 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermark Smoothing Attacks against Language Models
Paper and Code
Jul 19, 2024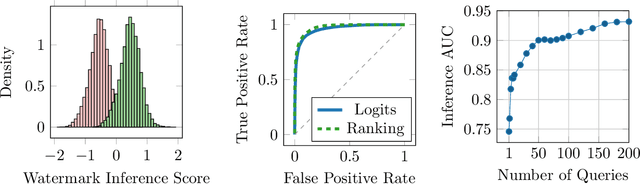

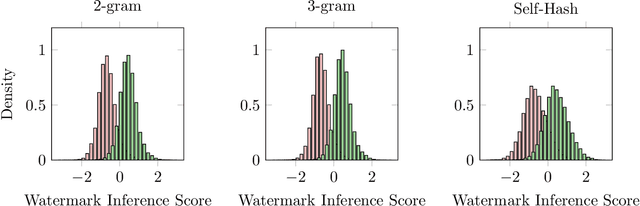

Watermarking is a technique used to embed a hidden signal in the probability distribution of text generated by large language models (LLMs), enabling attribution of the text to the originating model. We introduce smoothing attacks and show that existing watermarking methods are not robust against minor modifications of text. An adversary can use weaker language models to smooth out the distribution perturbations caused by watermarks without significantly compromising the quality of the generated text. The modified text resulting from the smoothing attack remains close to the distribution of text that the original model (without watermark) would have produced. Our attack reveals a fundamental limitation of a wide range of watermarking techniques.