 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinoCNN: Kernel Sharing Winograd Systolic Array for Efficient Convolutional Neural Network Acceleration on FPGAs
Paper and Code
Jul 09, 2021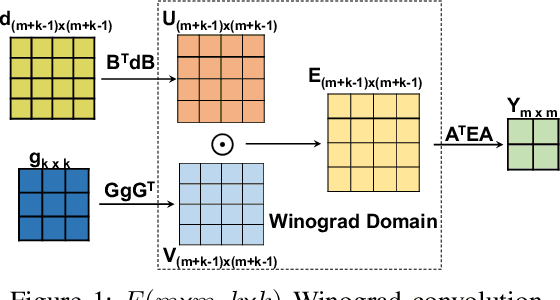
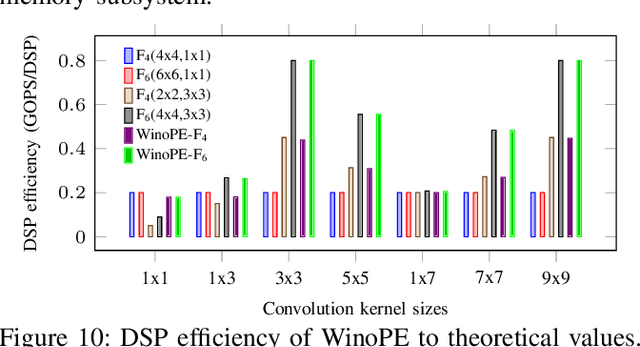
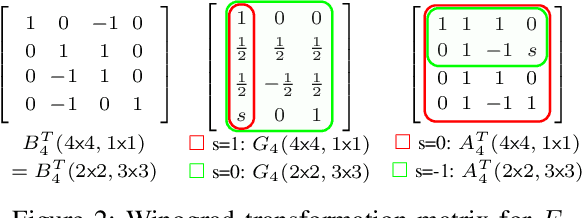
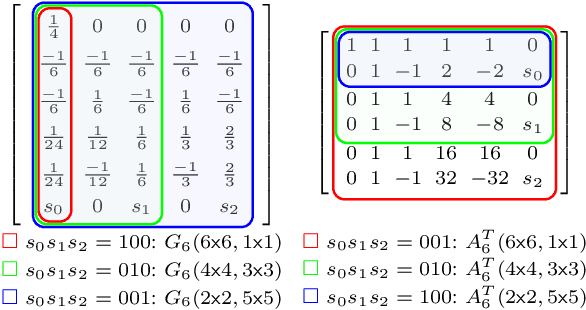
The combination of Winograd's algorithm and systolic array architecture has demonstrated the capability of improving DSP efficiency in accelerating convolutional neural networks (CNNs) on FPGA platforms. However, handling arbitrary convolution kernel sizes in FPGA-based Winograd processing elements and supporting efficient data access remain underexplored. In this work, we are the first to propose an optimized Winograd processing element (WinoPE), which can naturally support multiple convolution kernel sizes with the same amount of computing resources and maintains high runtime DSP efficiency. Using the proposed WinoPE, we construct a highly efficient systolic array accelerator, termed WinoCNN. We also propose a dedicated memory subsystem to optimize the data access. Based on the accelerator architecture, we build accurate resource and performance modeling to explore optimal accelerator configurations under different resource constraints. We implement our proposed accelerator on multiple FPGAs, which outperforms the state-of-the-art designs in terms of both throughput and DSP efficiency. Our implementation achieves DSP efficiency up to 1.33 GOPS/DSP and throughput up to 3.1 TOPS with the Xilinx ZCU102 FPGA. These are 29.1\% and 20.0\% better than the best solutions reported previously, respectively.