 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Face Recognition with Hybrid Efficient Convolution Algorithms on FPGAs
Mar 23, 2018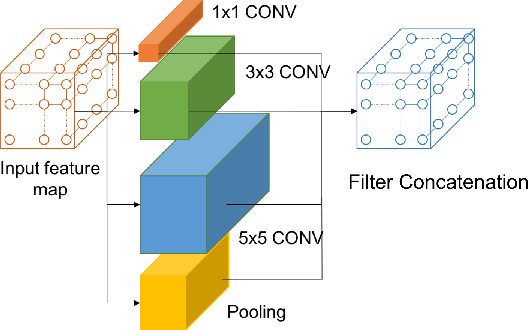
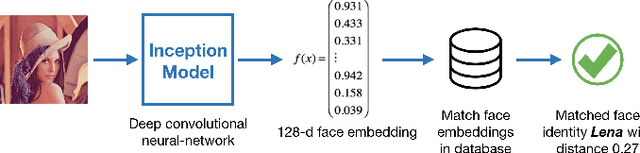
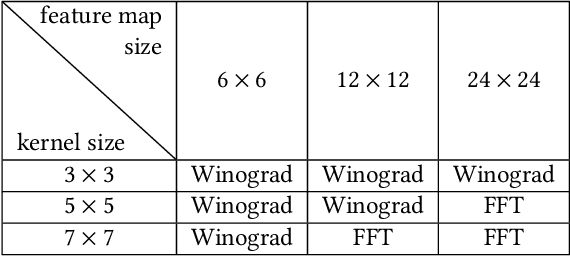
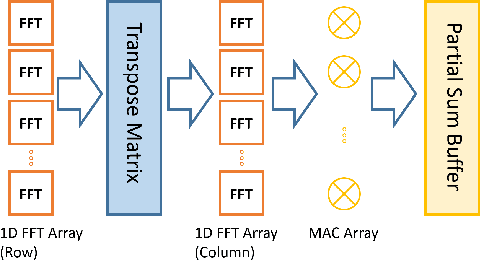
Deep Convolutional Neural Networks have become a Swiss knife in solving critical artificial intelligence tasks. However, deploying deep CNN models for latency-critical tasks remains to be challenging because of the complex nature of CNNs. Recently, FPGA has become a favorable device to accelerate deep CNNs thanks to its high parallel processing capability and energy efficiency. In this work, we explore different fast convolution algorithms including Winograd and Fast Fourier Transform (FFT), and find an optimal strategy to apply them together on different types of convolutions. We also propose an optimization scheme to exploit parallelism on novel CNN architectures such as Inception modules in GoogLeNet. We implement a configurable IP-based face recognition acceleration system based on FaceNet using High-Level Synthesis. Our implementation on a Xilinx Ultrascale device achieves 3.75x latency speedup compared to a high-end NVIDIA GPU and surpasses previous FPGA results significantly.