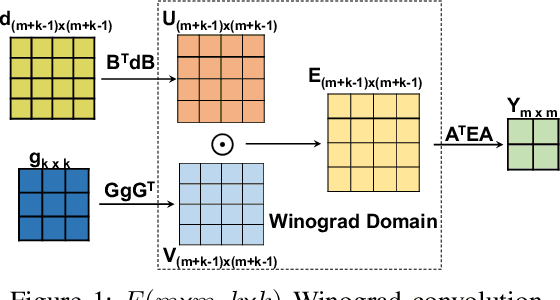
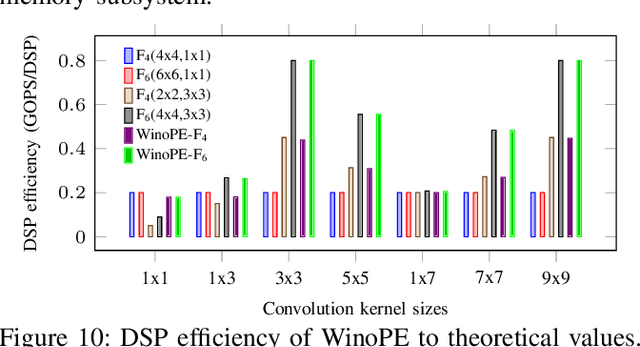
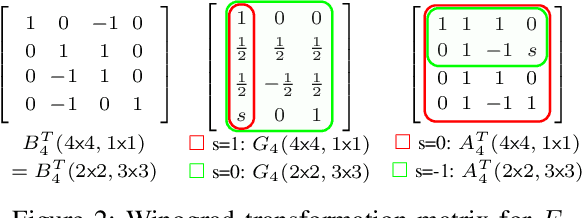
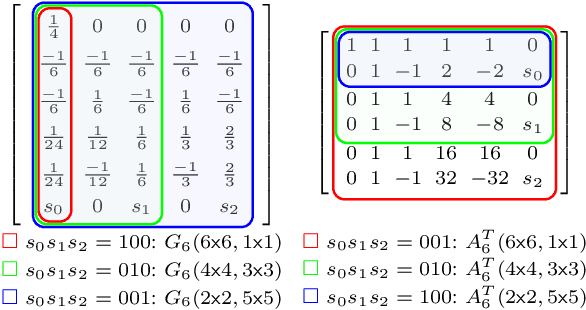
The combination of Winograd's algorithm and systolic array architecture has demonstrated the capability of improving DSP efficiency in accelerating convolutional neural networks (CNNs) on FPGA platforms. However, handling arbitrary convolution kernel sizes in FPGA-based Winograd processing elements and supporting efficient data access remain underexplored. In this work, we are the first to propose an optimized Winograd processing element (WinoPE), which can naturally support multiple convolution kernel sizes with the same amount of computing resources and maintains high runtime DSP efficiency. Using the proposed WinoPE, we construct a highly efficient systolic array accelerator, termed WinoCNN. We also propose a dedicated memory subsystem to optimize the data access. Based on the accelerator architecture, we build accurate resource and performance modeling to explore optimal accelerator configurations under different resource constraints. We implement our proposed accelerator on multiple FPGAs, which outperforms the state-of-the-art designs in terms of both throughput and DSP efficiency. Our implementation achieves DSP efficiency up to 1.33 GOPS/DSP and throughput up to 3.1 TOPS with the Xilinx ZCU102 FPGA. These are 29.1\% and 20.0\% better than the best solutions reported previously, respectively.
FracBNN: Accurate and FPGA-Efficient Binary Neural Networks with Fractional Activations
Dec 22, 2020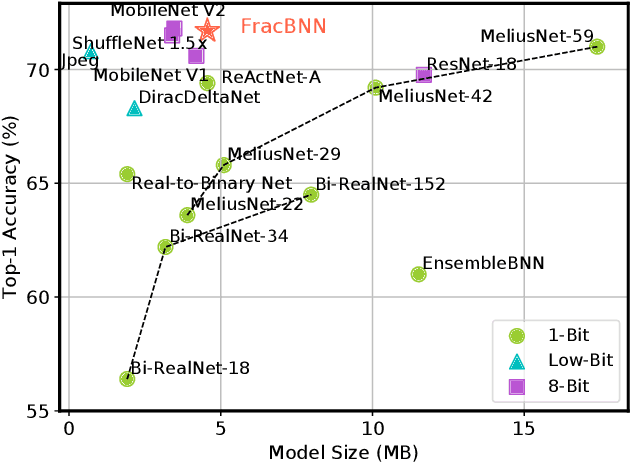

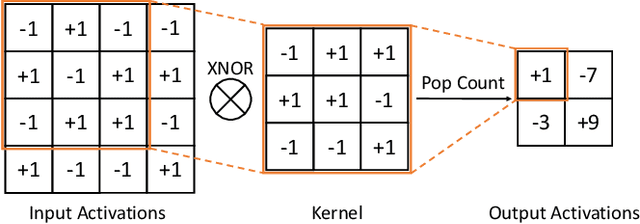
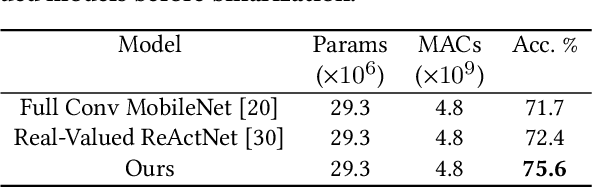
Binary neural networks (BNNs) have 1-bit weights and activations. Such networks are well suited for FPGAs, as their dominant computations are bitwise arithmetic and the memory requirement is also significantly reduced. However, compared to start-of-the-art compact convolutional neural network (CNN) models, BNNs tend to produce a much lower accuracy on realistic datasets such as ImageNet. In addition, the input layer of BNNs has gradually become a major compute bottleneck, because it is conventionally excluded from binarization to avoid a large accuracy loss. This work proposes FracBNN, which exploits fractional activations to substantially improve the accuracy of BNNs. Specifically, our approach employs a dual-precision activation scheme to compute features with up to two bits, using an additional sparse binary convolution. We further binarize the input layer using a novel thermometer encoding. Overall, FracBNN preserves the key benefits of conventional BNNs, where all convolutional layers are computed in pure binary MAC operations (BMACs). We design an efficient FPGA-based accelerator for our novel BNN model that supports the fractional activations. To evaluate the performance of FracBNN under a resource-constrained scenario, we implement the entire optimized network architecture on an embedded FPGA (Xilinx Ultra96v2). Our experiments on ImageNet show that FracBNN achieves an accuracy comparable to MobileNetV2, surpassing the best-known BNN design on FPGAs with an increase of 28.9% in top-1 accuracy and a 2.5x reduction in model size. FracBNN also outperforms a recently introduced BNN model with an increase of 2.4% in top-1 accuracy while using the same model size. On the embedded FPGA device, FracBNN demonstrates the ability of real-time image classification.
EDD: Efficient Differentiable DNN Architecture and Implementation Co-search for Embedded AI Solutions
May 06, 2020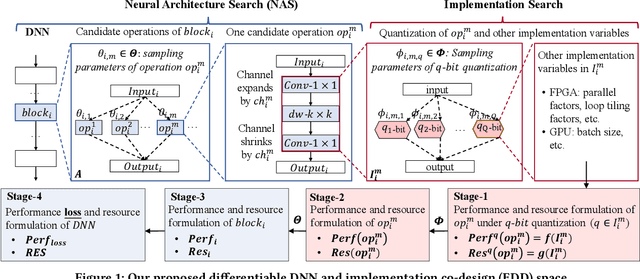
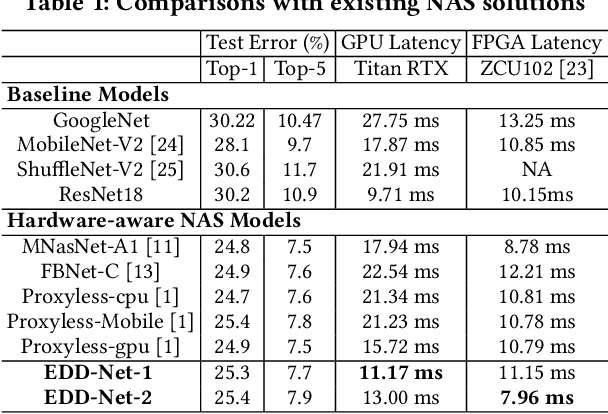
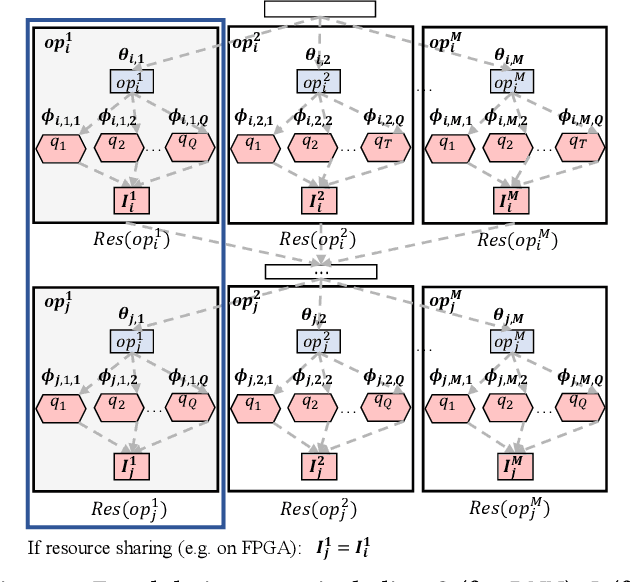
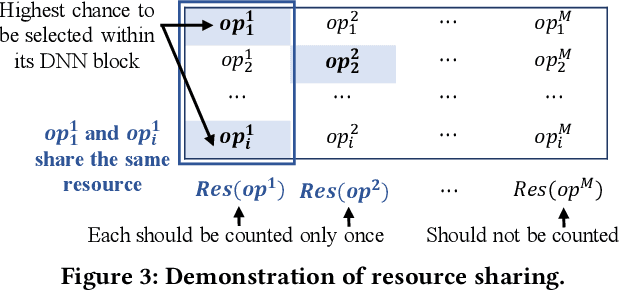
High quality AI solutions require joint optimization of AI algorithms and their hardware implementations. In this work, we are the first to propose a fully simultaneous, efficient differentiable DNN architecture and implementation co-search (EDD) methodology. We formulate the co-search problem by fusing DNN search variables and hardware implementation variables into one solution space, and maximize both algorithm accuracy and hardware implementation quality. The formulation is differentiable with respect to the fused variables, so that gradient descent algorithm can be applied to greatly reduce the search time. The formulation is also applicable for various devices with different objectives. In the experiments, we demonstrate the effectiveness of our EDD methodology by searching for three representative DNNs, targeting low-latency GPU implementation and FPGA implementations with both recursive and pipelined architectures. Each model produced by EDD achieves similar accuracy as the best existing DNN models searched by neural architecture search (NAS) methods on ImageNet, but with superior performance obtained within 12 GPU-hour searches. Our DNN targeting GPU is 1.40x faster than the state-of-the-art solution reported in Proxyless, and our DNN targeting FPGA delivers 1.45x higher throughput than the state-of-the-art solution reported in DNNBuilder.
NAIS: Neural Architecture and Implementation Search and its Applications in Autonomous Driving
Nov 18, 2019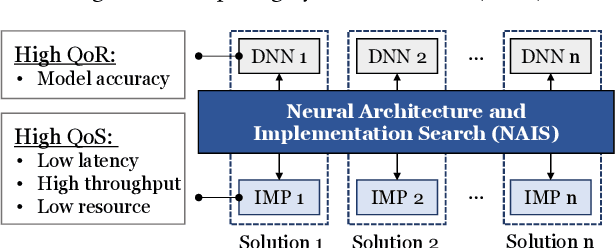

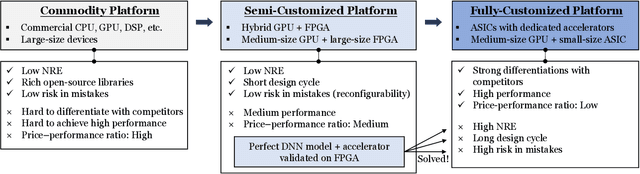

The rapidly growing demands for powerful AI algorithms in many application domains have motivated massive investment in both high-quality deep neural network (DNN) models and high-efficiency implementations. In this position paper, we argue that a simultaneous DNN/implementation co-design methodology, named Neural Architecture and Implementation Search (NAIS), deserves more research attention to boost the development productivity and efficiency of both DNN models and implementation optimization. We propose a stylized design methodology that can drastically cut down the search cost while preserving the quality of the end solution.As an illustration, we discuss this DNN/implementation methodology in the context of both FPGAs and GPUs. We take autonomous driving as a key use case as it is one of the most demanding areas for high quality AI algorithms and accelerators. We discuss how such a co-design methodology can impact the autonomous driving industry significantly. We identify several research opportunities in this exciting domain.
Face Recognition with Hybrid Efficient Convolution Algorithms on FPGAs
Mar 23, 2018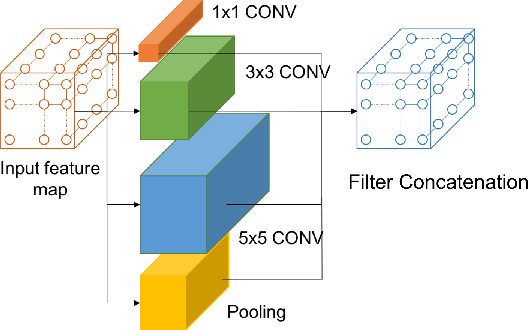
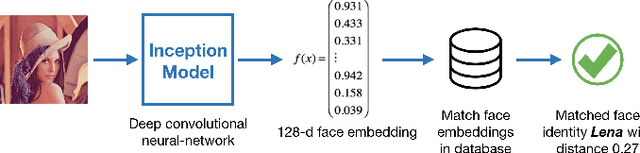
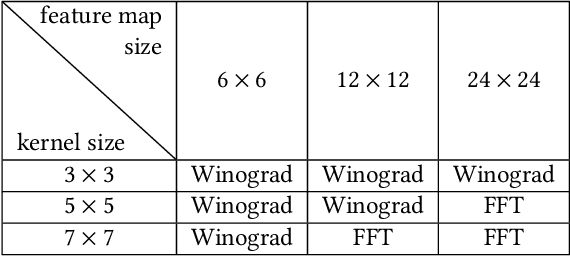
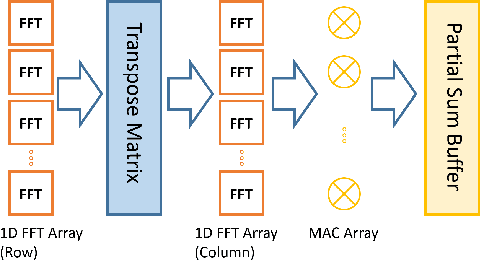
Deep Convolutional Neural Networks have become a Swiss knife in solving critical artificial intelligence tasks. However, deploying deep CNN models for latency-critical tasks remains to be challenging because of the complex nature of CNNs. Recently, FPGA has become a favorable device to accelerate deep CNNs thanks to its high parallel processing capability and energy efficiency. In this work, we explore different fast convolution algorithms including Winograd and Fast Fourier Transform (FFT), and find an optimal strategy to apply them together on different types of convolutions. We also propose an optimization scheme to exploit parallelism on novel CNN architectures such as Inception modules in GoogLeNet. We implement a configurable IP-based face recognition acceleration system based on FaceNet using High-Level Synthesis. Our implementation on a Xilinx Ultrascale device achieves 3.75x latency speedup compared to a high-end NVIDIA GPU and surpasses previous FPGA results significantly.