 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDD: Efficient Differentiable DNN Architecture and Implementation Co-search for Embedded AI Solutions
Paper and Code
May 06, 2020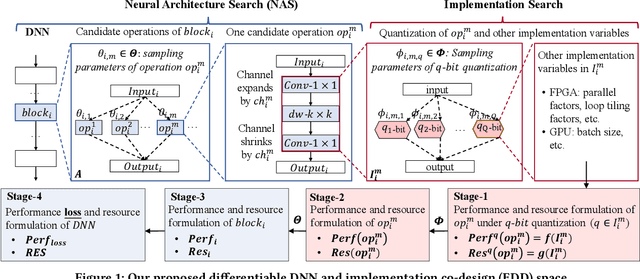
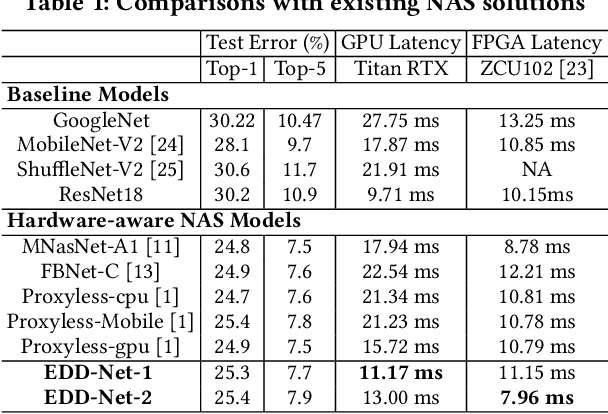
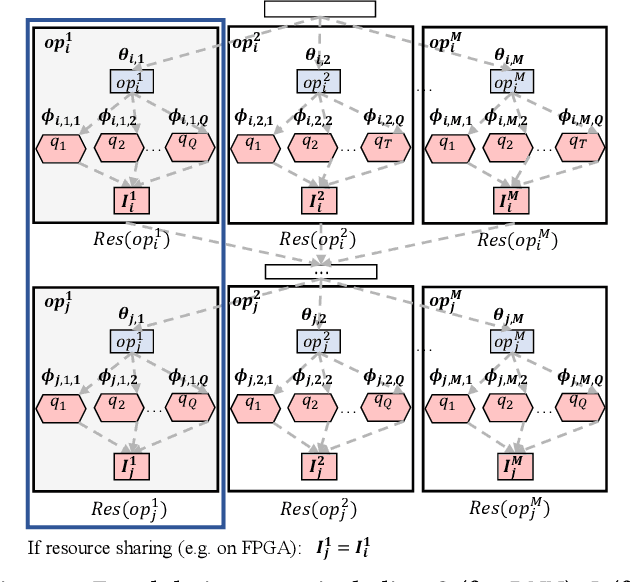
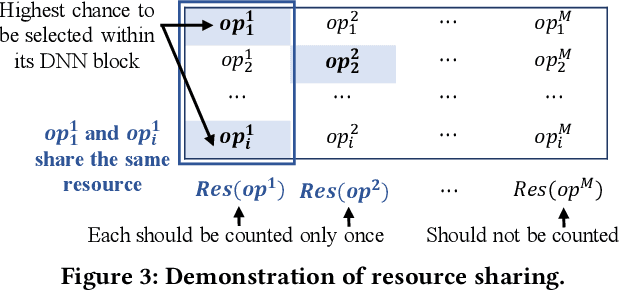
High quality AI solutions require joint optimization of AI algorithms and their hardware implementations. In this work, we are the first to propose a fully simultaneous, efficient differentiable DNN architecture and implementation co-search (EDD) methodology. We formulate the co-search problem by fusing DNN search variables and hardware implementation variables into one solution space, and maximize both algorithm accuracy and hardware implementation quality. The formulation is differentiable with respect to the fused variables, so that gradient descent algorithm can be applied to greatly reduce the search time. The formulation is also applicable for various devices with different objectives. In the experiments, we demonstrate the effectiveness of our EDD methodology by searching for three representative DNNs, targeting low-latency GPU implementation and FPGA implementations with both recursive and pipelined architectures. Each model produced by EDD achieves similar accuracy as the best existing DNN models searched by neural architecture search (NAS) methods on ImageNet, but with superior performance obtained within 12 GPU-hour searches. Our DNN targeting GPU is 1.40x faster than the state-of-the-art solution reported in Proxyless, and our DNN targeting FPGA delivers 1.45x higher throughput than the state-of-the-art solution reported in DNNBuilder.